


Apache Apex: next gen Big Data analytics

Jul 17, 2016
- Categories
- Data Science
- Events
- Tech Radar
- Tags
- Apex
- Storm
- Tools
- Flink
- Hadoop
- Kafka
- Data Science
- Machine Learning [more][less]
Do you like our work......we hire!
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Below is a compilation of my notes taken during the presentation of Apache Apex by Thomas Weise from DataTorrent, the company behind Apex.
Introduction
Apache Apex is an in-memory distributed parallel stream processing engine, like Flink or Storm. However, it is built with native Hadoop integration in mind:
- Yarn is used for resource managing and ordonnancing
- HDFS is used to store persistant states
Application development model
- A stream is a sequence of tuples
- An operator:
- takes one or more input streams as input
- performs custom computation on the tuples (logic is in Java)
- emits one or more input streams
- has many parallel instances, each single threaded
- uses the DAG model to optimize computation
- An application is a suite of operators
Development process
A typical WordCount setup with Apex looks like this:
- Apache Kafka brings the data
- The Apex application processes through the following operators:
- Kafka input
- Parser
- Filter
- Word counter
- JDBC output
- End data is written in DB
The development process goes like this:
- Take an operator from existing libraries or implement a custom logic
- Connect the operators to form an application
- Configure the operators properties
- Configure scaling & platform attributes
- Test functionalities, performance and iterate
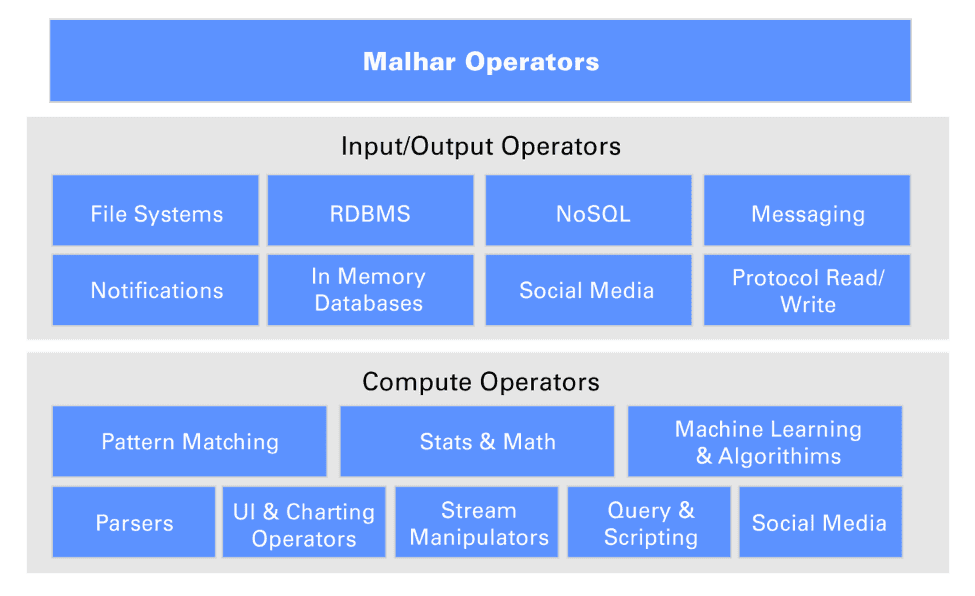
Operator libraries
Apex provides very complete operator libraries through Apache Apex Malhar:
- Messaging (Kafka, ActiveMQ, …)
- NoSQL (HBase, Cassandra, MongoDB, Redis, CouchDB, …)
- RDBMS (JDBC, MySQL, …)
- FileSystem (HDFS / Hive, …)
Notes
- Apex uses Apache BEAM for the job implementation so he enjoys its multiple benfits:
- dynamic partition at runtime
- load-balancing between operators
- windowing
- …
- For fault tolerance, the operators states are checkpointed and persisted
- Apex processing guarentees for
- at least once
- at most once
- exactly once
