


Deep learning sur YARN : lancer Tensorflow et ses amis sur des clusters Hadoop

24 juil. 2018
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Avec l’arrivée de Hadoop 3, YARN offre plus de possibilités dans la gestion des ressources. Il est désormais possible de lancer des traitements de Deep Learning sur des GPUs dans des espaces dédiés du cluster.
Cet article est basé sur une présentation de Wandga Tan, membre du PMC Apache Hadoop, lors du DataWorks Summit 2018. Il traite des possibilités offertes par le support des GPUs.
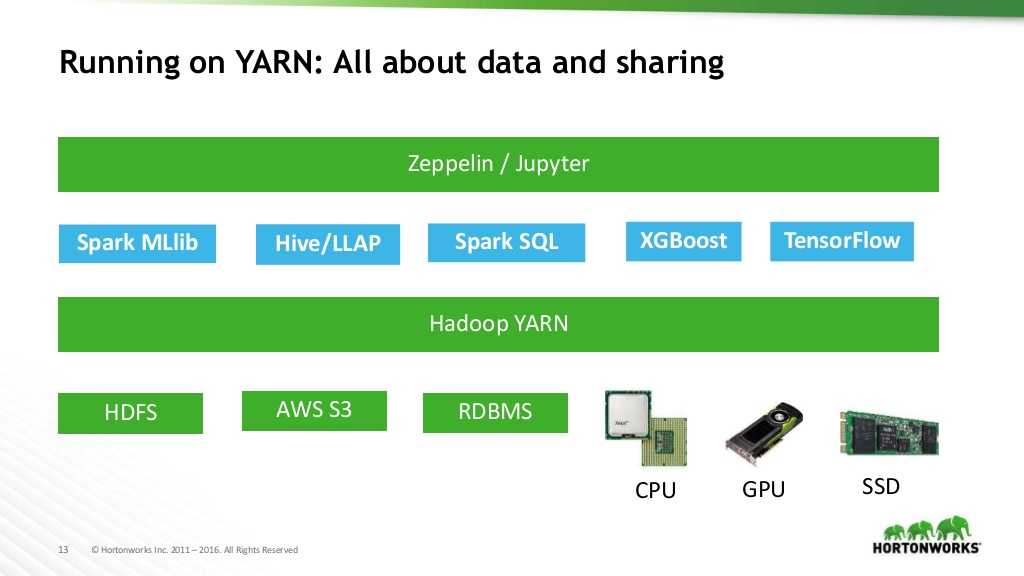
Le domaine de l’intelligence artificielle et ses technologies sous-jacentes telles que le Deep Learning ont attiré les projecteurs médiatiques ces dernières années. Hortonworks a suivi cette direction en enrichissant sa distribution par l’intégration de plusieurs frameworks de Deep Learning dans HDP 3. Bien sûr, les composants historiques permettant l’exécution de modèles de régression logistique ou d’apprentissage par renforcement dans Spark MLlib ou XGBoost demeurent disponibles. La grande nouvelle vient de la possibilité de lancer des modèles de Deep Learning de type “DNN”, “CNN”, “RNN”, “LSTM” au travers du célèbre framework TensorFlow et autres Apache MXNet et Pytorch.
Les traitements de Deep Learning bénéficient grandement de l’utilisation de GPUs grâce à leur forte densité en coeurs de calcul.
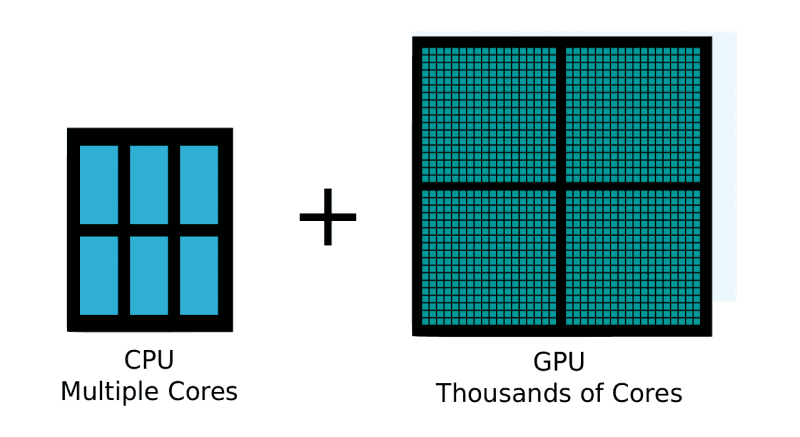
Sans le soutien du GPU, les chercheurs souffrent d’un temps d’attente beaucoup plus long.
YARN le gestionnaire de ressources d’Hadoop permet :
- De maintenir un niveau de services (SLA) grâce à ses capacités de planning, de préemption et d’allocation.
- Surveiller l’utilisation des ressources dans Grafana (HDP)
- D’organiser les files d’exécution (queues)
- D’isoler les CPUs, la mémoire, des GPUs ou les FPGAs
YARN fournit donc la possibilité de faire tourner la majorité des services Hortonworks sur une même plateforme. De plus, un ensemble de nœuds peut être dédié à une utilisation spécifique :
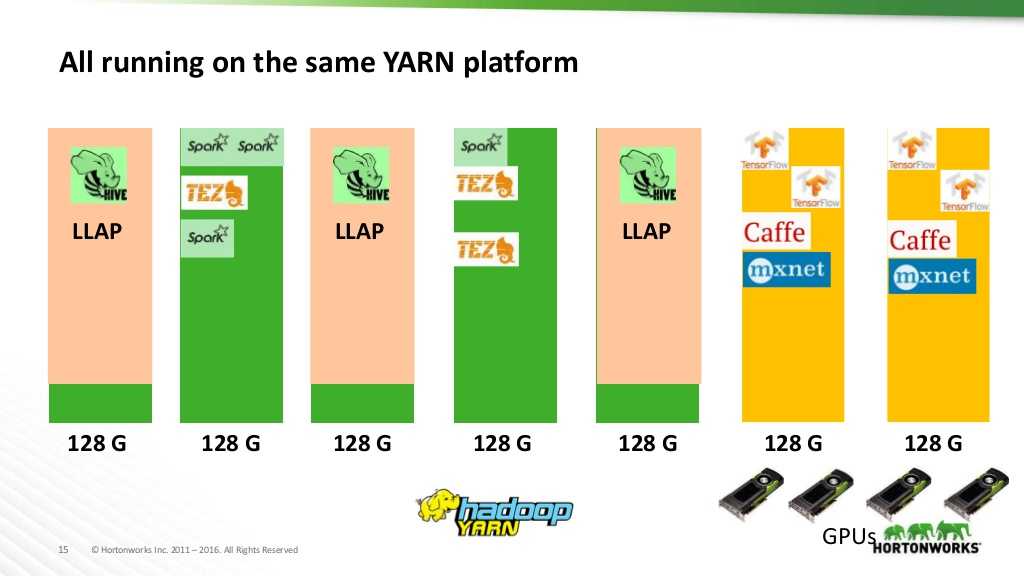
L’isolation des GPUs et l’orchestration ne sera pas tout de suite disponible dans la version Hadoop 3.0.0. Son support commencera à partir de la version 3.1.0. L’isolation des GPUs est nécessaire pour pouvoir mieux partager et gérer les ressources. Elle est réalisée à travers YARN avec une granularitéqui s’effectue par unité GPU. YARN utilise les CGroups et Docker pour mettre en place l’isolation.
Le Deep Learning est aujourd’hui en forte demande. De nombreuses entreprises considèrent l’intelligence artificielle comme une solution pour répondre à leurs besoins et introduire de nouveaux services. Aujourd’hui, un nombre important de solutions existent telles que Kubernetes, Mesos, Docker Swarm, OpensShift ainsi que quelques solutions propriétaires. On se demande si Hortonworks et la communauté Apache ne tardent pas à proposer Deep Learning sur la plateforme Hadoop. Néanmoins, cette intégration offre des possibilités intéressantes. Un cluster Hadoop peut être divisé entre des nœuds dédiés pour le stockage et d’autres nœuds dédiés à des usages de type DataLab, y compris de Deep Learning avec plusieurs machines embarquant des GPUs. En outre, Hortonworks offre un écosystème riche de solutions techniques et en bibliothèques.
