


Druid and Hive integration

Jun 17, 2019
- Categories
- Big Data
- Business Intelligence
- Tech Radar
- Tags
- LLAP
- OLAP
- Druid
- Hive
- Data Analytics
- SQL [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
This article covers the integration between Hive Interactive (LDAP) and Druid. One can see it as a complement of the Ultra-fast OLAP Analytics with Apache Hive and Druid article.
Tools description
Hive and Hive LLAP
Hive is an environment allowing SQL queries on data stored in HDFS. The following executors can be configured in Hive:
- Map Reduce
- TEZ
- TEZ + LLAP
LLAP is a cache system specifically built for Hive. It is a long-running service executed in YARN (via Slider). This architecture allows Hive to serve queries without instantiating new execution contexts in order to not slow the response time (hence it’s name Hive Interactive). Additionally, setting up a mutualised cache for all the users allows optimal use. However, LLAP still has some flaws:
- LLAP is used in fair mode where the tasks receive, on average, an equal share of the resources over time but does not allow to manage the resources finely regarding the users (low multitenancy).
- RAM memory reserved for the LLAP daemons, often large, is wasted when HIve LLAP is not requested.
Druid
Druid is a open source, distributed, column-oriented data store designed to quickly query (sub-second) events and historical data. It enables very low latency (near real-time) data ingestion and fast aggregations. The presence of inverted indexes makes Druid an excellent choice for data filtering. It is therefore a suitable tool for BI (aggregations, inverted indexes,) and time series (fast ingestions, aggregations).
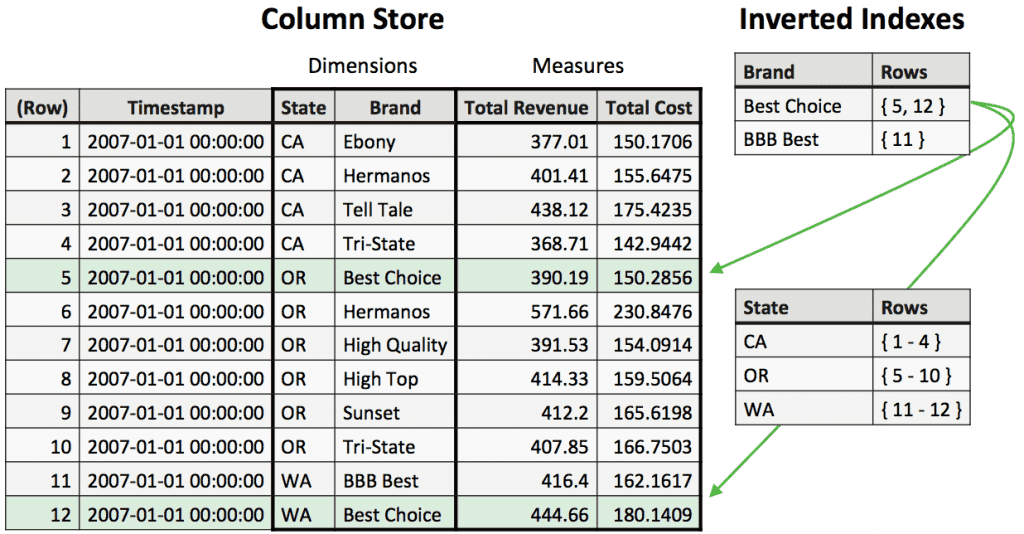
Nevertheless, Druid is not a good candidate to execute complex queries, such as joins.
Why integrate Druid with Hive LLAP?
Hive and Druid are two Big Data column-oriented tools and their features are complementary:
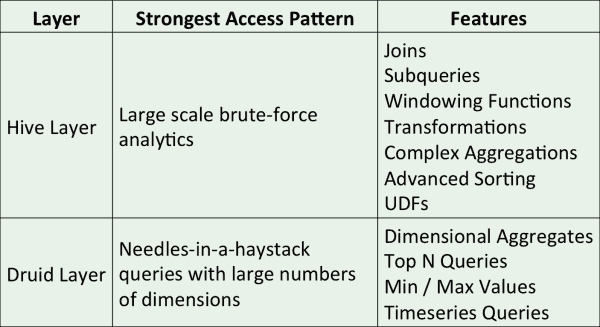
- Taking advantage of inverted indexes in Druid for queries of type “find a needle in a haystack”. In general, Hive is not performing well for this type of request because it does not have an index system.
- Use an SQL API on top of Druid. Queries in Druid are in JSON format and pass through its REST interface. Once the Hive table declared, the user will be able to query Druid via SQL (passing by Hive).
- Allow complex operations on Druid data. Druid is not suitable for joining tables, which Hive does very naturally.
- Indexing complex query results in Druid. Declaring a Druid table in Hive allows Hive to be able to store the result of a query directly in Druid, and to be able to query this dataset. This is especially used for the materialization of views (HIVE-10459) and the construction of OLAP cubes.
How does it work?
Hive is agnostic about the data source. Any system can be queried as long as a serialization/deserialization class and a schema are provided. It is precisely the addition of the class org.apache.hadoop.hive.druid.DruidStorageHandler, since Hive 2.2 (backported in Hive 2.1 by Hortonworks), which takes care of the reading/writing. The scheme, as for any Hive table, has to be provided by the user.
Currently, Druid presents itself as a data provider. The computation is done by Hive. However, it is planned that, in the upcoming releases of Hive, the computation engine of the plan (Calcite) will be able to push some calculations in Druid.
Installation
For this demo, we will use a virtual machine with HDP 2.6.4.0 installed and only the services needed had been activated:
- Zookeeper
- 1 znode
- HDFS
- 1 namenode
- 1 datanode
- YARN
- 1 resourcemanager
- 1 nodemanager
- Hive
- 1 Hive metastore
- 1 Hiveserver2
- 1 Hiveserver2 Interactive
- Druid
- 1 Druid Broker
- 1 Druid Coordinator
- 1 Druid Overlord
- 1 Druid Router
- 1 Druid Historical
- 1 Druid MiddleManager
Hive
Hive Interactive (LLAP) needs to be installed in order to interact with Druid. Let’s allocate 32GB of RAM to the YARN nodemanager of this machine. Hive LLAP is configured with one daemon node and 20GB of cache memory. For further information about the Hive LLAP installation, one can navigate to this LLAP sizing and Setup article.
Druid
Since we use a single machine, all services have been collocated. Overall, 24GB of RAM was allocated to Druid. The distribution was calculated to respect the proportions specified by the Druid documentation.
The deep storage is configured in HDFS.
Star Schema Benchmark
The Stark Schema Benchmark is a test bench for the performance of BI-oriented databases, and based on the TPC-H.
One can download the SSB-hive-druid project which allows to:
- Generate CSV honoring the SSB schema through a MapReduce job running ssb-dbgen.
- Inject these CSV in HDFS,
- Declare those CSV as external tables in Hive,
- Copy the data in an optimized format (ORC),
- Execute benchmark queries in Hive,
- Generate the data in Druid
- Execute the queries on Druid and compare with previous results.
Edit the config file according to the target configuration:
SCALE=2 # numerical factor for the amount of data generated (≃ scale*200MB)
#HDFS
HDFS_WORKDIR="/tmp/ssb/${SCALE}n/" # Temporary folder of the CSV files
# HIVE
HS2_URI='jdbc:hive2://localhost:10001/' # URI JDBC for Hive
HIVE_WH='/apps/hive/warehouse' # HDFS folder populated by Hive tables
RAW_DB="ssb_${SCALE}n_raw" # name of the DB containing the external tables pointing on the CSV files
ORC_DB="ssb_${SCALE}n_orc_flat" # name of the DB containing ORC optimised & copied from the RAW_DB
# DRUID
META_URI='jdbc:postgresql://localhost:5432/druid' # metastore druid
META_USERNAME='druid' # druid metastore username
META_PASSWORD='druid' # druid metastore password
BROKER_ADDR='localhost:8082' # druid broker address
COORDINATOR_ADDR='localhost:8081' # druid coordinator address
BEELINE=beeline -u "${HS2_URI}" # Beeline command to execute. The auth parameter can be added regarging Hive configurationThe ssb-dbgen compilation requires the following dependencies:
- make
- gcc
- javac
- maven
The path HDFS_WORKDIR must not exist before the data generation. Once the dependencies are installed, start the compilation and the data generation in HDFS and Hive with the script. The data generation needs the following configured paquets:
- hdfs
- yarn
- beeline
Data generation
In order to check all the dependencies, run the script:
./00_check_dependencies.shHive
The compilation and data generation are done by executing the following script:
./01_datagen.shNote that the execution will be ignored if the ORC_DB already exists.
This step does not require Hive LLAP. On the other hand, the data is generated by a MapReduce job. YARN must therefore be able to instantiate an Application Master as well as at least one container. If the resources are limited, one can shut down LLAP to free resources consumed by its daemons.
In this last case, an uninteractive HiveServer2 (without LLAP) needs to be launch in order to create the different databases and declare the external tables. The JDBC URI HS2_URI needs to be adapted consequently.
WARNING: If the YARN job fails with an error of type “Buffer Overflow”, it is because the glibc versions is not compatible with the parameters used to optimize the compilation. To correct this bug, edit the ssb-generator/ssb-dbgen/makefile file and delete the -O parameter from the CFLAGS (line 17).
Once the ./O1_datagen.sh script is terminated, connect to Hive (via beeline for example) and verify that the following tables are available in the RAW_DB and ORC_DB databases:
- customer
- dates
- lineorder
- part
- supplier
The number of lines depends on the SCALE parameter and must be identical from one database to another.
Once the creation and the feed of the ORC_DB database are completed, it is possible to delete RAW_DB and the files in /tmp/ssb/.
Druid
The data generation in Druid is done by executing the following script:
./02_load_druid.shThis step can take a while. As an example, the construction of 10GB Druid data (scale=50) took 4 hours and 33 minutes on our test machine. Nevertheless, the job was not well distributed in our case because the tests were executed on a single machine. Using a multi-node Hadoop cluster should significantly improve performance.
Once the ./O2_load_druid.sh is complete, connect to Hive and verify that the table ${ORC_DB}.ssb_druid is available.
The Druid segments are saved on HDFS, at the following path: ${HIVE_WH}/${ORC_DB}.ssb_druid. Be careful, Druid segments are not stored in the folder of the ORC database (${HIVE_WH}/${ORC_DB}.db/).
Benchmark execution
Benchmark queries can be found in the queries folder. Each query is declared in two versions, one will query Druid (druid sub-folder) and the other will query the ORC tables (hive sub-folder).
All queries can be executed via the following scripts:
./03_run.sh # execute all the queries on the ORC tables
./04_run_with_druid.sh # execute all the queries on the Druid segmentsIt is not mandatory to feed Druid (./O2_load_druid.sh) before the execution of the ./O3_run.sh script.
Those scripts will output the duration of the processing once completed.
Results
The benchmark had been executed with several factors, from 2 to 50. It represents the execution time, in seconds, of all queries according to the size factor.
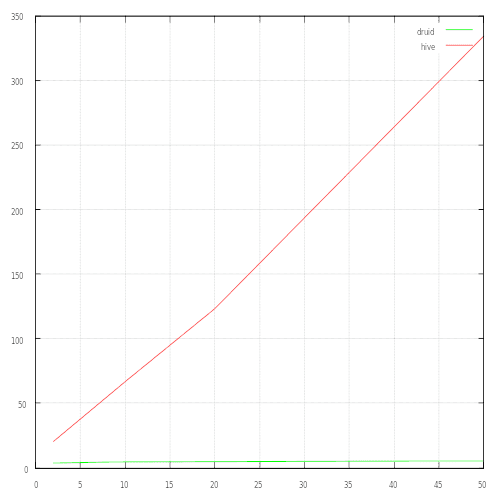
One can notice that the execution time of Hive is proportional to the size factor. It exceeds a minute starting with the factor 10 (2GB of data), and it takes 5 to 6 minutes of treatment for the factor 50 (10GB).
On the other hand, Druid’s performances are almost constant, with 1.2 sec of total time for the factor 2 (400MB) and 2.1 for the factor 50 (10GB).
Conclusion
While Hive was recently equipped with a cache engine (LLAP) capable of computing a query in less than a second, BI capabilities were limited to consulting pre-calculated data. Indeed, any query that is not pre-calculated and whose result is not in cache will be fully computed via the TEZ engine.
On the opposite, if the usage of Druid and Hive currently requires a batch export that can be long, Druid allows both to:
- Quickly serve a dimension through its timeseries-oriented storage,
- Provide its aggregated result, as these indicators are maintained by Druid.
The Hive + Druid couple finally seems to offer a complete solution to connect its BI tool to a Hadoop cluster. However:
- The integration between the two components is complex,
- Druid is a tool whose configuration is difficult and poorly documented,
- There are currently few feedbacks, except some proof of concept.
We cannot therefore conclude that it is a mature and turnkey solution, but it is already able to solve complex use cases adapted to experienced users. It is a promising combination as the two tools will become more mature and easier to handle over time.
