


TensorFlow avec Spark 2.3 : Le Meilleur des Deux Mondes

By HATI Yliess
29 mai 2018
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
L’intégration de Tensorflow dans Spark apporte de nombreux bénéfices et crée de nombreuses opportunités.
Cet article est basé sur une conférence du DataWorks Summit 2018 à Berlin. Cette conférence portait sur les nouvelles fonctionnalités de la nouvelle release 2.3 d’Apache Spark, un framework Big Data Open Source pour du calcul distribué sur clusters.
Étant donnée l’intérêt que j’éprouve pour le Deep Learning, je me suis demandé pourquoi je devrais utiliser une telle combinaison de softwares pour entraîner et utiliser mes modèles. Et, il se trouve que l’on peut profiter de la puissance de chacun des deux dans un grand nombre de cas d’usage. Mais, pour commencer, essayons d’abord d’utiliser un modèle de Deep Learning pour de la reconnaissance d’image en utilisant Tensorflow dans Spark 2.3.
Tensorflow
![]()
TensorFlow est la bibliothèque Open Source de Google dédiée au calcul numérique de haute performance. Prenant avantage de la puissance des GPUs, TPUs et CPUs, aussi bien sur serveur que sur cluster ou mobiles, elle est principalement utilisée dans les domaines du Machine Learning et plus spécifiquement du Deep Learning.
TensorFlow fournit un support pour le C++, le Python et plus récemment pour le Javascript avec TensorFlow.js. La bibliothèque en est déjà à la version 1.8 et embarque un wraper officiel du nom de Keras.
TensorFlow utilise Cuda et CudNN de Nividia pour communiquer avec les GPUs. Contrairement aux CPUs, les GPUs sont conçus pour le calcul parallèle et les opération matricielles, très présentes dans le Machine Learning, Deep Learning. Ainsi les traitements de données tirent profit de ces calculs parallélisés.
Etant donné la complexité de la multiplication Matricielle, voici un Benchmark. Essayons par la même occasion d’implémenter cette opération avec et sans Tensorflow.
Multiplication Matricielle
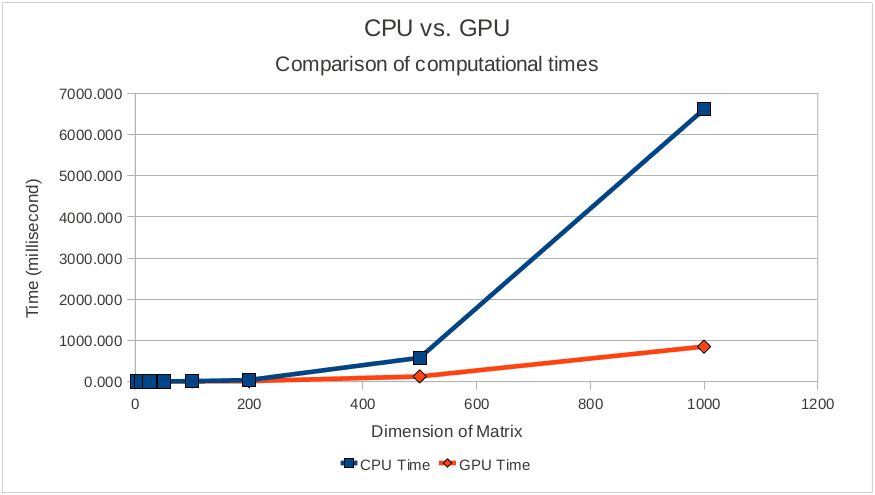
On constate que passée une certaine dimension, le temps de calcul d’une multiplication matricielle explose avec les CPUs alors que pour des GPUs il reste très bas.
Sans Tensorflow
import numpy as np
# Charger ou Générer la Data
m1 = np.random.normal(0, 0.2, size=(800, 800))
m2 = np.random.normal(0, 0.2, size=(800, 800))
# Evaluer
result = m1 @ m2
# Résultats
print(result)Avec Tensorflow
import tensorflow as tf
import numpy as np
# Charger ou Générer la Data
m1 = np.random.normal(0, 0.2, size=(800, 800))
m2 = np.random.normal(0, 0.2, size=(800, 800))
# Définition des Placeholder et Construction du Graph
M1 = tf.placeholder(tf.float32, shape=(800, 800), name='M1') # M1: matrix 28x28
M2 = tf.placeholder(tf.float32, shape=(800, 800), name='M2') # M2: matrix 28x28
output = tf.matmul(M1, M2)
# Evaluation du Graph
with tf.Session() as sess:
result = sess.run(output, feed_dict = {M1: m1, M2: m2})
# Résultats
print(result)Apache Spark
![]()
Apache Spark est un framework Open Source efficace et scalable dédié au Big Data. Il est reconnu pour sa capacité à faire des calculs lourds et distribués sur clusters avec un volume important de données. Il est à la fois simple d’usage et rapide. Plus simple qu’ Hadoop MapReduce, Spark permet de développer en Java, Scala, Python et R. Le framework est 100 fois plus rapide qu’Hadoop MapReduce.
Apache Spark est général. Il peut être utilisé en tant que moteur de requêtes SQL et peut aussi bien gérer du streaming avec Spark Streaming. En plus de cela, Spark embarque une bibliothèque de Machine Learning du nom de MLlib.
Le framework peut tourner sur des clusters Hadoop 2 avec YARN, Mesos, Kubernetes ou en standalone, et permet l’accès à des données de différentes sources telles que HDFS, Cassandra, HBase et Amazon S3.
Le nouvelle release 2.3 de Spark apporte de nombreuses fonctionnalités.
Charger des images à partir d’un système de fichiers
Voici un exemple de code pour charger des images à partir d’un système de fichiers :
from pyspark.ml.image import ImageSchema
# Chemin d'accès des Images
IMAGES_PATH = "datasets/image_classifier/test/"
# Création d'un DataFrame Spark pour les Images
images_df = ImageSchema.readImages(IMAGES_PATH)
# Afficher le DataFrame
images_df.show()TensorFlow x Apache Spark 2.3 : TensorFrame
Avec la release Spark 2.3, TensorFlow est supporté. On peut donc combiner la puissance des DataFrames, des Transformers et des Estimators à celui de TensorFlow et Keras.
from keras.applications import InceptionV3
# Charger inception v3 (Meilleur Classifier d'Images)
model = InceptionV3(weights="imagenet")
# Sauvegarder le model
model.save('/tmp/model-full.h5')
from keras.applications.inception_v3 import preprocess_input
from keras.preprocessing.image import img_to_array, load_img
import numpy as np
import os
from pyspark.sql.types import StringType
from sparkdl import KerasImageFileTransformer
# Paramètres
SIZE = (299, 299) # Taille acceptée par le model Inception
IMAGES_PATH = 'datasets/image_classifier/test/' # Chemin d'accès des Images
MODEL = '/tmp/model-full-tmp.h5' # Chemin d'accès du model
# Image Preprocessing
def preprocess_keras_inceptionV3(uri):
image = img_to_array(load_img(uri, target_size=SIZE))
image = np.expand_dims(image, axis=0)
return preprocess_input(image)
# Définition du Transformer Spark
transformer = KerasImageFileTransformer(inputCol="uri", outputCol="predictions",
modelFile=MODEL,
imageLoader=preprocess_keras_inceptionV3,
outputMode="vector")
# DataFrame d'Entrée
files = [fusion_builder_container hundred_percent="yes" overflow="visible"][fusion_builder_row][fusion_builder_column type="1_1" background_position="left top" background_color="" border_size="" border_color="" border_style="solid" spacing="yes" background_image="" background_repeat="no-repeat" padding="" margin_top="0px" margin_bottom="0px" class="" id="" animation_type="" animation_speed="0.3" animation_direction="left" hide_on_mobile="no" center_content="no" min_height="none"][os.path.abspath(os.path.join(dirpath, f)) for f in os.listdir(IMAGES_PATH) if f.endswith('.jpg')]
uri_df = sqlContext.createDataFrame(files, StringType()).toDF("uri")
# DataFrame de Sortie
labels_df = transformer.transform(uri_df)
# Afficher le DataFrame de Sortie
labels_df.show()Comme vous avez pu l’observer l’opération est plutôt directe. Il suffit juste de transformer le modèle en transformer ou en estimator.
Cas d’usage
Mais comment tirer profit de TensorFlow dans Spark ? Voici quelques cas d’usage :
Une des étapes les plus chronophages dans l’entraînement du modèle de Deep Learning est le choix des hyperparamètres. Un petit changement peut avoir de grandes conséquences, mais nous n’avons pas le temps de tester toutes les combinaisons possibles. Cependant, nous pouvons gagner du temps en utilisant TensorFlow. En effet, on peut réaliser du paramétrage de précision des hyperparamètres en associant à chaque noeud du cluster Spark différents paramètres, lancer les entraînements en même temps tout en effectuant une validation croisée pour ne garder que le meilleur.
En plus de tout cela, cette combinaison de logiciels est également utile au déploiement et à la scalabilité. Grâce à Spark, il est possible de pousser un modèle pré-entraîné sur les noeuds et ainsi distribuer la charge de calcul. Et il est aussi possible de monter en charge, si notre service se trouve saturé nous pouvons y ajouter un noeud.
Conclusion
Pour conclure, cette nouvelle release d’Apache Spark offre la possibilité d’appliquer les avantages du calcul distribué au domaine du Deep Learning/Machine Learning.
