


Apache Flink : passé, présent et futur

5 nov. 2018
- Catégories
- Data Engineering
- Tags
- Flink
- Pipeline
- Kubernetes
- Machine Learning
- SQL
- Streaming [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Apache Flink est une petite pépite méritant beaucoup plus d’attention. Plongeons nous dans son passé, son état actuel et le futur vers lequel il se dirige avec les keytones et présentations de la Flink Forward 2018.
Apache Flink est un moteur streaming in-memory. Il propose les fondations ainsi que les composants principaux permettant de mettre en place des traitements avec états (stateful) sur des streams de données entre de multiples sources et cibles et sur différentes plateformes :
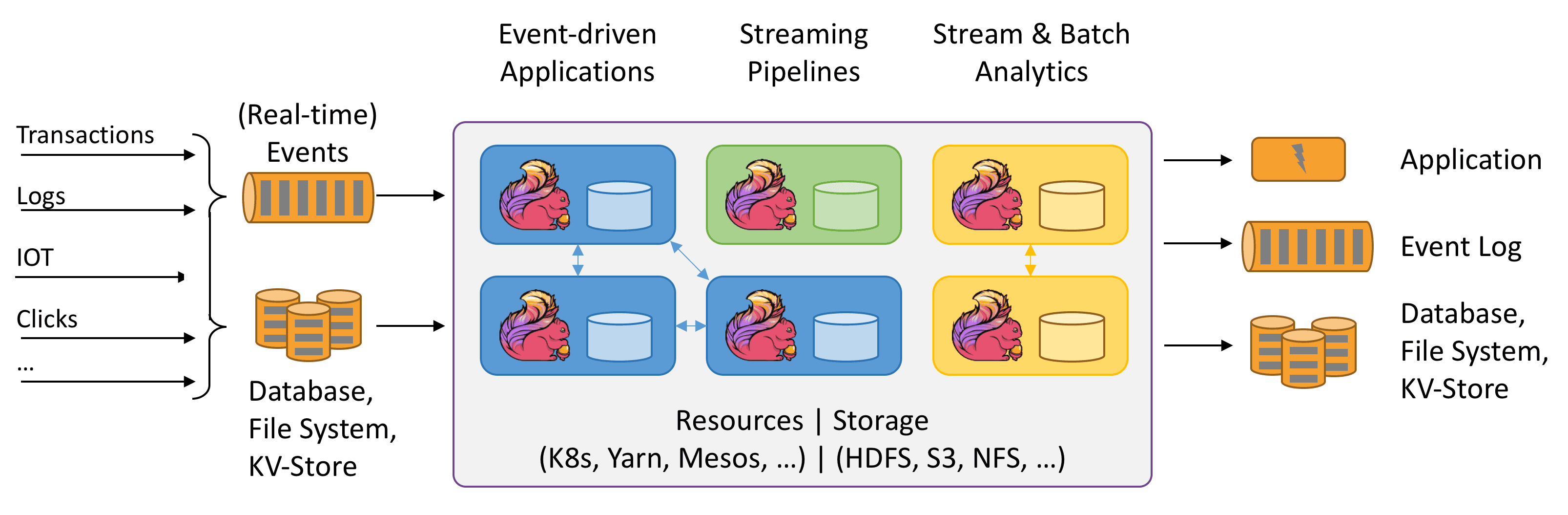
Passé
Tout a commencé en Août 2014 lorsque la version 0.6.0 de Flink est publiée en tant que processeur batch sur un environnement d’exécution stream. Précédemment le projet s’appelait StratoSphere, un projet de recherche académique initié en 2009 à l’Université Technique de Berlin.
La version 0.6 exposait les APIs DataStream (streaming) et DataSet (batch) utilisant un moteur de traitement streaming en pipeline. Cela signifie qu’un opérateur n’attend pas la fin du traitement de son prédécesseur pour commencer à traiter des données. On obtient alors un moteur très performant capable de traiter de très larges volumes de données avec une meilleure utilisation de la mémoire, le batch étant traité comme un cas spécifique du streaming où le stream est fini.
Flink acquit ensuite de nombreuses compétences améliorant l’expérience de streaming proposée.
Résistance à la panne et assurance “exactly-once”
L’API 0.9 introduit le concept d’état (state) et permit la création d’une nouvelle vague d’applications capable de se souvenir de ce qu’elle a reçu. En effet, il est facile de traiter la panne pour des jobs sans états (stateless) : il suffit de rejouer le jeu de donnée échoué ou perdu. Cependant cela devient plus compliqué pour des jobs distribués de longue durée avec état, il faut ré-initialiser l’état perdu. Flink apprit à se souvenir avec l’introduction de sauvegardes (snapshots) continues permettant de se remettre d’une panne et reprendre un état.
Néanmoins Flink est un moteur de streaming, et le concept de snapshot consiste à prendre une photo complète du système à un instant T et le persister dans un stockage durable, ce qui prend des ressources et ralentit les performances. Pour répondre à ce challenge, data Artisans implémenta la sauvegarde asynchrone avec des barrières (stream barriers) :

Des messages barrière sont injectés dans le stream, le découpant en groupes de messages, et lorsque la barrière atteint un opérateur, celui-ci créé une sauvegarde des messages du groupe en tant que checkpoint. Flink possède également des mécanismes afin de gérer la fusion de streams et la sauvegarde d’états.
En cas de panne, Flink sélectionne le dernier checkpoint complet, redéploie l’intégralité du dataflow distribué avec les états sauvegardés dans le checkpoint, et relance les sources à partir des positions du checkpoint.
Ce processus permet d’avoir un streaming haut débit avec une faible latence.
- SQL, Graph et Machine Learning
L’API 0.9 introduit également trois nouveaux modules :
- Flink SQL et la Table API ajoutant un nouveau niveau d’abstraction sur les sources de données et permettant aux utilisateurs d’exécuter des requêtes SQL-like sur des datasets distribués en mode batch et streaming.
- L’API Graph Gelly contient un set d’utilitaires qui encapsule un dataset sous forme de vertex et liens afin d’y appliquer des algorithmes de parcours de graph.
- La librairie Machine Learning inspirée de l’abstraction de transformeurs et prédicteurs de scikit-learn pour facilement mettre en place des pipelines de traitements machine learning avec plusieurs algorithmes existants.
Ces trois modules amenèrent Flink au niveau de son compétiteur, Apache Spark.
Suivi temporel
Le support de l’heure événementielle (event time) vint avec la version 0.10 de Flink. Les messages pouvaient maintenant être traités dans l’ordre dans lequel ils étaient émis, à condition qu’ils contiennent un timestamp. Cela concerne par exemple les logs, transactions financières et les données de capteurs.
Très souvent, les événements sont collectés depuis plusieurs sources et il n’est pas garanti qu’ils arrivent au traitement streaming dans l’ordre exact de leur timestamp. Par conséquent, les traitements doivent pouvoir prendre en compte les éléments désordonnés afin de produire des résultats corrects et consistants par rapport à leur création.
Flink apprit à comprendre l’heure événementielle ainsi que l’heure d’ingestion (ingestion time) et l’heure de traitement (processing-time) dans ses traitements. Par exemple, Flink peut traiter les films Star Wars dans plusieurs ordres :
- Heure de traitement : comme ils ont été créés, d’abord la trilogie originale (4, 5, 6), puis la prélogie (1, 2, 3), rogue one et enfin la nouvelle trilogie (7, 8 et 9 à venir).
- Heure évènementielle : définie par leur numérotation, d’abord la prélogie, puis rogue one, l’originale et enfin la nouvelle.
Présent
Tout cela nous amène à un moteur de traitement avec les atouts suivants :
- Continue et “temps réel”
- Avec états et exactly-once
- Haut début et faible latence
- Heure évènementielle et fonction de traitement
ainsi que de multiples niveaux d’abstraction :

Il est maintenant possible de développer des applications dites “data-driven” :
- Modélise et automatise le traitement, les problèmes et les opportunités.
- Opère en temps réel sur des sources (et cibles) de données multi-canaux.
- Supporte la variété des datasets structurés, semi-structurés et non structurés.
- L’information est exposée universellement au sein d’une seule application.
- Combine des capacités opérationnelles / OLTP et analytiques / OLAP.
- Basée sur les événements (event-driven), capable de réagir aux changements de son environnement.
Les versions 1.x ont capitalisé sur ces fonctionnalités existantes jusqu’à l’actuelle 1.6 :
- La sauvegarde incrémentale permet d’enregistrer des états beaucoup plus larges en ne stockant qu’un différentiel. À la preprise, les opérateurs sont lancés avec le dernier checkpoint complet puis les update incrémentaux sont appliqués.
- La reprise locale conserve sur le noeud Flink (TaskManager) une sauvegarde locale pour la résistance à la panne d’un noeud, plutôt que de reposer sur un backend de stockage plus lent.
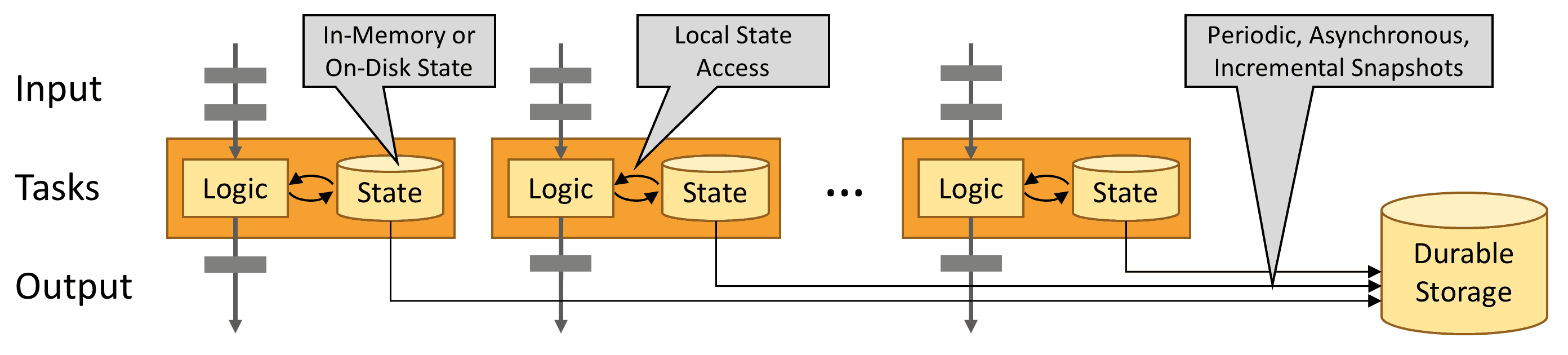
- L’élasticité permet à Flink de réagir à la disponibilité des ressources d’un cluster en scalant proportionnellement.
- Flink comme librairie et non plus seulement un framework permet de déployer une application aussi simplement qu’en exécutant un processus avec le code applicatif et les sources de Flink packagées ensemble.
- Flink SQL s’est vu grandement amélioré jusqu’à supporter la définition unifiée de sources et cibles en YAML, permettant à un utilisateur de lancer un job SQL avec une simple configuration YAML et une requête SQL via le client CLI, aucune connaissance de développement requise.
- Flink est indépendant d’Hadoop et supporte de plus en plus de technologies et plateformes, dont Kubernetes.
Futur
Convergence streaming et batch
Dans le contexte de Flink, l’API propose le traitement batch et streaming comme abstractions de même niveau d’un moteur commun, alors que l’API SQL permet d’avoir une sémantique unique sur des entrées batch et stream.
Flink se dirige vers une convergence des traitements batch et stream, aujourd’hui à travers l’API SQL et demain, avec un peu de chance, avec les APIs Java et autres langages supportés.
Un projet très intéressant sur le sujet est Blink et Alibaba, un fork du moteur Flink utilisant Flink SQL pour traiter de manière transparente et par les mêmes APIs réécrites du batch et du stream.
Détection de motif SQL
L’API SQL supporte déjà de nombreuses fonctionnalités. data Artisans travaille actuellement au support de la détection de motif dans les streams avec le SQL grâce à la clause MATCH_RECOGNIZE.
Elle permet de gérer des use-cases très communs tel que le suivi de marché boursier, les comportements utilisateurs, la poursuite de blanchiment d’argent, la vérification de qualité, la détection d’intrusion réseau, …
Prenons un exemple concret : nous avons un stream entrant de message sur des courses de taxis avec plusieurs informations comprenant un identifiant unique de course et un booléen indiquant le départ, sur lequel nous souhaitons faire de la détection de motif pour récupérer toutes les courses avec un arrêt intermédiaire.
Ce serait très compliqué à implémenter avec les fonctionnalités SQL existantes, même sur un dataset fini. Voici comment nous ferions avec MATCH_RECOGNIZE :
SELECT *
FROM TaxiRides
MATCH_RECOGNIZE (
-- specify grouping key
PARTITION BY driverId
-- specify ordering
ORDER BY rowTime
-- Extract measures from matched sequence
MEASURES S.rideId as sRideId
AFTER MATCH SKIP PAST LAST ROW
-- Construct pattern
PATTERN (S E)
DEFINE S AS S.isStart = true, E AS E.isStart = true
)Et avec plusieurs arrêts :
-- Set M as appearing at least twice
PATTERN (S M{2,} E)
DEFINE S AS S.isStart = true, M AS M.rideId <> S.rideId, E AS E.isStart = false AND E.rideId = S.rideId
)Au moment où cet article fût rédigé, la function MATCH_RECOGNIZE était expérimentale et hébergée sur un dépôt GitHub désormais disparu. Plus d’information sur la détection de motifs dans les tables est disponible sur le site de Spark.
Consistance d’états partagés
Flink Forward était l’occasion pour data Artisans d’annoncer leur nouvelle fonctionnalité qui va changer la donne pour les applications streaming : le ”Streaming Ledger“.
Dans un monde où la consistance est essentielle et vous devez être capable d’oublier ce que vous savez (GDPR !), c’est impossible à mettre en place sur des opérateurs de streaming. Il faudrait pouvoir :
- Accéder et mettre à jour des états avec plusieurs clés au même moment.
- Maintenir une isolation et une validité complète pour les opérations multi-clé.
- Opérer sur plusieurs états à la fois.
- Partager les états entre plusieurs streams.
Le Streaming Ledger fournit des garanties ACID sur plusieurs états, lignes et streams. C’est une librairie autonome s’intégrant de manière transparente avec les APIs DataStream et SQL de Flink afin d’assurer l’Atomicité, la Consistance, l’Isolation et la Durabilité des transactions.
Il ne s’agit pas d’une base de donnée relationnelle intégrée étant donné qu’il s’agirait simplement d’un re-packaging d’architectures existantes et ne répondrait pas aux besoins utilisateurs. Il utilise au contraire une approche nouvelle et unique :
- Ré-ordonnement des évènements & traitement dans le désordre
- Dataflows de streaming itératifs
- Horloge logique d’ordonnancement
Ce qui se traduit en un ré-ordonnancement des événements pour éviter les conflits à la persistance.
Nous vous encourageons à lire le whitepaper du Streaming Ledger pour mieux comprendre les concepts internes.
En terme de performances, les chiffres annoncés de cette première version sont très impressionnants (plusieurs centaines de milliers à plusieurs millions d’évènements traités à la seconde) et vont sûrement s’améliorer.
Une démo rapide montrait une infrastructure distribuée coordonnant des transactions entre l’Europe, le Brésil, les US, l’Australie et le Japon à environ 20K/mises à jour par seconde. Bien sûr, le système étant distribué il repose grandement sur la latence réseau et la distance réduit forcément les performances.
Le seul point négatif aujourd’hui est que le ledger est uniquement disponible en tant que librairie sur la plateforme data Artisans, ou en mode single-node pour du développement et test local sous license Apache 2.0.
Un monde de microservices
En prenant un peu de recul, on peut observer l’évolution du traitement de données comme suit :
- Vint d’abord le traitement batch hors ligne, lancé manuellement et en général en single node
- Puis apparu le Big Data avec des traitements distribués en map/reduce
- Et enfin l’architecture lambda, essayant de résoudre les problèmes de latences de map/reduce pour traiter les derniers événements
et plusieurs étapes dans les services :
- Client-serveur
- CORBA et DCOM
- EJB et architecture N-Tier (N étant 3)
- SOA et ESB
- HTTP-API et REST
Aujourd’hui, nous arrivons à des traitements streaming (presque) temps réels et des architectures dites “microservice”. On observe une convergence des deux sujets :
- Les systèmes réactifs doivent être disponibles (réactifs) même en cas de panne (résiliants) et de forte charge (élasticité) en étant orienté messages.
- Les streams réactifs fournissent un standard pour les streams asynchrones avec une “backpressure” non bloquante.
L’étape suivante serait de monter le service dans un état de stream, les commandes comme événements d’entrée et les messages de sortie comme réponses, insérant ainsi les microservices dans un stream de données :
- Ils seraient partie intégrante du pipeline de streaming.
- Un pipeline pourrait être exposé comme microservices.
- On pourrait implémenter la mise à jour indépendante de différentes parties du pipeline.
Flink est déjà capable de gérer ces points, il ne reste qu’à changer de perspective.
Conclusion
Nous avons maintenant une belle vue d’ensemble d’Apache Flink. C’est aujourd’hui une plateforme et un framework mature pour le développement d’applications data-driven et tend à devenir le standard par défaut pour les applications orientées événement.
Lectures complémentaires
Présentations Flink Forward :
- “The Past, Present and Future of Apache Flink” par Aljoscha Krettek (data Artisans) et Till Rohrmann (data Artisans)
- “Unified Engine for Data Processing and AI” par Xiaowei Jiang (Alibaba)
- “Detecting Patterns in Event Streams with Flink SQL” par Dawid Wysakowicz (data Artisans)
- “Unlocking the next wave of Streaming Applications” par Stephan Ewen (data Artisans)
- “The convergence of stream processing and microservice architecture” par Viktor Lang (Lightbend)
Liens :
- Flink Forward Berlin 2018 : https://berlin-2018.flink-forward.org
- Photo de couverture par Sven Fischer sur Unsplash
- StratoSphere : http://stratosphere.eu/
- Toutes les images du texte proviennent du site de Flink : https://flink.apache.org/
- Scikit-learn : http://scikit-learn.org/stable/
- Apache Spark : http://spark.apache.org
- Blink d’Alibaba : https://data-artisans.com/blog/blink-flink-alibaba-search
- Fonctionnalités Flink SQL : https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/sql.html#supported-syntax
- Streaming ledger : https://data-artisans.com/streaming-ledger
- Whitepaper streaming ledger : https://www.ververica.com/download-the-ververica-streaming-ledger-whitepaper
- Apache 2.0 license : https://www.apache.org/licenses/LICENSE-2.0
- Manifeste des systèmes réactifs : https://www.reactivemanifesto.org/
- Initiative streams réactifs : http://www.reactive-streams.org/
