


Déploiement d'un cluster Flink sécurisé sur Kubernetes

By WORMS David
8 oct. 2018
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Le déploiement sécurisée d’une application Flink dans Kubernetes, entraine deux options. En supposant que votre Kubernetes est sécurisé, vous pouvez compter sur la plateforme sous-jacente ou utiliser les solutions natives Flink pour sécuriser votre application de l’intérieur. Notez que ces deux solutions ne sont pas mutuellement exclusive.
Utilisation de la sécurité native à Kubernetes
Des modèles de définition Kubernetes adaptés à Flink sont disponibles en ligne et constituent un point de départ fiable. Le déploiement du JobManager gère 1 réplica. Kubernetes est en charge du redéploiement en cas d’échec.
Isolation du réseau
Par défaut, tous les modules d’un cluster peuvent communiquer librement entre eux. Autrement dit, lorsqu’un Pod est démarré, il lui est attribué une adresse IP unique accessible depuis les autres Pods. En utilisant les Network Policies, il est possible d’isoler les services exécutés dans des Pods les uns des autres. Une stratégie réseau est un ensemble de règles de trafic réseau appliquées à un groupe donné de Pods dans un cluster Kubernetes. Il est possible de restreindre l’accès à un namespace Kubernetes ou aux modules constituant une application. Une fois les Network Policies appliquées, l’application sera isolée du monde extérieur.
Chiffrement et authentification
Cependant, les communications internes au cluster seront envoyées telles quelles. Il en va de même avec le monde extérieur. De plus, aucune stratégie d’authentification n’est mise en place. Pour chiffrer toutes les communications avec SSL, vous pouvez introduire une solution de Service Mesh comme Istio qui se déploiera de manière transparente tout en offrant des fonctionnalités supplémentaires : équilibrage de charge, surveillance ou résilience (réessai, délai, délais,…). L’utilisation d’une solution de Service Mesh est particulièrement intéressante lorsque votre application s’exécute sur un réseau sans confiance.
En outre, l’accès à l’application depuis l’extérieur ne fournit aucune authentification. Vous devez fournir un service pour authentifier les accès, qui peut également être implémenté avec une solution de maillage de service, ou refuser tout accès externe et direct à votre application en déployant un Pod de confiance en charge de la transmission par proxy des communications.
Cette dernière approche est similaire à celle décrite par Marc Rooding et Niels Dennissen d’ING dans leur exposé intitulé «Automating Flink Deployments to Kubernetes». Il y décrit leur chaîne de CD / CI qui pousse les instructions de déploiement et les ressources vers un Pod sécurisé ayant l’accès à leur application Flink.
Utilisation de la sécurité natives de Flink
Concernant la seconde approche, Edward Alexander Rojas Clavijo présente dans la session intitulée «Deploying a secured Flink cluster on Kubernetes» comment intégrer les solutions natives de Flink. Bien que relativement simple dans un environnement Hadoop YARN, SSL et Kerberos présentent tous deux des difficultés en raison de la nature dynamique de l’attribution des IP et de la résolution DNS dans un cluster Kubernetes.
Architecture
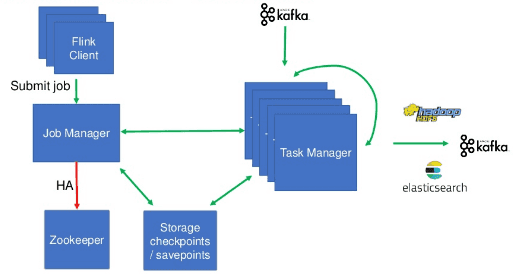
L’architecture décrite ci-dessous implique Kafka en tant que source et destination ainsi que HDFS et Elasticsearch en tant que destination.
Le service JobManager utilise un nom d’hôte dédié qui peut être référencé par les instances des TaskManagers ainsi que les scripts de soumission de jobs. Un Pod est assigné à chaque TaskManager. Le nombre de conteneurs est aligné sur le nombre de jobs. Les jobs sont de nature endless et stateful. Lors de la mise à jour, le TaskManager déploie un checkpoint.
L’utilisation des ConfigMap Kubernetes permet de générer la configuration de Flink, y compris la gestion de la mémoire et des checkpoints.
Communication sécurisée avec SSL
Par défaut, chaque communication dans Flink entre le JobManager et les TaskManagers effectue une validation du nom de l’hôte. L’approche traditionnelle impliquant la génération de certificats publics et privés pour chaque composant est difficile à intégrer avec une adresse IP et des noms d’hôte dynamiques. Cela nécessite de contacter un serveur PKI pour générer le certificat au démarrage du conteneur avant le démarrage du composant Flink.
Lors de la première itération, l’équipe a utilisé des certificats à base d’un “*” (Wildcard Certificate).
Le JobManager fut configuré en tant que ressource de service Les service dans Kubernetes obtiennent un nom d’hôte fixe et les communications sont acheminées vers le pod par Kubernetes.
Les taskManagers reposent sur des définitions du type Stateful Set. Les Stateful Set obtiennent des nom d’hôte prédiqués. Par exemple, le nom de domaine complet flink-tm-0.flink-tm-svc.namesapce.cluster.local définit l’instance TaskManager flink-tm-0 à l’intérieur du service flink-tm-svc dans l’espace de noms. namesapce. L’isolation de tous les TaskManagers à l’intérieur d’un seul nom de domaine permet de générer un certificat générique disponible pour le TaskManager.
Dans les Pods effectuant les soumissions, l’interface de ligne de commande n’est pas configurée pour effectuer la validation du nom d’hôte. L’autorité de certification doit être approuvée par le JobManager.
Une limitation rencontré dans l’utilisation de certificats génériques est que le déploiement de l’application Flink est restreinte à un seul espace de noms. Le déploiement dans un nouvel espace de noms signifie la génération d’un nouveau certificat.
La solution finale qui a été sélectionnée consiste à générer un certificat unique envoyé aux Truststores et Keystores la validation du nom d’hôte et des certificats désactivés.
À partir de la version 1.6, Flink peut effectuer une validation mutuelle qui est désormais l’approche recommandée pour Kubernetes. Le contenu et le mot de passe des Truststores et Keystores sont exposés en tant que secret Kubernetes, codés en base64 et montés dans les Pods.
Communication avec les sources et les destinations
Dans l’architecture présentée, l’application Flink communique avec Kafka, HDFS, et Elasticsearch.
Pour activer l’authentification Kerberos entre les composants Flink, il est nécessaire de fournir un accès aux fichiers Keytab à partir de chaque composant. Un Secret contient le fichier encodé en base64 qui est exposé à chaque Pod. Une ConfigMap est utilisé pour envoyer les propriétés Kerberos telles que les principaux de service.
Le protocole de sécurité Kafka est SASL_PLAINTEXT et requiert le nom du service Kerberos fourni par la ConfigMap.
Les divers certificats SSL des services sources et destinataires sont exposés en tant que Secrets montés sur des modules. Le fichier de définition DockerFile monte et garantit un droit d’accès à $JAVA_HOME/lib/security/cacerts qui contient les autorités de certification requises.
Le noeud final Elasticsearch est accessible via les requêtes REST. Ils ont créé un Sink personnalisé car la version de Flink antérieure à la version 1.6 est incompatible avec Elasticsearch dans la version 6. Dans leur client HTTP personnalisé, le vérificateur de nom d’hôte SSL a été invalidé.
Communication entre le TaskManager Flink et le volume physique Kubernetes
L’état de l’application Flink est persisté au travers d’un volume physique exposant un serveur NFS. Comme le NFS n’est pas capable de chiffrer les données, le chiffrement est géré au niveau de l’application. Cela répond à l’exigence de chiffrement en vol et au repos (non pris en charge nativement par NFS).
Les prochaines actions à mener
L’exposé s’est terminé sur les actions futures pour améliorer la sécurité du système :
– utiliser les règles d’accès RBAC
– Restreindre l’accès à kubectl
– Utiliser les Network Policies
– Pod security Policy
Il est aussi anticipé d’utiliser le Job Cluster Container Entrypoint présent dans Flink 1.6 qui incorpore à la fois le runtime Flink et l’application utilisateur dans un conteneur.
