


Jumbo, le bootstrapper de clusters Hadoop

29 nov. 2018
- Catégories
- Infrastructure
- Tags
- Ambari
- Automation
- REST
- Ansible
- Cluster
- Vagrant
- HDP [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Présentation de Jumbo, un bootstrapper de cluster Hadoop pour les développeurs.
Jumbo vous aide à déployer des environnements de développement pour les technologies Big Data. Il suffit de quelques minutes pour obtenir un cluster Hadoop virtualisé et personnalisé avec toutes les technologies dont vous avez besoin.
Dans cet article, nous allons passer en revue les raisons qui nous ont amenées à développer Jumbo, son fonctionnement et les raisons pour lesquelles vous pourriez l’utiliser.
Comment est né Jumbo ?
Chez Adaltas, nous travaillons avec les technologies Big Data, et pour fournir les meilleurs conseils possibles à nos clients, nous devons tester de nouveaux outils et de nouvelles architectures tous les jours. Pour cela, nous devons être capable de créer des environnements et de les provisionner rapidement.
Nous utilisons déjà un très bel outil écrit dans Node.js appelé Ryba qui permet de gérer de larges clusters multi-tenant, avec un réglage fin de chaque service installé. Mais s’il est parfait pour les environnements de production, Ryba n’a pas été conçu pour créer rapidement des clusters sur des machines virtuelles. Cela nécessite une connaissance de Node.js et de Ryba, et sa configuration pour chaque nouveau cluster prend du temps.
C’est pourquoi nous avons décidé de commencer un nouveau projet à partir de zéro, en gardant à l’esprit l’idée de simplicité : un outil simple à utiliser et à maintenir qui permet de créer rapidement des clusters basiques.
Machines virtuelles
Premièrement, nous avions besoin d’un moyen de gérer les machines virtuelles qui font office de nœuds du cluster Hadoop. Nous avons choisi d’utiliser Vagrant pour son moyen facile de configurer les machines virtuelles avec un seul fichier Ruby. Vous pourrez bientôt utiliser votre propre cluster virtuel, auquel Jumbo se branchera pour faire son travail.
Configuration des VMs et provisionnement
Nous devions également automatiser la configuration et le déploiement des services Big Data sur les VMs. Pour ce faire, Ansible a été choisi, car ses playbooks écrits en YAML offrent une grande lisibilité et sont donc pratiques à maintenir. Pour gérer l’installation de services de l’écosystème Hadoop, nous avons sélectionné Apache Ambari et Hortonworks Data Platform (HDP). Ambari offre un moyen de décrire avec précision la topologie du cluster, soit avec son API, soit avec son interface Web, et gère toutes les installations.
Outil Python
Enfin, pour assembler tous ces outils ensemble, nous avons développé un logiciel Python qui présente une interface simple à l’utilisateur (une CLI) et génère tous les fichiers de configuration nécessaires aux outils mentionnés ci-dessus. Nous avons nommé ce projet Jumbo, en l’honneur de la mère de Dumbo (car votre cluster Hadoop est un petit éléphant qui a besoin d’aide pour démarrer sa vie).
Comment ça marche ?
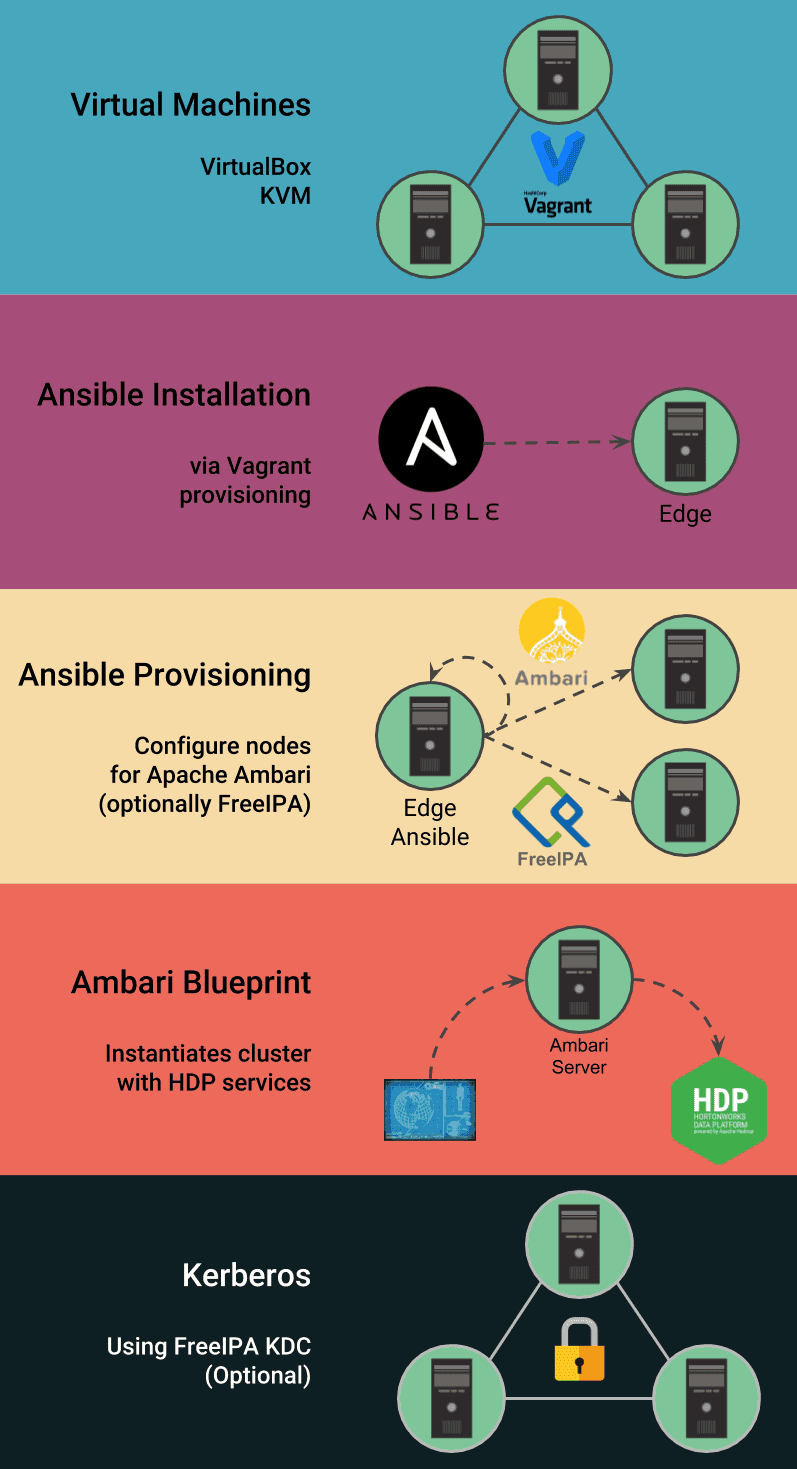
Jumbo génère tous les fichiers de configuration pour tirer parti des technologies suivantes :
- Vagrant : qui instancie les machines virtuelles et installe Ansible sur l’une d’elles ;
- Ansible : qui installe Ambari et ses dépendances, ainsi que FreeIPA / Kerberos (facultatif). L’API Ambari est utilisée pour le contrôle des blueprints et des services ;
- Ambari Blueprints : qui décrit la topologie du cluster et lance l’installation des services HDP via l’API Apache Ambari ;
- FreeIPA : qui fournit un LDAP ainsi qu’un KDC pour Kerberos.
Comment se présente Jumbo ?
Jumbo est un logiciel Open Source écrit en Python. Il est livré avec une interface en ligne de commande et offre une couche d’abstraction qui permet à tout utilisateur, expérimenté ou non avec les technologies Big Data, de décrire un cluster devant être provisionné. Lors de la configuration, Jumbo vous aide : il vous évite des erreurs d’architecture, fournit des modèles de clusters et installe automatiquement les dépendances qui vous sont inconnues.
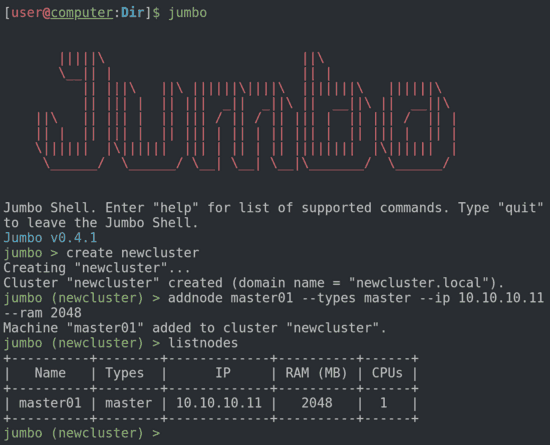
Jumbo s’occupe presque de tout : vous n’avez qu’à décrire les services que vous voulez, les machines sur lesquelles les installer et appuyer sur le bouton start (en fait, vous devez l’écrire, nous n’avons pas créé de bouton shell). Maintenant, vous pouvez vous détendre autour d’un café, et utiliser votre cluster entièrement fonctionnel une fois prêt.
Projets similaires
- Hortonworks Sandbox : cluster à un seul nœud avec services HDP ;
- Sandbox MapR : nœud unique avec les technologies Hadoop et MapR ;
- Cloudera QuickStart VM : nœud unique avec la distribution Cloudera de Hadoop.
Chacun de ces projets vise à découvrir les technologies spécifiques à Hadoop et à ses fournisseurs. Ils incluent des tutoriels pour apprendre les bases des technologies fournies.
Pour les utilisateurs plus avancés, il existe le repository hortonworks/ansible-hortonworks sur Github, mais ce projet nécessite une bonne compréhension d’Ansible et des Blueprints Ambari.
Pourquoi utiliser Jumbo ?
Les clusters Jumbo se rapprochent d’environnements réels. Ils sont multi-nœuds et peuvent être configurés avec Kerberos. Si vous souhaitez développer une application localement, il est judicieux d’avoir un cluster qui ressemble à votre environnement de production.
Avec des clusters multi-nœuds, vous avez également accès à un plus grand nombre de paramètres. Il peut être utile d’en savoir plus sur les optimisations, les services à haute disponibilité, etc.
Commencez à développer dès maintenant !
L’ensemble de la documentation Jumbo est disponible sur le site Web jumbo.adaltas.com. Ce projet en est à ses débuts et nous aimerions avoir votre feedback ! N’hésitez pas à poster des issues sur la page Github du projet.
Qu’est-ce qui attend Jumbo ?
Dans sa dernière version, Jumbo est capable de créer et de provisionner des clusters virtuels avec la stack HDP (Hortonworks Data Platform) et de les kérberiser à l’aide de Vagrant (avec VirtualBox ou KVM), Ansible et Ambari.
Dans les mois à venir, nous allons nous concentrer sur les fonctionnalités suivantes :
- Prise en charge complète de HDP (pour l’instant, seuls les principaux composants Hadoop sont présents dans Jumbo, bien que vous puissiez en installer d’autres après le provisionnement du cluster avec Ambari) ;
- Topologie de cluster intelligent - fournir la meilleure topologie de cluster possible basée sur les ressources disponibles de l’utilisateur (taille et nombre de VM, configurations des services) ;
- Provisionnement de machines virtuelles déjà existantes ;
- Prise en charge d’autres piles Big Data telles que HDF (Hortonworks DataFlow) ou CDH (Cloudera Distribution for Hadoop).
Un grand merci à Xavier Hermand qui m’a aidé à écrire cet article.
