


Spark Streaming Partie 2 : traitement d'une pipeline Spark Structured Streaming dans Hadoop

28 mai 2019
- Catégories
- Data Engineering
- Formation
- Tags
- Apache Spark Streaming
- Spark
- Python
- Streaming [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Spark est conçu pour traiter des données streaming de manière fluide sur un cluster Hadoop multi-nœuds, utilisant HDFS pour le stockage et YARN pour l’orchestration de tâches. Ainsi, Spark Structured Streaming s’intègre bien dans une infrastructure Big Data. Une chaîne de traitement des données streaming sera présentée, cette fois dans un environnement distribué.
Ceci est le deuxième article d’une série en quatre parties.
- Dans la première partie, un pipeline de données est créé en Python avec Spark Structured Streaming.
- La deuxième partie concerne la migration du pipeline vers un cluster Hadoop.
- Dans la troisième partie, l’application PySpark a été portée et testée dans un environnement Scala Spark et des test unitaires ont été ajoutés.
- La quatrième et dernière partie enrichie le pipeline de données avec un algorithme du regroupement par apprentissage automatique.
Comme précédemment, les données de Taxi new-yorkais (tirées d’Apache Flink Training) seront utilisées. Le cas d’usage reste le même – définir les quartiers les rentables pour les conducteurs en terme de pourboire. Le code complet de la section précédente est téléchargeable ici.
Spécification du cluster Hadoop
Spark peut être configuré pour utiliser le gestionnaire de tâches Hadoop YARN. Les clusters Hadoop sont des environnements d’éxécution répandus dans bon nombre d’entreprises utilisant des technologies Big Data. Dans cet article, un “petit” cluster sera utilisé avec les charactéristiques suivantes :
- Un cluster Hadoop HDP 3.1.0 installé grâce à Apache Abari 2.7.3
- Hadoop déployé en local sur un système de 4 Vms grâce à un ordinateur portable ayant 32GB de RAM et 8 coeurs.
- Les machines virtuelles ont respectivement 5,6,7,7 GB de RAM et 1,1,3,2 coeurs. Leurs systèmes d’exploitation est CentOS.
- L’hôte
master01.clustergère les outils : Ambari Server, Zookeeper, YARN, HDFS, Hive, Tez. - L’hôte
master02.cluster: Spark2 (Spark2 History Server) et Kafka (Kafka Broker). - Les hôtes
worker01.clusteret worker02.cluster sont des noeuds de calcul. - Les clés SSH pour les root ont été mis en place, i.e. les utilisateurs root de chaque hôte ont des clés appropriés dans
/root/.ssh. - Chaque hôte a Python3 installé en parallèle de Python2. Avec Python3 désigné pour être utilisé par PySpark (en définissant la variable d’environnement
PYSPARK_PYTHONde Spark). - Les contenaires YARN ont été alloués avec une mémoire allant de 512MB à 6144MB.
- Le serveur Zookeeper est reglé sur
master02.cluster:2181et le broker Kafka surmaster02.cluster:6667. - La sortie du Driver Spark a tendance à être riche en logs de type
INFO, ce qui ajoute de l’encombrement dans la console. Dans “Advanced spark2-log4j-properties”, on peut changerINFOpourWARNdans “log4j.rootCategory” pour alléger la sortie Spark. En cas d’erreur, il est préférable de revenir au typeINFO.
Il est également utile de noter que :
- Il est requis d’utiliser au minimum la version HDP 2.6.5 ou CDH 6.1.0 : les jointures stream-stream ne sont supporté que depuis la version Spark 2.3. En fait, Spark Structured Streaming est supporté depuis la version Spark 2.2 mais une version plus récente de Spark permet de réaliser les jointures citées plus haut qui sont utilisées dans cet article.
- Kafka 0.10.0 ou plus est requis pour l’intégration de Kafka avec Spark Structured Streaming.
- Dans HDP 3.1.0, Spark 2.3.X et Kafka 2.X sont disponibles par défaut
Un cluster conforme aux spécifications ci-dessus a été déployé sur des machines virtuelles gérées avec Vagrant. Chaque système d’exploitation a un environnement préparé pour Ambari avec un Vagrantfile et les fichiers bootstrap du shell ont été provisionnés. L’installation des composants a été réalisée grâce à Ambari. Un projet Open Source interne à Adaltas appelé Jumbo pourrait être utile dans un proche avenir. Pour l’instant, il permet de déployer des clusters Hadoop locaux avec HDP 2.6.4. Afin d’utiliser les dernières fonctionnalités disponibles dans HDP, nous n’utiliserons pas ce déployeur. Néanmoins, n’hésitez pas à aller voir plus en détail ce projet, toute contribution de votre part sera la bienvenue.
Exposer les résultats streaming aux clients JDBC
Rappelez-vous que dans la partie 1 de cette série, les résultats du streaming ont été affichés dans le terminal. Seul le développeur était en mesure de voir les résultats du traitement. Dans un contexte de production, une application a besoin d’une interface pour les utilisateurs finaux. Une solution simple pour rendre les résultats disponibles avec de faibles latences consiste à monter les résultats dans la mémoire de l’application et à les exposer via l’interface JDBC/ODBC. Ceci fournit un accès en temps réel aux données mais ne les persiste pas. En plus d’exposer les données en mémoire, un stockage persistant des données sur disque est nécessaire. Ceci sera couvert plus tard dans l’article.
Les résultats de streaming stockés dans la mémoire de Spark Driver pourraient être rendus accessibles par JDBC/ODBC avec Spark Thrift Server. La plupart des outils de Business Intelligence supportent les interfaces JDBC/ODBC et pourraient recevoir donc ces résultats. Les applications Spark sont indépendantes des ressources, donc Spark Thrift Server ne serait pas en mesure d’exposer les données mises en cache dans autres applications Spark. Cependant, il est possible d’embarquer Spark Thrift Server dans la même application Spark exécutant la requête de streaming. Le code complet de la dernière partie doit être légèrement modifié.
Premièrement, Spark Thrift Server doit être lancé avant l’exécution de la requête streaming :
from py4j.java_gateway import java_import
java_import(spark.sparkContext._gateway.jvm, "")
spark.sparkContext._gateway.jvm.org.apache.spark.sql.hive.thriftserver \
.HiveThriftServer2.startWithContext(spark._jwrapped)Deuxièmement, tips.writeStream.format("console") devrait être modifié pour tips.writeStream.format("memory") :
tips.writeStream \
.outputMode("append") \
.format("memory") \
.queryName("tips") \
.option("truncate", False) \
.start() \
.awaitTermination()La principale limitation de cette méthode est la quantité de RAM pour le pilote Spark Driver. Un collecteur en mémoire ne fonctionne que pour les tables pouvant tenir dans la mémoire du Spark Driver. Il est limité jusqu’à 200 Go car la JVM n’en supporte pas plus. Sur ces 200 Go, seule une petite fraction peut être utilisée pour la mise en cache des tables. Avec les valeurs par défaut de spark.memory.fraction et spark.memory.storageFraction, la quantité maximale de mémoire disponible pour le stockage est de 200 Go * 0,6 * 0,5 = 60 Go.
Des ensembles de données plus volumineux nécessiteraient un stockage de données distribué en mémoire au lieu d’un stockage sur une seule JVM. Druid, Apache Kudu et Apache Ignite sont des exemples d’outils permettant un stockage distribué en mémoire et de hautes performances.
Soumission de l’application
L’application Spark streaming peut être soumis à être lancé sur le cluster avec une commande :
# as spark user from master02.cluster host
spark-submit \
--master yarn --deploy-mode client \
--num-executors 2 --executor-cores 1 \
--executor-memory 5g --driver-memory 4g \
--packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.3.0 \
--conf spark.sql.hive.thriftServer.singleSession=true \
/vagrant/sstreaming-spark-app.pyReprenons le code ci-dessus en détail :
- Les exécuteurs de Spark et les paramètres du pilote sont adaptés aux ressources limité du cluster présenté ci-dessus. Les paramètres sont choisis avec précision car une mauvaise configuration peut affamer ou tuer l’application. Seuls 2 exécuteurs de 5 Go et 1 noyau chacun sont réalisables. Quelques considérations dans le choix de ces valeurs :
- Application Master (AM) est un processus permettant la communication entre Spark Application et le Resource Manager de Yarn. Gardez à l’esprit que dans la configuration minimale, l’AM lui-même a besoin d’un conteneur de 1024MB + 1 noyau.
- Pour le bon fonctionnement de l’OS, chaque noeud se voit allouer 1GB de RAM et 1 coeur.
- Il y a au moins 384MB attribué à chaque JVM (pour les executors, le driver et l’AM).
- L’allocation des conteunaires est au plus bas : 512MB
- La mémoire du pilote est réglée à 4 Go au lieu de 1 Go par défaut pour tenir compte des besoins accrus de mémoire (lié aux résultats streaming en mémoire).
- Il est assumé qu’aucun autre traitements ne tourne en parrallèle. Si une autre táche monopolise est en cours d’exécution sur un cluster (par exemple un travail de traitement Tez), elle monopolisera des ressources et l’application Spark soumise devra attendre la mise à disposition des ressources.
- L’option
--deploy-modespécifie où le programme Spark Driver s’exécute sur un cluster. Le traitement de l’application en mode “client” place le pilote sur le nœudmaster02.cluster, soumettant l’application. Cela permet d’observer facilement la sortie du pilote depuis la console sur les hôtesmaster02. Le mode de déploiement “cluster” permet de placer le pilote de l’Application Master sur l’un des travailleurs du cluster. Il n’y a aucun intérêt à le faire puisquemaster02.clusterest déjà dans le cluster et qu’il n’y a pas de latence réseau. - Le paquet spark-sql-kafka est obligatoire pour l’intégration de Spark avec Kafka. La version à la toute fin doit correspondre à la version de Spark utilisée
- Par défaut, le serveur Thrift fonctionne en mode multi-sessions. Le paramétrage de
spark.sql.hive.hive.thriftServer.singleSession=truegarantit que le client JDBC/ODBC se connectera à la session existante et pourra ainsi accéder aux tables temporaires. Les tables persistantes sont toujours accessibles, même en cas de sessions multiples.
Prévisualiser les résultats
Une fois l’application démarrée, le stream des données peut être lancé de la même facon que dans la partie 1 de cet article :
# as kafka user from master02.cluster host
( curl -s https://training.ververica.com/trainingData/nycTaxiRides.gz | zcat | \
split -l 10000 --filter="/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list master02.cluster:6667 --topic taxirides; sleep 0.2" > /dev/null ) &
( curl -s https://training.ververica.com/trainingData/nycTaxiFares.gz | zcat | \
split -l 10000 --filter="/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list master02.cluster:6667 --topic taxifares; sleep 0.2" > /dev/null ) &Tout client JDBC devrait maintenant pouvoir accéder aux résultats. Par exemple, l’outil shell beeline d’Hive pourrait être utilisé dans le but de se connecter au serveur Spark Thrift. En supposant que la propriété hive.server2.thrift.port de Spark est définie sur le port 10016, beeline pourrait se connecter au serveur Spark Thrift avec la commande :
/usr/hdp/current/spark2-thriftserver/bin/beeline \
-u jdbc:hive2://master02.cluster:10016Notez que la commande beeline fournie par le Spark Thrift Server est utilisé, et non la commande de Hive (qui est la commande par défaut). Spark est compilé avec Hive 1.2.1, tandis que HDP 3.1 a la version Hive 3.1.0. L’utilisation de beeline à partir d’une version plus récente de Hive entraînerait des erreurs dues à l’incompatibilité entre versions. Par conséquent, l’ancien client beeline de Spark Thrift Server doit être utilisé. Les résultats de streaming doivent être disponibles sous la forme de tables temporaires avec le nom spécifié lors du lancement de la requête (avec la méthode DataFrame.writeStream.queryName()).
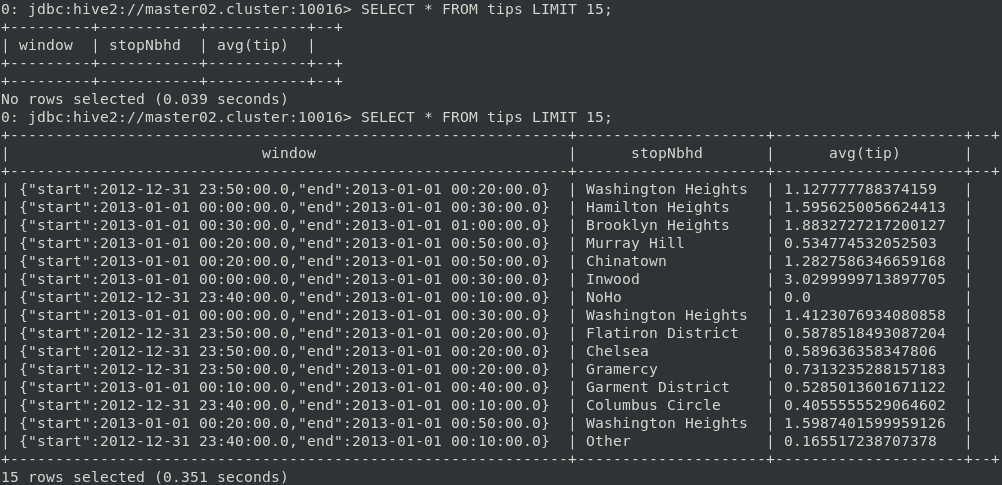
Persistence des données dans HDFS
La stockage en mémoire présenté ci-dessus est volatile et une fois les événements traités, il n’y a aucun moyen de les restaurer une fois l’application Spark arrêtée. Afin de conserver les événements entrants, les données doivent être persistées. L’ensemble de données brutes doit être stocké. Il est également possible de persister le jeu de données transformé ou de le reconstruire à partir du jeu de données brut. Il existe plusieurs destinations possible, telles que les bases de données RDBMS, les base de données NoSQL, les systèmes de fichier de tuype Object Cloud Storage (tel que Amazon S3 ou Google Cloud Storage) ou encore les systèmes de fichiers distribués (tels que Ceph, GlusterFs ou HDFS). Comme cet article concerne l’exécution de Spark sur Hadoop, nous allons utiliser HDFS.
Premièrement, les données brutes seront persistées afin de conserver les données non modifiées. Deuxièmement, les résultats de la requête streaming seront persistées pour éviter les recalculs à partir du jeu de données brutes.
Écriture des données brutes avec Spark Streaming dans le système de fichiers
Une requête Spark Structured Streaming peut écrire dans le système de fichiers en fournissant l’URI associé à la propriété path de l’instance DataFrame.writeStream. Notez que le “scheme” de l’URI indique le type de stockage. Deux requêtes streaming dans le code ci-dessous sont lancées juste après l’ingestion. Les données n’ont pas été nettoyées, jointes ni encore traitées.
from pyspark.sql.functions import year, month, dayofmonth
sdfRides.withColumn("year", year("startTime")) \
.withColumn("month", month("startTime")) \
.withColumn("day", dayofmonth("startTime")) \
.writeStream \
.queryName("Persist the raw data of Taxi Rides") \
.outputMode("append") \
.format("parquet") \
.option("path", "hdfs//namenode:namenode-port/tmp/datalake/RidesRaw") \
.option("checkpointLocation", "hdfs//namenode:namenode-port/tmp/checkpoints/RidesRaw") \
.partitionBy("year", "month", "day") \
.option("truncate", False) \
.start()
sdfFares.withColumn("year", year("startTime")) \
.withColumn("month", month("startTime")) \
.withColumn("day", dayofmonth("startTime")) \
.writeStream \
.queryName("Persist the raw data of Taxi Fares") \
.outputMode("append") \
.format("parquet") \
.option("path", "hdfs//namenode:namenode-port/tmp/datalake/FaresRaw") \
.option("checkpointLocation", "hdfs//namenode:namenode-port/tmp/checkpoints/FaresRaw") \
.partitionBy("year", "month", "day") \
.option("truncate", False) \
.start()Le format de fichier choisi, Parquet, est un format dit “orienté colonne”. Le stockage en mode colonne fournit des optimisations particulièrement efficaces pour des requêtes d’analyses dans la mesure où il offre des taux de compression élevés et où seules les colonnes utiles au traitements sont parcourues. D’autres formats de fichiers pourraient être plus appropriés selon les cas. Une alternative comparable à Parquet est le format de fichier ORC qui offre une prise en charge complète des tables transactionnelles Hive avec des propriétés ACID. À partir de Spark 2.4, le format populaire de sérialisation de données Apache Avro est également pris en charge en tant que source de données nativement intégrée. Les formats de fichier traditionnels tels que csv et json sont aussi pris en charge.
L’option path est l’URI du répertoire Hadoop où les résultats seront stockés. L’adresse et le port du NameNode se trouvent dans le fichier de configuration core-site.xml dans la propriété fs.defaultFS.
Le “sink” de fichiers Spark prend en charge les écritures sur des tables partitionnées. Dans le code ci-dessus, les “DataFrames” ont été partitionnés en fonction de l’année, du mois et du jour. Ainsi, les données sont persistées en conséquence dans la structure de répertoires “year/month/day”. Par exemple, un fichier serait stocké sur HDFS sous “tmp/datalake/RidesRaw/year=2013/month=1/day=1/part-00000-1031a1c0-8a0c-4b47-ae46-a81615f0a607.c000.snappy.parquet”. Notez que le partitionnement a été réalisé en extrayant l’heure, le mois et le jour de l’horodatage de l’événement de trajet en taxi. De nouvelles colonnes contenant l’année, le mois et le jour ont dû être créées pour permettre le partitionnement choisi.
Spark Structured Streaming offre une tolérance aux pannes avec un méchasme de vérification appelé “checkpointing”. La propriété checkpointLocation doit être spécifiée pour la récupération. Le checkpoint défini le processus de tronquage du graphe de lignage RDD et son enregistrement dans un système de fichiers distribué fiable (par exemple HDFS) ou local. Dans Spark Structured Streaming, il conserve l’état des métadonnées du flux d’alimentation vers HDFS en cas de défaillance. Par exemple, si un exécuteur tombe en panne, Spark peut récupérer le dernier offset du topic Kafka en source.
The methodology in this section implies that a single message received from Kafka topic is persisted only once on HDFS, without duplicates. Note that each Taxi ride entails 3 types of events : the beginning of the ride, the end of the ride, and the fares information that are collected seperately when the ride ends.
La méthodologie présentée implique qu’un seul message reçu du Kafka Topic est persitée une seule fois sur HDFS, sans doublons. Notez que chaque trajet en taxi implique 3 événements : le début du trajet, la fin du trajet et les informations sur les tarifs qui sont collectées séparément à la fin du trajet.
Écriture des résultats de la requête Spark Streaming dans le système de fichiers
En plus de la persistance des données brutes, les résultats de la requête streaming peuvent être conservés :
tips.writeStream \
.queryName("tips") \
.outputMode("append") \
.format("parquet") \
.option("parquet.block.size", 10240) \
.option("path", "hdfs//namenode:namenode-port/tmp/datalake/") \
.option("checkpointLocation", "hdfs//namenode:namenode-port/tmp/checkpoints/") \
.partitionBy("window") \
.option("truncate", False) \
.start() \
.awaitTermination()The “tips” streaming DataFrame has been already processed, as showed the first part. In the code above, the partitioning is specified on the “window” column. Recall that this column was obtained in the “Adding aggregation” section of the first part.
Le tableau “tips” a déjà été traité, comme indiqué dans la première partie. Dans le code ci-dessus, le partitionnement est spécifié sur la colonne “window”. Rappelons que cette colonne a été obtenue dans la section “prise en compte de l’aggrégation” de la première partie. Une agrégation sur la colonne “tips” a été effectuée à la toute dernière étape du traitement :
tips = sdf \
.groupBy(
window("endTime", "30 minutes", "10 minutes"),
"stopNbhd") \
.agg(avg("tip"))La requête agrégée calcule le pourboire moyen pour chaque quartier sur des fenêtres temporelles de 30 minutes. Les nouvelles fenêtres commencent toutes les 10 minutes, ce qui fait que certaines fenêtres se chevauchent. La sortie de la requête de diffusion en continu dans la console était comme ci-dessous :
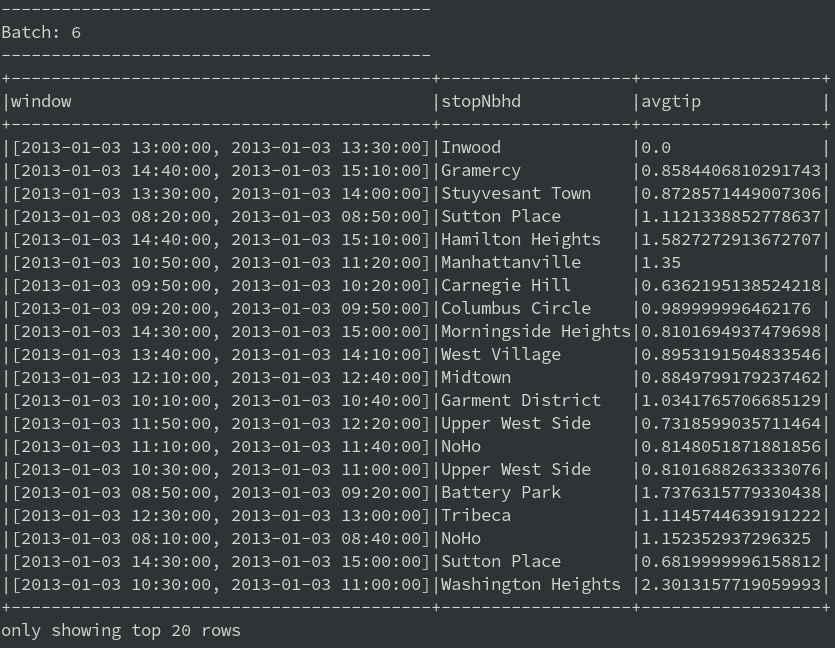
Les résultats sont répartis sur le disque en fonction de la structure de répertoires spécifiée par le partitionnement. Le partitionnement est spécifié dans la colonne “window”, ainsi chaque enregistrement du tableau ci-dessus sera écrit dans un répertoire distinct, nommé d’après la fenêtre temporelle de l’enregistrement. Par exemple, la fenêtre commençant à 9h50 et se terminant à 10h20 le 1 jan 2013 contient un répertoire /tmp/datalake/window = [2013-01-0109: 50: 00,2013-01-0110: 20h00]. A l’intérieur de ces répertoires sont écrits plusieurs fichiers de la forme part-00008-cedf7585-be4c-469b-80f6-5cc5a0c4623e.c000.snappy.parquet.
Les fenêtres agrégées d’une durée de 30 minutes glissent toutes les 10 minutes. Par conséquent, un seul trajet taxi peut être utilisé pour le calcul jusqu’à 3 fois. Un seul trajet en taxi influence de nombreuses fenêtres, mais chaque fenêtre possède un ensemble unique de “tips” moyens calculés pour les quartiers.
Écriture vers plusieurs emplacements
Prenons l’hypothèse où nous souhaiterions conserver deux types de stockage de résultats : persistant dans HDFS et en mémoire à pour des requêtes à faible latence. Malheureusement, l’interface writeStream est conçue pour prendre en charge une seule destination pour les résultats de la requête de transmission en continu. Bien que les résultats du traitement de flux ne puissent pas être simplement dupliqués sur un autre récepteur, d’autres stratégies peuvent être utilisées pour réaliser le stockage de données à la fois en mémoire et dans un système de fichiers distribué.
- Il est possible de lancer 2 requêtes streaming en parallèle dans une application Spark. La première requête effectue le traitement et met les résultats finaux en mémoire, tandis que la seconde les lit périodiquement à partir de là et les écrit dans un stockage persistant.
- Au lieu d’exécuter des requêtes dans une seule application, elles pourraient être affectées à deux applications Spark individuelles utilisant le même sujet Kafka.
- Une autre solution pourrait être d’utiliser le
StreamSinkProviderdisponible auprès de Spark 2 pour implémenter un Sink personnalisé. - Enfin, le récepteur
foreachBatchdisponible dans Spark 2.4 peut être utilisé pour mettre en oeuvre une logique personnalisée qui écrit les résultats de la requête dans plusieurs emplacements.
Compaction de plusieurs fichiers HDFS
Les fichiers Parquet persistants sur HDFS sont de petites taille, largement inférieur à la taille précaunisée (environ 1GB) et même d’un block HDFS (habituellement entre 128Mo et 256Mo). Ils sont regroupés à l’intérieur des répertoires correspondant aux fenêtres agrégées. Le coût de stockage d’une grande quantité de petits fichiers dans HDFS est important dans la mesure ou celui concerve toutes les métadonnées du système de fichiers en mémoire.
Stocker trop de petits fichiers est considéré comme une mauvaise pratique. Il est toutefois acceptable que seuls quelques-uns d’entre eux soient stockés temporairement. Le flux créé ci-dessus ne causera pas de problèmes tant que des milliers et même des millions de petits fichiers ne seront pas accumulés. Un job batch de compactage périodique pourrait être créé pour les fusionner en plus grands. Ce job, qui peut s’écrire en Spark, pourrait énumérer les répertoires correspondant à chaque fenêtre temporelle et fusionner les fichiers. Ce travail par lots peut être planifié quotidiennement avec un outil comme Apache Oozie ou Apache Airflow.
Surveillance des requêtes
La surveillance et les notifications sont des aspects non négligeables dans les environnements de production. De nombreuses éléments peuvent être écrasés, perdus… Une surveillance adéquate est donc la première étape pour prévenir les pannes de cluster. Pour la surveillance générale de tous les nœuds et services d’un cluster, Nagios peut être utilisé.
Il existe de multiples façons de monitorer les requêtes Spark streaming. En effet, les requêtes Spark Structured Streaming peuvent être surveillées interactivement depuis un programme avec streamingQuery.lastProgress() et streamingQuery.status(). De plus, les UIs Web de Spark sont riches en informations sur les jobs Spark. Dans un environnement de production, une solution plus automatisée est préférable. Heureusement, les métriques Spark peuvent être rapportées à des systèmes externes (par ex. fichiers Ganglia, HTTP, JMX et CSV) à l’aide de Dropwizard Metrics Library.
La fiabilité de Spark Structured Streaming
Un autre aspect important d’un environnement de production est la stabilité du service. Spark Structured Streaming s’améliore avec chaque version et est suffisamment mature pour être utilisé en production. Cependant, comme la plupart des logiciels, il n’est pas exempt de bugs. Par exemple, Spark Structured Streaming en mode append peut entraîner des données manquantes (SPARK-26167). Le mode append est ainsi obligatoire si les données sont persistées dans S3 ou si vous utilisez la fonctionnalité stream-stream join. Même s’il a été résolu dans Spark 2.4 (SPARK-24156), la plupart des utilisateurs ne pourront pas encore bénéficier de ce correctif. Par exemple, la dernier version 3.1.0 d’HDP est toujours livrée avec Spark 2.3. De nombreuses entreprises ont encore HDP 2.x et des versions antérieures de Spark. Étant donné la fusion récente entre Cloudera et Hortonworks, la version récente de Spark ne sera probablement pas disponible avant la publication de Cloudera Data Platform (CDP). Les nouvelles fonctionnalités de Spark Structured Streaming à partir de Spark 2.3 doivent être introduites avec précaution, car les corrections de bugs ne sont pas disponibles immédiatement.
La sécurité dans un cluster
Dans cet article, le cluster de test utilisé n’est pas sécurisé. Dans un environnement de production réel, les problématiques de sécurité devant être considérées sont nombreuses : authentification (LDAP, Kerberos, SSL/TLS, login/mot de passe), autorisation (RBAC, ABAC, RAdAC, etc.), politiques réseau (pare-feu, isolation VLAN, règles NAT), chiffrement des données (en transit/au repos) et enfin gouvernance des données. Par exemple sur un environnement HDP, les services suivants sont généralement déployés sur un cluster pour répondre aux besoins de sécurité :
- Apache Knox exploite le protocole d’authentification et les politiques réseau de Kerberos pour la sécurisation diu périmètre d’un cluster Hadoop.
- Apache Ranger exploite les modèles de contrôle d’accès d’autorisation pour les standardiser sur un cluster Hadoop.
- Apache Atlas fournit une gouvernance basée sur les métadonnées d’un cluster Hadoop
Résumé
Pour bénéficier des avantages de Spark en production, celui-ci doit s’exécuter dans un environnement distribué tel qu’un cluster Hadoop. Le développement d’une application Spark Structured Streaming ne constitue qu’une partie du travail. Déployer, sécuriser et surveiller une application Spark dans un cluster Hadoop est un processus impliquant des compétences de programmeur, d’être confortable avec la manipulation de données, de maîtrise les techniques de DevOps, ou encore la compréhension de l’infrastructure, pour n’en nommer que quelques-uns. De plus, le lancement et l’exploitation des applications Spark Structured Streaming sur un cluster nécessite des paramétrages et des optimisations plus fines que sur un poste local.
