


Apache Thrift vs REST

Oct 28, 2017
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Adaltas recently attended the Open Source Summit Europe 2017 in Prague. I had the opportunity to follow a presentation made by Randy Abernethy and Jens Geyer of RM-X, a cloud native consulting company, about the use of Apache Thrift in the building of high performance microservices. The focus was that Thrift is very fast and how it applies to microservices. An important part of the presentation covered how Apache Thrift compares with REST and gRPC in term of velocity.
Quick history of REST
REST, for Representational State Transfer, was defined in 2000 by Roy Fielding. It allows communication between web resources (computers, web browsers, etc.) respecting a set of constraints:
- Client-server architecture
- Cache-friendly
- Stateless
- Standard interface
- HTTP transport
With such characteristics, REST systems aim at fast performances, reliability, and the ability to be modified without affecting the system as a whole. Most of the web relies on HTTP and REST for communication and they both have proven their worth, reliability and scalability over the years.
Overall, REST is great for the web. However, the stack composed of REST, HTTP and JSON is not optimal for high performances required for internal data transfer. Indeed, the serialization and deserialization of these protocols and formats can be prejudicial for overall speed.
This is where Thrift comes in.
Apache Thrift
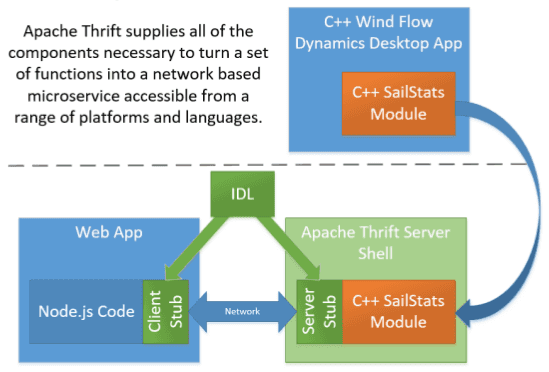
Apache Thrift was originally developed at Facebook, it was open sourced in 2007, registered in the Apache incubator program in 2008 and became a top level Apache project in 2009. It is nearly impossible to deploy a Big Data infrastructure without coming across Thrift. For example, HiveServer2 is built using Thrift. We can also cite HBase’s Thrift interface.
Thrift’s infrastructure allows to create cross-language services and currently supports almost 20 languages (C++, Java, JavaScript, etc.).
The workflow to create a service is the following:
- Define it using Thrift’s IDL
- Generate client stubs in any desired languages
- Generate a server stub and implement it
- Use a Thrift server to implement the service
Here is an example of a Thrift service that would be used to monitor GitHub projects:
struct Date {
1: i16 year
2: i16 month
3: i16 day
}
struct Project {
1: string name
2: string host
3: Date inception
4: i16 commits
}
struct CreateResult {
1: i16 code
2: string message
}
service Projects {
Project get(1: string name)
CreateResult create(1: Project proj)
}An additional benefit of Thrift is the support for multiple protocols. For example, the same service can communicate using a binary protocol, XML or even JSON. The binary encoding makes it easier to send large amounts of data over internal networks.
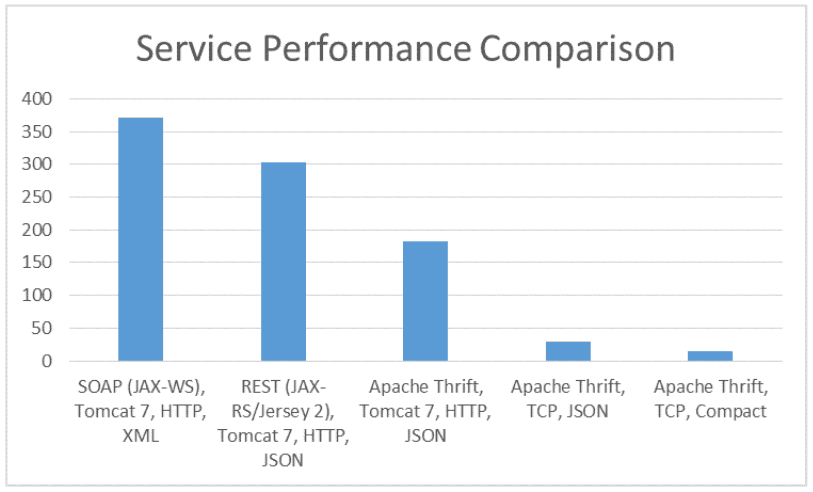
The above graph shows the performances of the same service implemented using different protocols including our two competitors, Thrift and REST. The y-axis is the amount of time in seconds to call the service a 1M times. We can see that Thrift is thriving.
Conclusion
Thrift and REST both have their pros and cons. REST is perfect for simple web APIs, but its heavy serialization makes it inappropriate for internal company wide services. When it comes to micro-services, Thrift’s rapid binary serialization and countless languages makes it a no-brainer.
