


Spark Streaming part 3: DevOps, tools and tests for Spark applications

May 31, 2019
- Categories
- Big Data
- Data Engineering
- DevOps & SRE
- Tags
- DevOps
- Learning and tutorial
- Spark
- Apache Spark Streaming [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Whenever services are unavailable, businesses experience large financial losses. Spark Streaming applications can break, like any other software application. A streaming application operates on data from the real world, hence the uncertainty is intrinsic to the application’s input. Testing is essential to discover as many software defects and as much flawed logic as possible before the application crashes in production.
This is the third part of a four-part articles series:
- In the first part, a data pipeline with a Spark Structured Streaming application is built.
- The second part concerns the migration of the pipeline to a Hadoop cluster.
- In the third part, the PySpark application was ported to Scala Spark and unit tested.
- The fourth and last part enriches the data pipeline with a Machine Learning clustering algorithm.
In this article, unit tests shall be incorporated to reduce the risk of our Spark application’s malfunctioning and failure. Tests automation within the application building process should be considered a necessary practice to avoid software bugs and mishandled edge cases. With automated testing, Spark application is automatically verified against the test suites each time the application is compiled.
The Python source code developed previously will now be rewritten into Scala code. Scala is a statically typed, compiled language which makes Spark applications written in Scala less prone to errors. Scala Spark applications integrate better with the JVM infrastructure that is likely already present in the company. Performance isn’t the motivation here, because PySpark applications using DataFrame API are usually almost as fast as its Scala counterpart.
The project can be found in the adaltas/spark-streaming-scala GitHub repository. It contains Scala Spark translation of the previous PySpark’s spark-streaming-pyspark project, as well as unit tests developed in this article.
DevOps toolchain overview
The practice of writing automated tests is an important activity which improves the quality and the reliability of the software and its life cycle. In addition, they bring comfort to developers by reducing the time required for compiling and executing the code being written, making the programming process more fluid and responsive while ensuring the preservation of acquired functionalities.
Automated testing is a part of the continuous integration (CI) strategy that strives for the application’s integrity within the software life cycle at any time. The list below gives a general perspective on the ensemble of DevOps practices in the software life cycle:
- Continuous integration (CI)
- Code development with source code management (e.g. GIT)
- Build automation (e.g. Jenkins compiling git managed Scala code with sbt)
- Tests automation (unit tests, integration tests, acceptance tests)
- Continuous deployment (CD)
- Packaging (pre-deployment) software to repositories
- Releasing
- Configuring (IaC - infrastructure configuration and management, e.g. with Ansible)
- Monitoring – applications performance monitoring, end-user experience
All the points apply to the life cycle of a Spark application, as to any other piece of software. The continuous integration of a Spark application doesn’t differ much from the CI of any Scala application. It needs to be managed by source control software, automatically built, and tested. The continuous deployment depends largely on the target infrastructure and is out of the scope of this article. From all the DevOps practices, we will focus on the unit tests, the test coverage and the usage of a linter.
Unit testing and integration testing
A unit test quickly verifies that a small, isolated part of the source code works as expected. The units of the source code that are being tested are typically functions of a class. Unit tests check that methods have specified behavior, especially in difficult conditions. The tests assure that a given unit of the source code complies with the specification.
Strictly speaking, any unit test must be completely isolated from the other unit tests and the external components. Based on this, one could argue that any Spark test is an integration test rather than a unit test. It’s a fair point since a test involving Spark needs a SparkSession, which is not only an external dependency but is also often shared between tests. Still, the most important part about the isolation of unit tests is the separate data between tests. It could be assured by creating individual mock DataFrames for each test, in which case it’s acceptable to call those Spark tests unit tests.
One should also write integration tests in custom solutions where different components are interacting. In some cases, frameworks already provide the connectors and integration tests aren’t necessary. For example, Spark supports Kafka hence this integration is already tested.
End-to-end tests could be considered atop integration tests. End-to-end tests conclusively verify that all components are configured properly and the chain works from one end to the other. Acceptance tests are another type of tests that could be done, to validate that the final solution works as expected in the specs. Both end-to-end and acceptance tests are relatively costly, complex, and time-consuming. There won’t be any acceptance nor end-to-end tests in this article.
Unit testing of a helper function
In Spark applications, there are often functions that don’t rely in any way on Spark nor RDD and DataFrames. Those functions usually contain business-specific logic and could be tested independently from Spark. In the Python code developed in the first part of the series, a function isPointInPath() was created to verify if the point (x,y) is within a given polygon. The code below is a Scala implementation of this function.
package com.adaltas.taxistreaming.utils
object PointInPoly {
def isPointInPoly(xCoordinate: Double, yCoordinate: Double, poly: Seq[Seq[Double]]): Boolean = {
// https://wrf.ecse.rpi.edu/Research/Short_Notes/pnpoly.html
val numberOfVertices = poly.length
var i = 0
var j = numberOfVertices-1
var crossedPolygone = false
for (i <- 0 until numberOfVertices) {
if (( (poly(i)(1) > yCoordinate) != (poly(j)(1) > yCoordinate) ) &&
( xCoordinate < poly(i)(0) + (poly(j)(0) - poly(i)(0)) * (yCoordinate - poly(i)(1)) / (poly(j)(1) - poly(i)(1)) )
) crossedPolygone = !crossedPolygone
j = i
}
crossedPolygone //true when point is in poly (vertical line crossed polygone an odd number of times)
}
}The sbt directory structure must be respected. All Scala source code files and test files should be put in “src/main/scala/” and “src/test/scala/” directories, respectively. They could be put there directly, but grouping Scala files into Scala packages is a good practice.
Following the convention com.adaltas.taxistreaming.utils package. Unit tests verifying the source code of the “src/main/scala/com/adaltas/taxistreaming/utils/PointInPoly.scala” file should be written in the “src/test/scala/com/adaltas/taxistreaming/utils/PointInPolyTest.scala” file.
ScalaTest framework will be used for writing those unit tests. ScalaTest is a popular workbench providing tools for testing Scala code. It provides high-level abstraction facilitating writing tests for Scala applications. Tests are written with one of the testing styles available in ScalaTest.
The code below is an example of PointInPolyTest.scala file with three simple unit tests following the FlatSpec style.
package com.adaltas.taxistreaming.utils
import org.scalatest.FlatSpec
class PointInPolyTest extends FlatSpec {
val manhattanBox: Seq[Seq[Double]] = Vector(
Seq(-74.0489866963, 40.681530375),
Seq(-73.8265135518, 40.681530375),
Seq(-73.8265135518, 40.9548628598),
Seq(-74.0489866963, 40.9548628598),
Seq(-74.0489866963, 40.681530375)
)
"A Geopoint from Manhattan" must "be inside Manhattan polygon" in {
val pointManhattan: (Double, Double) = (-73.997940, 40.718320)
assert(PointInPoly.isPointInPoly(pointManhattan._1, pointManhattan._2, manhattanBox))
}
"A Geopoint from Meudon" must "not be inside Manhattan polygon" in {
val pointMeudon: (Double, Double) = (2.247600, 48.816210)
assert(!PointInPoly.isPointInPoly(pointMeudon._1, pointMeudon._2, manhattanBox))
}
"An arbitrary point (1,1)" must "be inside a square ((0,0),(2,0),(2,2),(0,2))" in {
assert(PointInPoly.isPointInPoly(1.0, 1.0, Seq(Seq(0,0), Seq(2,0), Seq(2,2), Seq(0,2))))
}
}Whether you are using an IDE or the command line, the instructions on preparing the built.sbt file and running the tests are available on the official Scala website. ScalaTest can be used from sbt, but make sure to include the libraryDependencies += "org.scalatest" %% "scalatest" % "3.0.5" % "test" line in the build.sbt file. Running all tests should now display the above three tests passing. Those unit tests only verify the most important logic, more tests could be written.
Strategies for testing Spark
All Spark tests need a SparkSession, the entry point of any Spark program. There are various strategies to test the SparkSession:
- Initialize the
SparkSessionand destroy it in between every single test with ScalaTest’sBeforeAndAfterEach - Group tests to test suites; initialize the
SparkSessionand destroy it in between each test suite with ScalaTest’sBeforeAndAfterAll - Leverage the spark-testing-base library and reuse the
SparkSessionwith ease - Use Spark’s native SharedSparkSession that is available from Spark 2.3
In any of those strategies, the tests are run locally. A Spark application in production is executed on multiple nodes in a cluster. Distributed applications need additional testing. For example, whether the code running on executors was parallelized correctly is an important matter.
Still, the execution on a local machine ensures that the application executes accordingly to the desired logic and complies to the specification. A streaming application processes data as events, but its logic could be unit tested as a Spark batch application. After all, both the batch and the structured streaming processing leverage the same Spark SQL engine and share the same API.
Rewrite of the Taxi data cleaning code
In the part 1 and 2 of this article, the first processing step executed on the Taxi data was about data cleaning. The purpose was filtering out Taxi rides that started or ended outside of NYC. The code below implements this in Scala and should be saved as “src/main/scala/com/adaltas/taxistreaming/processing/TaxiProcessing.scala” in the com.adaltas.taxistreaming.processing package.
package com.adaltas.taxistreaming.processing
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.functions.col
object TaxiProcessing {
def cleanRidesOutsideNYC(dfRides: DataFrame): DataFrame = {
val lonEast = -73.7
val lonWest = -74.05
val latNorth = 41.0
val latSouth = 40.5
dfRides.filter(
col("startLon") >= lonWest && col("startLon") <= lonEast &&
col("startLat") >= latSouth && col("startLat") <= latNorth &&
col("endLon") >= lonWest && col("endLon") <= lonEast &&
col("endLat") >= latSouth && col("endLat") <= latNorth
)
}
}Others processing on the Taxi data developed in the first part could be rewritten as additional functions in the TaxiProcessing object. We shall test only the cleaning of the Taxi data and consider the source code ready.
We want to test that applying the processing on a DataFrame returns the expected result. A SparkSession is needed to handle the DataFrame and data to process with expected results. From the Spark testing strategies described previously, the second one will be incorporated.
The preparation for Spark unit tests on Taxi Data
Let’s prepare a test suite “src/test/scala/com/adaltas/taxistreaming/processing/TaxiProcessingTest.scala” that tests main processing logic on the Taxi Data. To run any tests relying on DataFrames, Spark is needed. As a mean of providing SparkSession, a trait SparkTestingSuite is defined. It extends the ScalaTest’s FlatSpec and BeforeAndAfterAll.
package com.adaltas.taxistreaming.processing
import org.scalatest.{BeforeAndAfterAll, Suite}
import org.apache.spark.sql.SparkSession
trait SparkTestingSuite extends FlatSpec with BeforeAndAfterAll { self: Suite =>
var sparkTest: SparkSession = _
override def beforeAll() {
super.beforeAll()
sparkTest = SparkSession.builder().appName("Taxi processing testing")
.master("local")
.getOrCreate()
}
override def afterAll() {
sparkTest.stop()
super.afterAll()
}
}Now, any traits extending SparkTestingSuite will gain access to the Spark session through the sparkTest variable.
Tests should be simple and short, hence the boilerplate code in tests should be avoided. The trait TaxiTestDataHelpers defined below provides helper functions to create datasets and generate DataDrames that individual unit tests could use. Consequently, it strips the repetitive code. Note, the TaxiTestDataHelpers trait extends the SparkTestingSuite, providing access to the Spark session.
import org.apache.spark.sql.Row
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import java.sql.Timestamp
trait TaxiTestDataHelpers extends SparkTestingSuite {
private val taxiRidesSchema = StructType(Array(
StructField("rideId", LongType), StructField("isStart", StringType),
StructField("endTime", TimestampType), StructField("startTime", TimestampType),
StructField("startLon", FloatType), StructField("startLat", FloatType),
StructField("endLon", FloatType), StructField("endLat", FloatType),
StructField("passengerCnt", ShortType), StructField("taxiId", LongType),
StructField("driverId", LongType))) // "yyyy-MM-dd hh:mm:ss" e.g. 2013-01-01 00:00:00
def getDataRides(): List[String] = {
List(
"6,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.866135,40.771091,-73.961334,40.764912,6,2013000006,2013000006",
"11,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.870834,40.773769,-73.792358,40.771759,1,2013000011,2013000011",
"55,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.87117,40.773914,-73.805054,40.68121,1,2013000055,2013000055",
"31,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.929344,40.807728,-73.979935,40.740757,2,2013000031,2013000031",
"34,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.934555,40.750957,-73.916328,40.762241,5,2013000034,2013000034"
)
}
def convTaxiRidesToDf(inputData: List[String]): DataFrame = {
val rdd = sparkTest.sparkContext.parallelize(inputData) // RDD[String]
val rddSplitted = rdd.map(_.split(",")) //RDD[Array[String]]
val rddRows: RDD[Row] = rddSplitted.map(arr => Row(
arr(0).toLong, arr(1), Timestamp.valueOf(arr(2)), Timestamp.valueOf(arr(3)),
arr(4).toFloat, arr(5).toFloat, arr(6).toFloat, arr(7).toFloat,
arr(8).toShort, arr(9).toLong, arr(10).trim.toLong)) //rowRideRDD
sparkTest.createDataFrame(rddRows, taxiRidesSchema)
}
}The build.sbt file needs additional setup for Spark. Forking must be enabled to run Spark in a separate JVM. By default, the code runs on the same JVM as sbt which creates a risk that Spark will crash sbt. Overall, the project is build with the sbt configuration as below:
name := "taxi-streaming-scala"
scalaVersion := "2.11.12"
fork in Test := true
libraryDependencies += "org.scalatest" %% "scalatest" % "3.0.5" % "test"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.1"
libraryDependencies += "org.apache.spark" %% "spark-hive" % "1.5.0"
libraryDependencies += "org.apache.spark" %% "spark-hive-thriftserver" % "2.4.1"It’s also useful to hide INFO log level messages from tests. This could be done by copying Spark’s conf/log4j.properties.template file to “src/test/resources/log4j.properties” and changing the line:
log4j.rootCategory=INFO, consoleto:
log4j.rootCategory=WARN, consoleTesting the Taxi processing with Spark
Once the SparkTestingSuite and TaxiTestDataHelpers traits prepared, Spark unit tests on Taxi analytics could be written quickly and concisely. The testing of the data cleaning related to the east side of NYC is covered here. On the image below, there is a bounding box of NYC (minus Staten Island borough). Since the parameters are coordinates, the meaning of the corner and edge cases is easy to see.
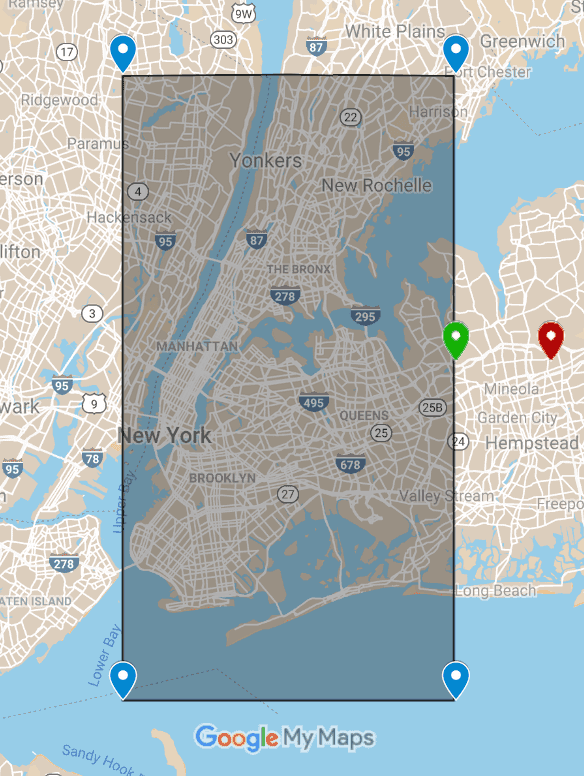
- A ride starting outside NYC (red) should be confirmed to be filtered out
- A ride starting on the east edge of NYC (green) needs to be kept
- Writing tests for edges of the box assures that all rides with geo coordinates within the box will be kept too. The same approach to testing holds for any other parameters, including temporal ones, financial data etc.
Two illustrative unit tests corresponding to the east edge case are written in the code below. The identical approach could cover the north, west, and south cases.
class TaxiProcessingTest extends TaxiTestDataHelpers {
"A ride starting OUTSIDE the east edge of NYC" should "be filtered out" in {
val dfRides = convTaxiRidesToDf(getDataRides() :+
"-1,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.6,40.771091,-73.961334,40.764912,6,2013000006,2013000006"
// ride with -73.6 startLon appended is outside east edge of NYC and should be filtered out
)
assert(TaxiProcessing.cleanRidesOutsideNYC(dfRides).count() === 5)
}
"A ride starting ON the east edge of NYC" should "not be filtered out (edge case)" in {
val dfRides = convTaxiRidesToDf(getDataRides() :+
"-1,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.70001,40.771091,-73.961334,40.764912,6,2013000006,2013000006"
// ride with -73.70001 startLon appended isn't outside NYC, it's an edge case that should work
)
assert(TaxiProcessing.cleanRidesOutsideNYC(dfRides).count() === 6)
}
}The rest of the logic of the streaming query could be added in TaxiProcessing.scala and tested in the same fashion by adding new functions to the TaxiProcessingTest class and utilizing another helper functions in the TaxiTestDataHelpers trait.
- The logic of the stream-stream join could be tested. Without a real stream, a test suite could, for example, mock the rides with specified timestamps to verify that rides which violate the join time constraints are rejected
- The aggregate results could be verified. For instance, a test could mock one hour of rides, calculate, and compare the
avg("tip")for each time window - The feature engineering section could be tested very similarly.
SparkTestwould need to be used to create an instance of the explicit broadcast variable - The function
parse_data_from_kafka_message()from the first article in the series could be tested with mock DataFrames, without any dependencies on Kafka
Scala Linters
Linters are tools used to analyze code for potential programming and stylistic errors. The use of linters is considered as a good practice in the software development process. The examination of the source code with linters is important to identify as many code smells and suspicious code constructs as possible before the application goes into production. Linters have more uses than only avoiding errors. Linter rules can enforce a unified format and compliance with project-specific style guidelines. The consistency in the applications’ code is especially important in enterprises, where numerous people from various teams collaborate within a single project.
Scalafix is a Scala linter which runs after the compilation. Firstly, it statically analyses the source code to find bad patterns specified by the linter rules. Secondly, Scalafix corrects the issues it found through refactoring.
To install Scalafix, add the line below in the “project/plugins.sbt” file:
addSbtPlugin("ch.epfl.scala" % "sbt-scalafix" % "0.9.5")As an example, consider the RemoveUnused Scalafix rule. Before running the linter, add the following options in the build.sbt file:
addCompilerPlugin(scalafixSemanticdb) // enable SemanticDB
scalacOptions ++= List(
"-Yrangepos", // required by SemanticDB compiler plugin
"-Ywarn-unused-import" // required by `RemoveUnused` rule
)Scalafix can be launched through sbt with a command:
sbt "scalafix RemoveUnused"If any unused imports in the project’s code have been found, they are automatically removed by Scalafix. Other built-in rules can be used, as well as custom rules could be implemented.
An alternative to Scalafix is WartRemover, which is a lint-on-compile type of linter. Since it runs at the compile time, it’s considered interactive and flexible. Another advantage of WartRemover is a richer set of built-in rules, denoted warts.
Other linters include Scalafmt and scalastyle which, while providing limited features, integrate with IntelliJ IDEA, one of the most popular IDE for Scala development.
Code coverage
The test suite must cover all the code and its supporting features. The appropriate test coverage of the code is important. A high percentage of the source code being tested is a good indicator that the application will work as expected, but it’s not the ultimate metric describing the quality of the application. If the tests were written for the sake of testing, high test coverage is delusional. Above all, tests should be meaningful and verify the expected functionalities.
Code coverage can be measured according to various criteria. A classic metric is the line coverage, which indicates how many percents of the code lines has been tested. Other examples are function coverage, branch coverage, and statement coverage. Scala isn’t a verbose language. It could have multiple statements on a single line. Thus, testing Scala code according to statement coverage provide a more accurate results than using an approach based on the line coverage.
Many IDEs provide code coverage measuring features. For example, IntelliJ IDEA has its code coverage runner or can use external runner such as JaCoCo. Code coverage measurement with IntelliJ IDEA has two main drawbacks. Firstly, only classes, methods, and lines are used as code coverage metrics, while the statement coverage is more suitable for Scala. Secondly, IntelliJ’s code coverage tools can be used only in the development environment, while the code coverage indicator can be useful within the whole chain of the software life cycle.
Measuring the code coverage with sbt-scoverage
Scoverage is a code coverage tool for Scala that uses statements and branches as code coverage metrics. Scoverage is a scalac compiler plugin which needs to be used with a build plugin. For example, sbt-scoverage is a plugin for sbt that integrates the scoverage library. Another benefit of using scoverage is its support for SonarQube and Jenkins. One can enforce code coverage tests in CI and analyze the results continuously in SonarQube.
Before running tests with sbt-scoverage, add the addSbtPlugin("org.scoverage" % "sbt-scoverage" % "1.5.1") line in “project/plugins.sbt” file.
The command below runs all the tests with coverage and generates a report:
sbt clean coverage test coverageReportThe locations of HTML and XML reports generated by scoverage are indicated by sbt after running tests. An example HTML report that can typically be found in the “scoverage-report” directory is presented below:
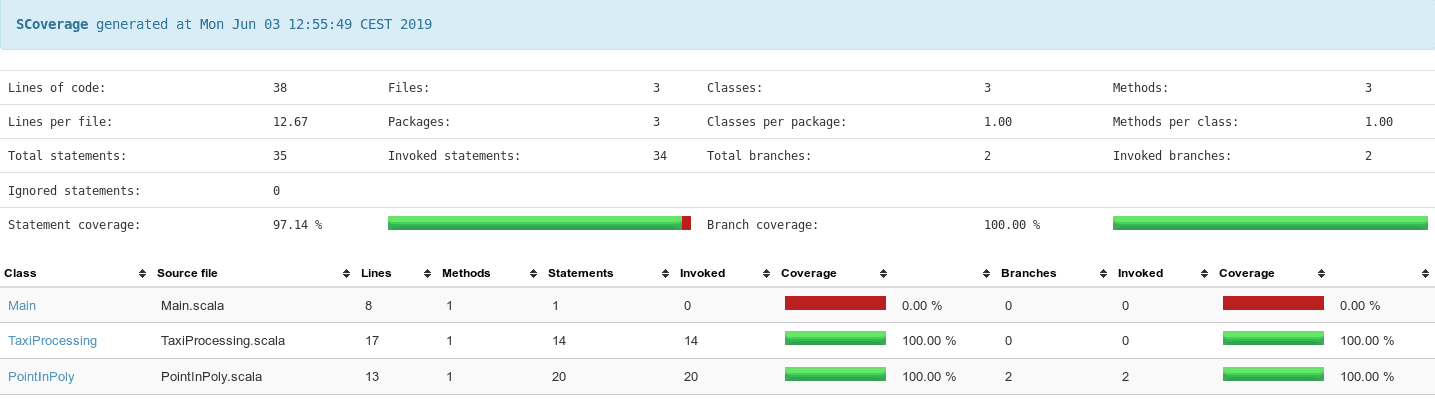
The report shows that all the statements in the source code developed in this article were invoked during tests. If the static reports aren’t sufficient, Scoverage can be used with SonarQube to provide code coverage results for continuous inspection within SonarQube.
Conclusions
Testing in software engineering is important, as in any other engineering project. Automatic unit testing is the most fundamental approach to test software. The tests must be short, isolated, and precise. With an adequate testing strategy, a Spark application could be tested almost as easily as a regular application. This article demonstrated how Spark unit tests could be written on the example of the Spark code developed in previous parts of the series. To rewrite and test the remaining source code from the previous parts, the presented methodology would remain the same.
