


Lando: Deep Learning used to summarize conversations

By Yliess HATI
Sep 18, 2018
- Categories
- Data Science
- Learning
- Tags
- Micro Services
- Open API
- Deep Learning
- Internship
- Kubernetes
- Neural Network
- Node.js [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Lando is an application to summarize conversations using Speech To Text to translate the written record of a meeting into text and Deep Learning technics to summarize contents. It allows users to quickly understand the context of the conversation.
During the course of our internship at Adaltas, we worked on a new project called Lando to explore operation applied to Data Science while leveraging our knowledge in Deep Learning. In this article, we will discuss the development process and architecture of Lando.

Microservices
Breaking up the tasks for Lando, we decided to give a go to a Microservices architecture: the project is split up into smaller applications called Microservices, each handling a thin part of the overall product. With stateless or distributed state management, Microservices offer the elastic scalability: when a service is overloaded, you can just spawn more instances of the service; in other words, you adjust the number of process and resources to your needs.
Kubernetes is at the core of our architecture to provision and orchestrate the overall solution.
Services
The services constituting the project are of two kinds. The API endpoints are accessible to the outside world as an interface to the end users. The core application, inaccessible to the end users, operate Deep Learning tasks.
API endpoints
We have several API endpoints:
- User login
- User management (user info, registration etc…)
- User input (receiving the text to summarize)
- Results notification and access
HTTP REST endpoint are written following the OpenAPI standard using Swagger. The endpoints are web servers generated by Swagger using the Express framework in Node.js. A Node.js package is shared as a dependency to provide common functionalities including messages used as responses, utility functions and the databases connectors.
Core
They are multiple services planned at the core Lando, including an advance Speech To Text solution. We have concentrated our effort on the conversation summary service. It is Deep Learning based application which takes the data given by a user and outputs a summary of the text along with some additional information. This part was written in python to leverage our knowledge of Tensorflow. Given the size of the model and the libraries, we decided to move the model folder out of the Deep Learning environment. Tests were done on a local NFS, making the model a read-only mount point for the Deep Learning microservices, and a cloud solution can be implemented rapidly for production using the Kubernetes Persistent Volume abstraction.
Here is the Kubernetes configuration of the Lando Deep Learning Microservice:
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
namespace: lando
name: landodp-summarizer
spec:
serviceName: "landodp-summarizer"
replicas: 1
template:
metadata:
labels:
namespace: lando
component: summarizer
spec:
containers:
- name: landodp-summarizer
image: landohub/landodp_summarizer
imagePullPolicy: Always
volumeMounts:
- name: weights-dir
mountPath: /lando_deep_learning/lando/nlp/data
env:
- name: NATS_ENDPOINT
value: nats
resources:
requests:
memory: "1Gi"
cpu: "500m"
terminationGracePeriodSeconds: 7
volumes:
- name: weights-dir
persistentVolumeClaim:
claimName: summarizer-weights-dir
updateStrategy:
type: RollingUpdateIn the example above, the volume “weighs-dir” contains the model in use by the pod, the volume claim being summarizer-weights-dir, which we can find in the Persistent Volume Claims:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
datadir-cockroachdb-0 Bound pvc-952578cb-850f-11e8-8214-0800271cfb2c 1Gi RWO standard 11d
datadir-cockroachdb-1 Bound pvc-10735233-85b4-11e8-af67-0800271cfb2c 1Gi RWO standard 11d
summarizer-weights-dir Bound summarizer-weights-dir 10Gi ROX 11dWhich, in our local setup, is provisioned on a local NFS server.
Frontend
The Frontend interface is a web server with a optimized static website, the JavaScript executed on the end user’s browser will connect to the aforementioned APIs. Since the Frontend service does not hold any state, it is easily scaled and load balanced.
Databases
Because of the distributed and fault tolerant nature of our application and to insure the elasticity of our application, we choose distributed databases that could easily scale. Our decision went for CockroachDB to store our data. It is a relational, distributed and highly available database. We initially intended to use FoundationDB which had been recently open sourced by Apple but it implied more effort in term of integration which wasn’t aligned with our main objectives.
The decision of using CockroachDB was largely influence by the guaranties it provided us as well as the quality of its documentation when deployed inside a Kubernetes cluster environment.
Aside from the databases we also needed a way to move data from one Microservice to another. We first thought of Apache Kafka, but eventually chose NATS because it is a lightweight standalone message broker and you can have an overview of everything with a simple Telnet connection.
Containers
The use of containers was driven by the Microservice architecture. It is common nowadays to use containers to quickly and efficiently deploy a solution and constitute the core of a Microservice system. Scaling an application is a time-sensitive to provide fast reaction to a sudden load.
The whole system is orchestrated by Kubernetes, (Minikube for our tests). The responsability of the orchestrator is to start and shut down containers while ensuring their availability. It also comes with a Network facilities so we don’t have to manually configure it. It routes the request on its own and can assist with in the upgrade strategy imposed by your application. Despite its learning curve but the tool has proven to be powerful and flexible to our requirements.
For instance, here are all the pods of Lando on a developer environment when the application is running:
NAME READY STATUS RESTARTS AGE
cockroachdb-0 1/1 Running 8 11d
cockroachdb-1 1/1 Running 8 11d
default-http-backend-648cfc585b-zgqvp 1/1 Running 5 6d
foundationdb-0 1/1 Running 15 11d
frontend-httpd-6c9f6db5cd-hpq8q 1/1 Running 2 3d
landodp-summarizer-0 1/1 Running 7 10d
loginmanager-api-5fc996574b-n7t62 1/1 Running 6 6d
nats-0 1/1 Running 8 11d
nginx-ingress-controller-846f5b5c5c-gntw4 1/1 Running 5 6d
realtimeupdate-api-86b5986465-tv55p 1/1 Running 0 2d
sessionmanager-api-66c54df75c-lh757 1/1 Running 6 6d
usermanager-api-76885d8b74-7krqn 1/1 Running 7 6dSecurity
Regarding security, our first concern is to be able to identify a user making a request to the APIs. We first thought of a token-based system where, once connected, a user is given a stored unique token that has to be set in every request but we were worried about the load it was going to put the database under, so we opted for JWT (JSON Web Token).
- A header is issued:
{
"type":"JWT",
"alg":"HS256"
}- User and additional connection informations are put in a JSON object:
{
"userid":"364763392789544962",
"username":"toto",
"userstatus":"0",
"issuedTime":1532078309046,
"expirationTime":1532164709046,
"duration":86400000
}- A unique signature is created to validate the information
The latest two parts are base64 encoded and concatenated to the signature, separated by dots, and stored in the browser. Here, the complete JWT is:
eyJ0eXBlIjoiSldUIiwiYWxnIjoiSFMyNTYifQ.eyJ1c2VyaWQiOiIzNjQ3NjMzOTI3ODk1NDQ5NjIiLCJ1c2VybmFtZSI6InRvdG8iLCJ1c2Vyc3RhdHVzIjoiMCIsImlzc3VlZFRpbWUiOjE1MzIwNzgzMDkwNDYsImV4cGlyYXRpb25UaW1lIjoxNTMyMTY0NzA5MDQ2LCJkdXJhdGlvbiI6ODY0MDAwMDB9.N4VqqSFOXeRqLSp16sJFOma+DRIZr/kf5EnY9qiY0CY=On the server, thanks to Kubernetes Secrets Management, we have a secret token, shared amongst microservices requiring user identification. the signature being the hash of the header, user info, and shared secret, the JWT cannot be tampered with, or it will be rejected by the server.
Another issue is user rights and permissions so we kept it minimal: the user giving the text to summarize is the only one to have access to it. User’s passwords are stored hashed and salted as a standard security practice.
Finally, even a strong token-based identification is useless without encryption, the token could be intercepted and the whole system becomes vulnerable to replay attacks, so every message is secured with HTTPS.
Workflow
Deep Learning
We were taught that there is a particular manner of working on Deep Learning projects. These are the steps you should follow in order to get it to work and make it to production:
- Read papers, the newest but also some of the previous ones in order to understand what is working and what is not
- Find a good dataset adapted to your problem or create one through internet resources or crowdsourcing
- Try to implement the state of the art model or try the official implementation if there is a repository.
- Start training your model on your own machine at first and try to finetune hyperparameters.
- Most of the time it is better to train the final model in the cloud on several GPUs. Training takes less time and convergence is quicker.
- Save your model and code something that is able to load the checkpoint and perform one inference. Be careful to make those two parts in two separate functions. (If you do not want to load the checkpoint every inference)
- Transform your code to be used into an API or something that suits your needs
This method seems to work best with Deep Learning projects which are not destined to become research projects.
Versioning
Each API is a standalone Node.js project with its own tests and release pipeline using NPM and docker-compose for the testing environment. Tests are executed in a container with a network and environment as close as possible to the Kubernetes targeted environment. Code repositories are on a private GitLab instance but and images extends a public docker image.
All the services being independents, their version number are kept in sync.
We also have a project containing the kubernetes scripts and project documentation, so it can easily be deployed on a cluster.
Deep Learning
Deep Learning is a popular nowadays. Why didn’t we used blockchain as well? It is present in our browser, in our cars, phones, … etc. The technology itself has been there for a while. It was lately popularized with the advent of Big Data. Those algorithms gain in relevance when feeded with more data. Thanks to the amount of data the Internet is gathering, Deep Learning has grown up and matured to a point where it outperforms ancient algorithms in a lot of fields. It is one of the most active community and field in computer science.
Given the project’s requirements it was obvious we had to use it to realize this project. The Deep Learning core component of Lando is split into two parts, the Speech To Text component and the Summarizer component.
Summarizer
There are two types of summarization algorithms:
- Extractive methods: they do not require Deep Learning as they use Machine Learning and Statistics to summarize a text by extracting the samples that are the most meaningful.
- Abstractive methods: they tend to seem more human since they can summarize using other words than the one present in the text and it looks like they can understand long-term context.
We can see extractive methods as a highlighter and abstractive ones as a pen.
However, abstractive summarization is currently not a closed topic as it does not work very well with long texts. Most of the best performing algorithms are based on both technics, abstractive and extractive, which is what we decided to use for Lando.
To do so, we first dug the web to find state of the art papers and the one that stood out was ’Get To The Point: Summarization with Pointer-Generator Networks’, an abstractive summarizer that can use vocabulary words outside of its model to use words from the original text. This allows, for instance, the use of technical vocabulary words used in the original text that would otherwise be lost.
Pointer Generator Network or PGN is a Sequence to Sequence model like the one traditionally used to perform translations, except that it summarizes instead of translating. More precisely, it is a type of recurrent neural network (RNN) that possesses an attention mechanism. It runs likes this:
- We feed it with sentences and words that it tokenizes and processes through Embedding.
- The attention mechanism computes an attention distribution over the RNN cells.
- We obtain a Context Vector that is combined with the previous output of the model.
- This gives us a vocabulary distribution to get the next output until we find an END token.

This is how a simple Seq2Seq model with attention works, but it has some issues:
- Some of the details summarized are wrong
- It often repeats itself
As explained in the paper, the first issue is tackled by computing the probability to take a word directly from the original sentences instead of computing it before computing the context vector. It also allows the algorithm to introduce new words. The second problem is handled with the introduction of a coverage loss that states how much of the text has already been summarized in order to avoid repeating itself.
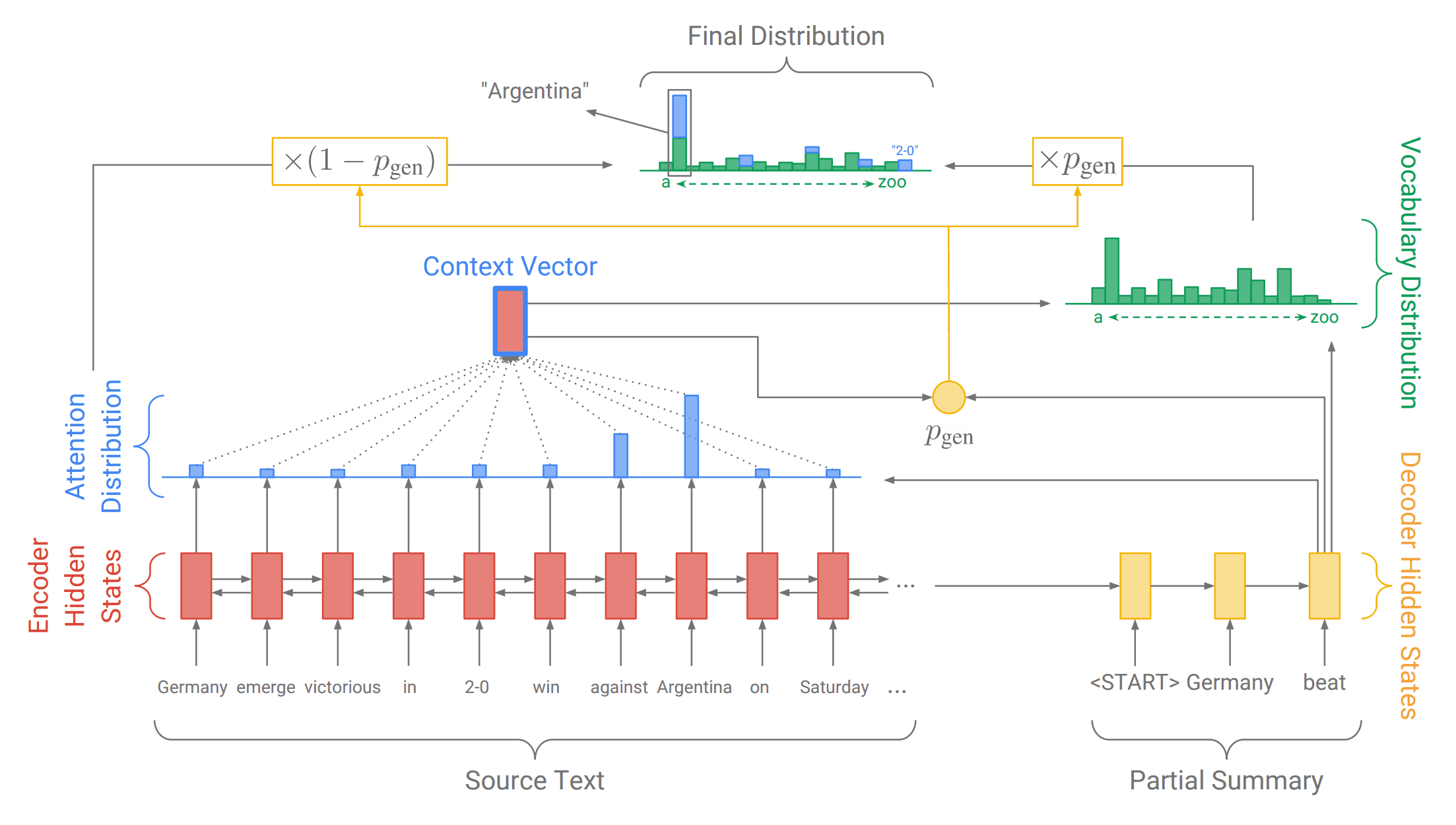
Since we do not have enough time to train the model, we’ve taken the pre-trained model from the official repository. We started to implement it from scratch but while training we realized how slow it would be using our machines. To make it work we just had to adapt their code to perform inferences.
But it is not enough, we also have to find a way to perform extractive summarization and group sentences by topic. We used the Gensim library to pre-summarize the topic grouped sentences in order to feed them to the PGN model, the most difficult part being to group the sentences by topic.
After doing some research, we found observable patterns to handle this task: turn sentences into some sort of a vector representation to cluster them by a given distance. We decided to train a topic model: an Encoder-Decoder model that is building an Embedding representation for sentences by grouping similar ones in terms of the topic using the Cosine Distance.
The model we used is called Doc2Vec and it is inspired by the famous Word2Vec model used for words in most of the Natural Language Processing models.
So the final pipeline’s pseudo-code is:
for each sentence in text:
clean sentence
get sentence embedding
k = number of topics
cluster sentences using k-mean
for each cluster in clusters:
do extractive summarization
do abstractive summarization
abstract = concatenate the sentencesFinally, with this Pipeline, we are able to summarize long texts.
However, there is actually one major problem with Lando as it is right now: all of its models have been trained with datasets designed for article summarization, we have to retrain all them with appropriate data. Which raises the question: is there a dataset for ‘meeting’ summarization? The only one we found that could do the trick is a dataset on email summarization. Emails are some sort of a written meeting, but it is not exactly what we need since there is no interference, neither informal vocabulary. So, we should start making our own dataset. With this major improvement, we think our prototype would drastically improve its performances.
Speech To Text
Since Speech To Text is a ‘solved’ problem, we have decided to first focus on the summarization task. But we still have done some research on the subject and read some papers as we did for the summarizer. We have three possible solutions:
- Use Google’s API which is currently the best
- Use an In-Browser one
- Make our own model
| Pros | Cons | |
|---|---|---|
| Google API | Accurate + Time | Paying Service |
| In-Browser | Client Side | Not Accurate Enough |
| Custom Made | Free + Accurate | Time + Training |
All these solutions are great for serving our purpose but there are pros and cons. If we want a proof of concept we would choose the In-Browser Solution or the Google one since they are fast, easy to use and already working. But if we want to turn Lando into a commercial service, it would be better to develop our own solution. Thanks to Google’s and Baidu’s papers and all the resources available on Github, we can handle this with time and good data.
Client web application
On the client side, we created a single page javascript website to test our API calls. As it is the visual part of the project we wanted to make something that could give us a peak of the final Lando. Here are some technologies that stood out in our researches:

The client website just needs to allow clients to sign in or log in to their account to access Lando services. They will be able to start sessions and to manage the previous ones.
Conclusion
Overall, this project was interesting and covered a wide range of technologies and skills. This was a great opportunity to learn, not only Deep-learning or infrastructure techniques but project management as well. There are still a lot of things to improve and to add before we can have a fully production-ready application but the project seemed to go in the right direction.
Links used in this article
- OpenAPI
- Swagger
- Express
- Kubernetes volumes abstraction
- CockroachDB
- FoundationDB
- Kubernetes
- Apache Kafka
- NATS
- Minikube
- JWT
- Kubernetes Secrets Management
- replay attacks
- Gitlab
- NFS
- Deep Learning
- Machine Learning
- Doc2Vec
- Word2Vec
- Pointer Generator Network
- React.js
- Vue.js
- Material Design
- Googles API
- Github
- GPU
- Seq2Seq
- Encoder-Decoder
- Big Data
- Speech To Text
- Gensim
- Natural Language Processing
- Embedding
- Cosine Distance
- Tensorflow
