


Automatisation d'un workflow Spark sur GCP avec GitLab

16 juin 2020
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Un workflow consiste à automiatiser une succéssion de tâche qui dont être menée indépendemment d’une intervention humaine. C’est un concept important et populaire, s’appliquant particulièrement à un environnement de production. Le client pour lequel je travaille actuellement utilise plateforme Google Cloud Platform (GCP) et son offre de produits et de services. Nous complétons la plateforme par nos propres outils. Entre autre, notre stack est composée de Gitlab CI pour l’automatisation des tests et des builds, Terraform pour le provisionnement des ressources GCP, ainsi que trois produits GCP que sont Cloud Composer (Apache Airflow) pour l’orchestratoin des applications Spark et Google Kubernetes Engine (GKE) pour l’hébergement du cluster.
Je trouve intéressant de développer et partager un projet impliquant des solutions et comment les exploiter dans un environnement de production. L’article est organisé ainsi :
- Création des projets GitLab et GCP
- Déploiement de ressources GCP avec Terraform
- Développement d’une pipeline de CI/CD pour effectuer plusieurs action relative au projet GCP
- Développement d’une application Spark
- Développement d’un workflow de type DAG
- Quelques remarques complémentaires
Ce projet et le code source le supportant sont conçut pour être utilisé comme un template. Il sera aisément ajustable à de nombreux cas d’usage. Il permet de découvrir et mieux appréhenser les outils listés précédemment. Toutefois, il ne faut pas le considérer comme prêt pour de la mise en production. Comme vous le verez par la suite, certain blocks de code contiennent une linge de commentaire #TODO qu’il conviendrait d’ajuster à votre contexte. Aussi la dernière section de l’article énumère plusieurs remarques pour renforcer la sécurité.
Chaque ressource GCP utilisées dans cet article fut créé avec l’offre d’essai équivalent à $300 fourni par GCP à ses nouveaux clients.
Création des projets GitLab et GCP
Pour plus de clarté, deux dépôts dans GitLab ont été créé pour gérer :
- Les fichier des ressources de déploiment Terraform et des configurations de workflow Airflow ainsi que les scripts Python associés aux workflows.
- Le projet SBT contenant l’application Spark.
Ensuite, un nouveau projet GCP doit être créé. Plusieurs actions manuelles sont nécessaires par la suite pour l’instanciation du cluster GKE et sa connection aux dépôts Gitlab.
Concernant GitLab, il est supposé que le lecteur possède un compte GitLab sur l’instance publique ou sur une instance privée. Une connaissance de base des commandes GIT est aussi requise. Si vous ne connaissez pas GIT, vous pouvez suivre se tutorial au préalable.
Dépôts GitLab
Nous créérons deux dépôts Git privés. J’ai nommé les miens tf_gcp_gitlab_project et spark_gcp_gitlab_project.

Une fois les dépôts créés, , les cloner locallement à l’emplacement désiré.
git clone https://gitlab.domain.com/ferdinand/spark_gcp_gitlab_project
git clone https://gitlab.domain.com/ferdinand/tf_gcp_gitlab_project
ls -l
drwxr-xr-x 4 ferdi ferdi 128 May 29 09:26 spark_gcp_gitlab_project
drwxr-xr-x 7 ferdi ferdi 224 May 29 12:15 tf_gcp_gitlab_projectUn pipeline CI est créée pour chacun des dépôts GIT. Elles sont déclenchées à chaque push sur le dépôt. Au déclenchement, des actions sont exécutées avec les modifications apportées lors des récents commits.
Projets GCP
Comme indiqué précédemment, toutes les opérations exprimées sont exécutable avec l’offre d’essaie GCP. Si vous n’en avez pas, créez un compte GCP. L’inscription requière quelques informations avant d’être activée et cela ne devrait pas prendre plus qu’une quinzaine de minutes.
Une fois que tout est en place, créez un nouveau projet en cliquant sur My First Project dans la barre de navigation en haut.

Sur la nouvelle page, créez sur NEW PROJECT en haut à droite. Fournissez un nom et concervez l’ID du projet qui est généré et qui s’affiche en dessous, spark-workflow-automation-k8s dans mon cas, et cliquez sur CREATE. L’opération devrait prendre quelques minutes avant que votre projet soit accessible puis sélectionnez le. Le nom du projet apparaît dans la boîte de sélection à côté des 3 points dans la barre du haut :

Vous êtes désormais prêt. Dans la barre de navigation, cherchez IAM & Admin. A gauche, sélectionnez Service Accounts et créez un nouveau compte de service :
- Donnez lui le nom
terraform-admin-saet cliquez sur CONTINUE - Sélectionnez le rôle Project > Owner
- Cliquez sur CREATE KEY et sélectionnez
JSON - Renommez le fichier en tant que
token.jsonet déplacez le à la racine de votre répertoiretf_gcp_gitlab_project - Cliquez sur DONE
N’égarez pas votre clé, il n’est pas possible de la récupérer ultérieurement. Vous pourrez toutefois l’annuler au profit d’une nouvelle. Le token est comme un mot de passe sécurisé. Il permet à ses détenteurs d’être authentifiés sous l’indentité de l’utilisateur de service qui vient d’être créé. Ne stockez jamais cette clé sur un dépôt Git, encore moins s’il est public. Finallement, notez l’email associé au compte de service, dans mon cas :
terraform-admin-sa@spark-workflow-automation-k8s.iam.gserviceaccount.comIl reste deux choses à accomplir avant de passer à la suite. En premier, créez un bucket GCS pour stoque l’état de Terraform dans notre architecture GCP. En second, installer le client Google Cloud SDK (gcloud) sur votre machine locale.
Pour la création du bucket, recherchez Storagedans la barre prévue à cet effet pour accéder à l’interface utilisateur (UI) de GCS et cliquez sur CREATE BUCKET :
- Fournissez un nom, j’ai indiqué
gitlab-project-state-tf - Sélectionnez
Regioncomme type de localisaition et sélectionnez la plus proche de vos utilisateur - Laissez les autres options avec les valeurs par défault
Le bucket est vérifié par Terraform à chaque fois qu’il lance une action impliquant des ressources. Il est recommandé de stocker cet état dans un dossier distant sécurisé et dédié plutôt que localement.
Pour l’installation du SDK gcloud, référez vous à ces instructions en fonction de votre environnement. Une fois l’installation terminée, exécutez la commande suivante et mémorisez le chemin, cette information sera importante au moment de connecter notre environnement Gitlab avec GCP.
Dans mon cas gcloud est installé dans /opt :
which gcloud
/opt/google-cloud-sdk/bin/gcloudLe schéma du projet est le suivant :
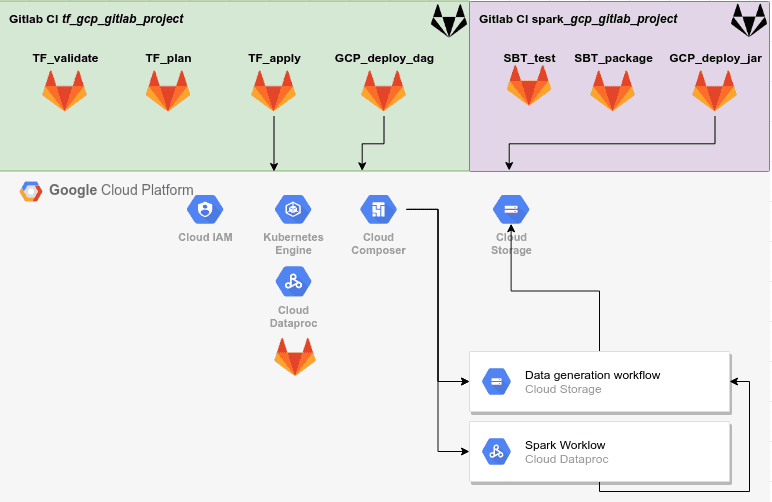
Si vous rencontrez des soucis, les codes source de ces deux projets sont disponibles ici :
tf_gcp_gitlab_project: https://gitlab.com/ferdi7/gcp_gitlab_project_tfspark_gcp_gitlab_project: https://gitlab.com/ferdi7/gcp_gitlab_project_spark
Déploiement de ressources GCP avec Terraform
Terraform est un outil de type Infrastructure as Code (IaC) dont la spécialité est de maintenir une infrastructure à jour en automatisant des tâches qui autrement auraient été manuelles. L’outil permet la contruction d’architectures complexes d’une manière simple. Il est utilisé ici pour deployer des ressoruces dans notre nouveau projet GCP. Dans notre cas d’usage, voici ce qui est construit :
- Un cluster Kubernetes hébergeant :
- des Runners GitLab qui exécutent des scripts de CI du projet
- un cluster Dataproc qui execute les tâches Spark
- un cluster Composer pour l’exécution d’un DAG qui déclenche une tâche Spark sur le cluster Dataproc
Installez terraform si vous ne l’avez pas déjà en suivant les instructions adaptées à votre environnement. Une fois l’installation terminée, exécutez terraform -vdans votre shell et vérifiez son usage. Remarquez que dans mon cas, la version utilisée de Terraform est v0.12.24.

Les fichiers créés dans cette section seront versionnez sur la branche master du dépôt tf_gcp_gitlab_project. Créez le fichier spark_git_k8s.tf ainsi :
# TODO: replace the values having <> with your own values
# It concerns the project_id, the region, the bucket for backend and other buckets
# GCP Variables
variable "project_id" {
description = "Google Project ID."
type = string
default = "<spark-workflow-automation-k8s>"
}
variable "region" {
description = "Google Cloud region"
type = string
default = "<europe-west1>"
}
variable "credentials" {
description = "Google Cloud credentials"
type = string
default = "token.json"
}
variable "input_bucket" {
type = string
default = "<input-data-workflow-automation-project>"
}
variable "output_bucket" {
type = string
default = "<output-data-workflow-automation-project>"
}
variable "archive_bucket" {
type = string
default = "<input-data-workflow-automation-project>"
}
variable "dataproc_bucket" {
type = string
default = "<dataproc-bucket-k8s-metadata>"
}
variable "backend_bucket" {
type = string
default = "<gitlab-project-state-tf>"
}
# Terraform backend
terraform {
backend "gcs" {
credentials = "token.json"
bucket = var.backend_bucket
}
}
# Specify the GCP Providers
provider "google" {
project = var.project_id
region = var.region
credentials = file("./${var.credentials}")
}
provider "google-beta" {
project = var.project_id
region = var.region
credentials = file("./${var.credentials}")
}
# API Enable
resource "google_project_service" "composer_api" {
project = var.project_id
service = "composer.googleapis.com"
disable_dependent_services = true
}
resource "google_project_service" "compute_api" {
project = var.project_id
service = "compute.googleapis.com"
disable_dependent_services = true
}
resource "google_project_service" "dataproc_api" {
project = var.project_id
service = "dataproc.googleapis.com"
disable_dependent_services = true
}
resource "google_project_service" "kubernetes_api" {
project = var.project_id
service = "container.googleapis.com"
disable_dependent_services = true
}
# GCP Resources
resource "google_storage_bucket" "input_bucket" {
name = var.input_bucket
location = var.region
project = var.project_id
}
resource "google_storage_bucket" "output_bucket" {
name = var.output_bucket
location = var.region
project = var.project_id
}
resource "google_storage_bucket" "archive_bucket" {
name = var.archive_bucket
location = var.region
project = var.project_id
}
resource "google_storage_bucket" "dataproc_bucket" {
name = var.dataproc_bucket
location = var.region
project = var.project_id
}
resource "google_container_cluster" "spark_gitlab_gke_cluster" {
provider = google-beta
depends_on = [google_project_service.kubernetes_api]
name = "gke-spark-k8s-dataproc"
location = "europe-west1"
node_locations = ["europe-west1-b", "europe-west1-c"]
initial_node_count = 2
master_auth {
username = ""
password = ""
client_certificate_config {
issue_client_certificate = false
}
}
node_config {
machine_type = "n1-standard-2"
oauth_scopes = [
"https://www.googleapis.com/auth/logging.write",
"https://www.googleapis.com/auth/monitoring",
"https://www.googleapis.com/auth/cloud-platform",
]
workload_metadata_config {
node_metadata = "EXPOSE"
}
preemptible = true
metadata = {
disable-legacy-endpoints = "true"
}
}
timeouts {
create = "30m"
update = "40m"
}
}Le code précédent définit :
- Plusieurs variables projets : ID du projet GCP, une réfion par défault, des credentials, …
- Différent APIs à activiter car nécessaire au projet
- Les fournisseurs
googleetgoogle-beta(Dataproc sur GKE est en beta) - Un cluster Kubernetes
n1-standard-2de 4 noeuds avec 8 CPUs et 30 GBs de RAM réparti sur 2 zones - Plusieurs répertoires buckets utilisés tout au cours de l’article. Les noms doivent être modifiés avec vos propres valeurs
Le cluster Kubernetes hébergent les Runners GitLab du projet. Ce faisant, le code s’éxécute en toute sécurité via les pipelines CI avec nos ressources privées et non sur les Runner mutualisés de GitLab.
A la racine du répertoire de notre projet tf_gcp_gitlab_project, exécutez :
terraform init
terraform plan
terraform apply # Write 'yes' when askedCes commandes sont exécutés manuellement la première fois et seront exécutées au travers de la CI ultérieurement. Leurs buts sont :
terraform init: téléchargement des providers définis dans les fichiers.tfet initialisation du backend si besointerraform plan: prépation d’un plan d’exécution pour déterminer quelles opération sont nécessaire en fonction de la configuraitonterraform apply: creation des ressources GCP du projet
Créez un fichier helm.tfpour l’installation de Helm sur le cluster Kubernetes et déployez les opérateurs avec les Helm charts :
provider "helm" {
kubernetes {
config_path = "./config_runner"
}
}
resource "helm_release" "runner" {
chart = "gitlab-runner"
name = "gitlab-runner"
values = [file("values-runner.yaml")]
repository = "https://charts.gitlab.io"
}
resource "helm_release" "runner_spark" {
chart = "gitlab-runner"
name = "gitlab-runner-spark"
values = [file("values-spark.yaml")]
repository = "https://charts.gitlab.io"
}Le fichier helm.tf requière la présence de 3 fichiers à la racine du projet : values-runner.yaml, values-spark.yaml et config_runner.
Pour obtenir les variables nécessaires référencées par values-runner.yaml, rendez vous dans votre projet GitLab. Dans le menu à droite, sélectionnez Settings > CI/CD > Runners :
- Cliquez sur Disable shared Runners for this project
- Obtenez l’URL fournies et son token dans la section Set up a specific Runner manually (voir l’image ci-dessous)
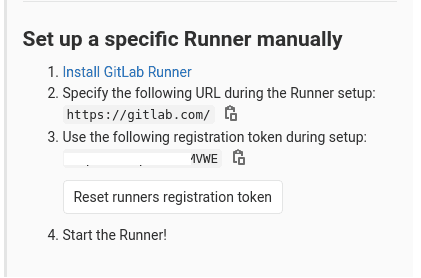
Créez le fichier values-runner.yaml ainsi :
# TODO: replace the values having <> with your own values
gitlabUrl: <https://gitlab.com/>
runnerRegistrationToken: <XxXxXxXxXxXxXMVWE>
concurrent: 20
rbac:
create: true
clusterAdminRole: true
clusterWideAccess: true
runners:
image: ubuntu:18.04
privileged: false
poll_timeout: 1080
builds:
memoryRequests: 1000MiUtilisez la même template que précédemment pour le fichier values-spark.yaml en adaptant les deux premières lignes :
- La première ligne
gitlabUrlreste identique puisque les deux projets partagent le même emplacement - Replacer la valeur de
runnerRegistrationTokenpar la valeur du tokenspark_gcp_gitlab_project
Pour le fichier config_runner, il vous faudra avoir installé le SDK Google Cloud au préalable comme indiqué précédemment. Une fois les variables mise à jours, ouvrez votre terminal et exécutez les commandes suivantes :
#TODO: Replace the <> values
# You can also use Cloud Shell in the GCP UI and copy the config_runner content
# into your local Gitlab project folder
GCP_PROJECT_ID=<spark-workflow-automation-k8s>
TF_GITLAB_REPO=<~/workflow_automation_project/tf_gcp_gitlab_project>
gcloud auth activate-service-account --key-file=$TF_GITLAB_REPO/token.json
gcloud config set project $GCP_PROJECT_ID
gcloud container clusters get-credentials gke-spark-k8s-dataproc --region europe-west1 --project $GCP_PROJECT_ID
mv ~/.kube/config $TF_GITLAB_REPO/config_runnerLa commande précédente terraform apply devrait être en succeed maintenant, le cluster Kubernetes a été deployé. Les commandes terraform doivent être executés une dernière fois en local car nous allons connecter le cluster GKE à notre projet Gitlab. De ce fait, executez les commandes suivantes :
terraform init # Needed since a new provider has been declared
terraform plan
terraform apply # Write 'yes' when askedUne fois la dernière commande exécutée, vérifiez dans la section Runners de GitLab la présence d’un nouveau Runner. Il devrait avoir un icône vert de la forme d’un point similaire à :
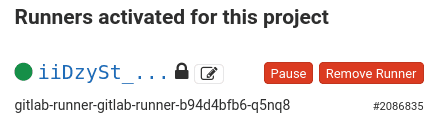
Le projet est désormais prêt à traiter les pipelines CI dans un environnement privé.
GitLab CI pipeline
Dans l’objectif de connecter le Runner à GCP pour la création de nouvelles ressources, il est nécessaire de générer une variable d’environnement dans le projet GitLab pour stocker les crédentials Google obtenu un peu plus tôt. Pour chacun des deux dépôts GitLab, effectuez les instructions suivantes :
- Naviguer dans Settings > CI/CD > Variables > Add Variable :
- Key :
GOOGLE_CREDENTIALS - Value : copiez-collez le contenu du fichier
token.json(voir ci-dessous)
- Key :
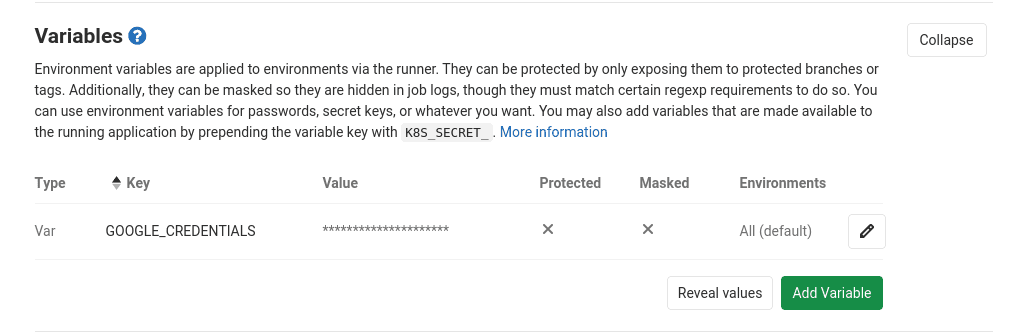
Retournons désormais dans notre dépôt tf_gcp_gitlab_project afin de construire notre pipeline CI.
Un fichier .gitlab-ci.yml est requis à la racine de nos projets pour définir les actions effectué via le pipeline CI. La documentation GitLab CI est claire et utile si vous devez à l’avenir ajouter de la complexité. Par défault, la pipeline CI est exécuté à chaque fois qu’un push est envoyé sur le serveur GitLab.
Le contenu du fichier .gitlab-ci.yml doit ressembler à ceci :
# - Modify the TF_VAR_terraform_sa value with your own.
# - Modify the GCLOUD_PATH to be the same as what you have locally (in my case it is "/opt" )
variables:
TF_VAR_terraform_sa: '<terraform-admin-sa@spark-workflow-automation-k8s.iam.gserviceaccount.com>'
GCLOUD_PATH: '/opt'
image:
name: hashicorp/terraform:0.12.24
entrypoint:
- '/usr/bin/env'
- 'PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
.before_tf: &before_tf
- cd $CI_PROJECT_DIR
- terraform --version
- echo $GOOGLE_CREDENTIALS > token.json
- terraform init
.install_gcloud: &install_gcloud
- apk add --update python2 curl which bash
- curl -sSL https://sdk.cloud.google.com | bash
- mkdir -p $GCLOUD_PATH/google-cloud-sdk
- cp -r /root/google-cloud-sdk $GCLOUD_PATH/
stages:
- validate
- plan
- apply
validate:
stage: validate
before_script: *before_tf
script:
- terraform validate
plan:
stage: plan
before_script:
- *before_tf
- *install_gcloud
- mkdir -p ~/.kube
- cp config_runner ~/.kube/config
script:
- terraform plan -input=false -out "planfile"
artifacts:
paths:
- $CI_PROJECT_DIR/planfile
apply:
stage: apply
before_script:
- *before_tf
- *install_gcloud
script:
- terraform apply -input=false "planfile"
dependencies:
- plan
when: manualCe code définit une pipeline CI en 3 phases ainsi que les actions à lancer avant comme before_tf.
validate: validation du code Terraformplan: creation d’un plan d’exécution à partir des derniers commitsapply: déploiement de nouvelles ressources (doit être déclenché manuellement dû à la définitionwhen: manual)
La liste des actions à effectuer dans install_gcloud est nécessaire pour que les étapes plan et apply réussissent. Sans cela, l’une des étapes peut échouer avec la sortie suivante :
Error: Kubernetes cluster unreachable: Get https://Xx.xX.XxX.xXx/version?timeout=32s: error executing access token command "/opt/google-cloud-sdk/bin/gcloud config config-helper --format=json": err=fork/exec /opt/google-cloud-sdk/bin/gcloud: no such file or directory output= stderr=Les Artifacts GitLab sont utilisés pour transmettre des informations entre les différentes phase du pipeline CI, ils peuvent aussi être téléchargés par un utilisateur authorisé depuis la page du projet GitLab. Comme vous pouvez le constater, un fichier planfile contennant le plan des ressources à construire est transmis de la phase plan à la phase apply afin de déployer de nouvelles ressources. La dernière phase requière un déclenchement manuel au contraire des deux précédentes qui sont automatiques. Cela garantit qu’un humain valide les changements appliqués à l’environnement.
Des paramètres IAM spécifiques et le cluster Composer sont configurés et déployés à l’aide du nouveau pipeline CI pour le tester.
Concernant les paramètres IAM, créez un nouveau fichier nommé iam.tf et écrivez ce qui suit à l’intérieur :
variable "dataproc_sa" {
type = string
}
resource "google_project_iam_member" "dataproc_admin_gke_iam" {
role = "roles/container.admin"
project = var.project_id
member = var.dataproc_sa
}
resource "google_project_iam_member" "dataproc_admin_dataproc_iam" {
role = "roles/dataproc.admin"
project = var.project_id
member = var.dataproc_sa
}
resource "google_project_iam_member" "dataproc_admin_storage_iam" {
role = "roles/storage.admin"
project = var.project_id
member = var.dataproc_sa
}Ce fichier utilise une variable qui n’est pas encore déclarée. Une des manières possible pour déclarer des variables dans Terraform est par l’utilisation de variables d’environnement commançant par TF_VAR_. Terraform interprétera ces variables à la contruction de son plan.
Naviguez dans la console IAM & Admin du projet GCP pour découvrir le compte de service (SA pour Service Account) Dataproc par défault. Pour cela, sélectionnez la section IAM dans le panneau à gauche. De là, trouvez le SA Dataproc et copiez son adresse. Ce SA a été créé après l’activation de l’API Dataproc. Il existe depuis l’exécution de la première commande terraform apply.

Naviguez dans la page Variables de GitLab pour y ajouter une variable additionnelle (remplacez la valeur par votre propre ID de compte de service) :
- Clé :
TF_VAR_dataproc_sa - Valeur :
seviceAccount:service-29729887XxXx@dataproc-accounts.iam.gserviceaccount.com
N’oubliez pas d’y ajouter le préfixe serviceAccount:
Concernant le cluster Composer, créez le fichier composer.tf ainsi :
variable "terraform_sa" {
type = string
}
resource "google_composer_environment" "composer_cluster_project" {
name = "composer-cluster-spark-workflow-project"
region = "europe-west2"
project = var.project_id
config {
node_count = 4
node_config {
zone = "europe-west2-b"
machine_type = "n1-standard-1"
network = google_compute_network.network.id
subnetwork = google_compute_subnetwork.subnetwork.id
service_account = var.terraform_sa
}
}
depends_on = [google_compute_subnetwork.subnetwork]
}
resource "google_compute_network" "network" {
name = "composer-network-project"
auto_create_subnetworks = false
project = var.project_id
}
resource "google_compute_subnetwork" "subnetwork" {
project = var.project_id
name = "composer-subnetwork-project"
ip_cidr_range = "10.2.0.0/16"
region = "europe-west2"
network = google_compute_network.network.id
}Ce fichier décrit un cluster de 4 noeuds composé d’instances n1-standard-1 ainsi qu’un réseau et un masque de sous réseau. Le cluster Composer dépend du sous réseau pour être créé. Ainsi, Terraform déploiera les ressources dans un certain ordre.
Notre première pipeline CI est prête à consommer notre code.
Il est obligatoire de créer un fichier .gitignore. Son objectif est de ne jamais inclure dans un commit certain fichiers correspondre à un motif (expression de type glob). Dans notre cas, nous voulons exclure nos fichiers de configuration locaux et notre token sécurisé.
echo ".idea/\n.terraform/\ntoken.json" > .gitignorePuisque tout est configuré, validons et poussons les nouveaux fichiers. Ce push GIT déclenchera le pipeline CI du projet.
Dans le panneau de gauche de votre projet GitLab, accédez à CI/CD> Pipelines. Un pipeline en cours d’exécution devrait apparaître. Une fois les deux premières tâches réussies, cliquez sur le premier et validé que la sortie soit similaire à cela :

Si la tâche plan confirme qu’il prévoit de déployer un cluster Composer, un réseau, un sous-réseau et trois liaisons IAM, revenez à la page Pipelines par défaut et cliquez sur le bouton gris _ >> _, puis appuyez sur Play.
Un cluster Composer prend un certain temps pour être déployé, le mien a pris près de 14 minutes. Tout en gardant un œil ouvert sur la sortie du Runner effectuant l’étape CI «Apply», passons aux parties de développement et de planification de l’application.

Développement d’une application Spark
Une condition préalable aux étapes suivants est l’installation de SBT. Suivez ces instructions appliquées à votre environnement local.
Tout au long de cette section, nous développerons une application Spark simple utilisant Scala et SBT. Elle ingérera des fichiers à partir d’un bucket GCS, transformera une colonne de date Européenne (DD-MM-YYYY) en format ISO-8601 (YYYY-MM-DD) et écrira la sortie dans un nouveau bucket GCS. Ensuite, nous créerons plusieurs DAG Airflow pour planifier l’application et générer des données factices.
L’application Spark sera hébergée dans le dépôt GitLab spark_gcp_gitlab_project. Les fichiers DAG seront hébergés dans le projet tf_gcp_gitlab_project par souci de concision. Une bonne pratique consiste à ne pas mélanger trop de langage de programmation différents dans le même dépôt.
Nous allons aussi créé un fichier .gitignore à la racine de notre projet afin d’exclude les JARs issues du build et tous les autres présents dans le répertoire target. Exécuter la commande suivante pour générer le fichier :
echo ".idea/\ntarget/" > .gitignoreDéveloppement d’une application avec SBT
Depuis la racine du répertoire du projet spark_gcp_gitlab_project, ouvrez votre console et exécutez la commande sbt new scala/scala-seed.g8 pour initialiser un nouveau projet SBT basé sur une template. Un nom de projet vous sera demandé, renseignez date_converter. Cette action va générer un projet Scala dans un nouveau répertoire du même nom, soit date_converter.
Un projet SBT repose sur un fichier build.sbt pour définir des packages et des propriétés. Modifiez le contenu de ce fichier ainsi :
name := "date_converter"
version := "0.1.0-SNAPSHOT"
organization := "com.adaltas"
organizationName := "adaltas"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.3"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.3"
libraryDependencies += "org.scalatest" %% "scalatest" % "3.1.1" % "test"
libraryDependencies += "org.apache.logging.log4j" % "log4j-core" % "2.12.0"Ensuite, créez un nouveau package appelé adaltas dans le répertoire date_converter/src/main/scala/ et créez un object Scala à l’intérieur avec le contenu suivant :
package adaltas
import java.text.SimpleDateFormat
import java.time.format.DateTimeFormatter
import org.apache.log4j.Logger
import org.apache.spark.SparkConf
import org.apache.spark.sql.functions.{col, to_date}
import org.apache.spark.sql.{Column, DataFrame, SparkSession}
object DateApplication {
val spark: SparkSession = SparkSession.builder
.config(new SparkConf().setAppName("date-data-ingestion"))
.getOrCreate()
val format = new SimpleDateFormat("dd-MM-yyyy")
def main(args: Array[String]): Unit = {
val logger: Logger = Logger.getLogger(getClass.getName)
val inputBucket = args(0)
val outputBucket = args(1)
val gcsData = spark.read
.option("inferSchema", "true")
.option("delimiter", ",")
.csv(s"gs://$inputBucket/")
val transformedDate =
dateTransform(gcsData, col("_c0"))
logger.info(transformedDate.show())
logger.info(transformedDate.schema)
transformedDate.write.csv(
s"gs://$outputBucket/output-${DateTimeFormatter.ofPattern("yyyy-MM-dd-HH-mm").format(java.time.LocalDateTime.now)}"
)
spark.stop()
}
def dateTransform(source: DataFrame,
column: Column,
fmt: String = "dd-MM-yyyy"): DataFrame = {
source.select(to_date(e = column, fmt = fmt).as("transformed_date"))
}
}Notre application Spark a besoin de deux arguments correpondant aux buckets d’entrée et de sortie.
L’application réalise les tâches suivantes :
- Lire tous les fichiers avec le suffix
.csvprésent dans un bucket GCS. - Transforme une colonne sous la forme d’une date.
- Ecrire le résultat final dans un bucket GCS.
Nous allons aussi écrire un test unitaire pour valider le comportement de notre méthode dateTransform. Comme nous l’avions fait pour le répertoire date_converter/src/main/scala/adaltas, créez un package Scala adaltas dans date_converter/src/test/scala ainsi q’une nouvelle classe DateApplicationSpec.scala dont le contenu est :
package adaltas
import org.apache.spark.SparkConf
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.scalatest.flatspec.AnyFlatSpec
import org.scalatest.matchers.should.Matchers
class DateApplicationSpec extends AnyFlatSpec with Matchers {
val spark: SparkSession = SparkSession.builder
.config(new SparkConf().setAppName("date-data-ingestion-test"))
.master("local[*]")
.getOrCreate()
val randomDates = Seq("21-12-1999", "12-12-1990", "17-01-2001", "12-07-1870")
import spark.implicits._
val sourceTest: DataFrame =
spark.sparkContext.parallelize(randomDates).toDF("date")
val resultTest: DataFrame =
DateApplication.dateTransform(source = sourceTest, col("date"))
val goodResult: DataFrame = spark.sparkContext
.parallelize(Seq("1999-12-21", "1990-12-12", "2001-01-17", "1870-07-12"))
.toDF("transformed_date")
resultTest
.selectExpr("cast(transformed_date as string) as transformed_date")
.collect should contain theSameElementsAs goodResult.collect
}Ce test simple valide le comportement de la méthode dateTransform. Les valeurs issue de la transformation sont “castées” comme “string” et comparées avec celles attendues.
Maintenant que notre application Spark est prête, construisons une pipeline CI qui va :
- Exécuter les test de notre applciation Spark avec la commande
sbt test - Packager le projet avec la commade
sbt package - Déployer la JAR générée dans un bucket GCS
Nous souhaitons que ces opérations soient déclenchées à chaque modification envoyée sur la branche master du dépôt GIT. La pipeline CI est composée de 2 phases. Créez le fichier .gitlab-ci.yml ainsi :
#TODO: Replace the JAR_BUCKET_NAME value with your value.
variables:
JAR_BUCKET_NAME: 'gs://dataproc-bucket-k8s-metadata/'
stages:
- sbt_test
- sbt_package
- deploy_jar
sbt_test:
stage: sbt_test
image: mozilla/sbt
script:
- cd $CI_PROJECT_DIR/date_converter/
- sbt test
sbt_package:
stage: sbt_package
image: mozilla/sbt
script:
- cd $CI_PROJECT_DIR/date_converter/
- sbt package
artifacts:
paths:
- $CI_PROJECT_DIR/date_converter/target/scala-2.12/date_converter_2.12-0.1.0-SNAPSHOT.jar
deploy_jar:
stage: deploy_jar
image: google/cloud-sdk:alpine
before_script:
- echo $GOOGLE_CREDENTIALS > token.json
- gcloud auth activate-service-account --key-file=token.json
script:
- gsutil cp $CI_PROJECT_DIR/date_converter/target/scala-2.12/date_converter_2.12-0.1.0-SNAPSHOT.jar $JAR_BUCKET_NAMECommitez et pushez les changement du projet spark_gcp_gitlab_project, la pipeline CI sera automatiquement déclenchée. Vérifiez depuis l’interface graphique de GitLab CI que tout fonctionne correctement. Vous devriez voir ceci :

Nous allons désormais travailler sur l’ordonnancement pour exécuter notre application à intervals réguliers.
Développement d’un workflow de type DAG
Cloud Composer est un service GCP managé construit sur Apache Airflow et déployé par dessus un cluster GKE. Il est utilisé pour orchestrer des workflows et construit des objects de type Direct Acyclic Graph (DAG) qui connecte plusieurs tâches appelées Operators. Un DAG peut être configuré pour se déclencher périodiquement. Si vous êtes familier à l’écosystème Hadoop, Airflow est comparable à Oozie mais il s’appuie sur Python au lieu d’XML. Airflow peut tirer parti des multiples bibliothèques de Python pour augmenter la complexité d’une structure DAG.
Dans cette section, nous allons construire les deux DAG hébergés dans le dépôt tf_gcp_gitclab_project :
dataproc_k8s.py: définit les tâches de workflow Sparkdata_generator.py: générez des données fictives que l’application Spark va ingérer
Créons un dossier composer à la racine du dépôt tf_gcp_gitclab_project. Là, créez un nouveau fichier dataproc_k8s.py avec le contenu suivant :
from datetime import timedelta, datetime
import os
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
GCP_PROJECT = os.environ["GCP_PROJECT_ID"]
DATAPROC_BUCKET = os.environ['DATAPROC_BUCKET']
INPUT_BUCKET = os.environ['INPUT_BUCKET']
OUTPUT_BUCKET = os.environ['OUTPUT_BUCKET']
ARCHIVE_BUCKET = os.environ['ARCHIVE_BUCKET']
DATAPROC_REGION = os.environ['DATAPROC_REGION']
GKE_CLUSTER_NAME = os.environ['GKE_NAME_CLUSTER']
IMAGE_VERSION = '1.4.27-beta'
DATAPROC_CLUSTER_NAME = '-'.join(['spark-k8s', datetime.now().strftime('%y%m%d%H%m')])
JOB_NAME = '-'.join(['date-job', datetime.now().strftime('%y%m%d%H%m')])
JAR_BUCKET = f'gs://{DATAPROC_BUCKET}/date_converter_2.12-0.1.0-SNAPSHOT.jar'
MAIN_CLASS = 'adaltas.DateApplication'
dataproc_create_job = f'''
gcloud beta dataproc clusters create '{DATAPROC_CLUSTER_NAME}' --gke-cluster='{GKE_CLUSTER_NAME}'\
--region='{DATAPROC_REGION}' --image-version='{IMAGE_VERSION}' --bucket='{DATAPROC_BUCKET}' --num-workers=2
'''
dataproc_launch_job = f'''
gcloud dataproc jobs submit spark --cluster '{DATAPROC_CLUSTER_NAME}' --region '{DATAPROC_REGION}' \
--class {MAIN_CLASS} --jars {JAR_BUCKET} -- {INPUT_BUCKET} {OUTPUT_BUCKET}
'''
default_args = {
'depends_on_past': False,
'retries': 1,
'retry_delay': timedelta(minutes=1)}
with DAG(
dag_id='dataproc_k8s_dag',
max_active_runs=2,
schedule_interval=timedelta(minutes=10),
start_date=datetime(2000, 5, 4),
default_args=default_args,
catchup=False
) as dag:
init_cluster = BashOperator(
task_id='create_dataproc_cluster',
bash_command=dataproc_create_job,
)
cluster_ready = BashOperator(
task_id='verify_dataproc_cluster',
bash_command=
f'''
flag=1;
while [ $flag -eq '1' ];
do
echo 'working';
gcloud dataproc clusters describe {DATAPROC_CLUSTER_NAME} \
--region {DATAPROC_REGION} | grep 'state: RUNNING' | wc -l | grep 1 > /dev/null;
flag=$?;
sleep 1;
done
'''
)
run_job = BashOperator(
task_id='run_job',
bash_command=dataproc_launch_job
)
delete_cluster = BashOperator(
task_id='delete_dataproc_cluster',
bash_command=f'gcloud dataproc clusters delete {DATAPROC_CLUSTER_NAME} --region={DATAPROC_REGION}',
)
archive_data = BashOperator(
task_id='archive_ingested_input_data',
bash_command=f'gsutil mv -r gs://{INPUT_BUCKET}/* gs://{ARCHIVE_BUCKET}/'
)
init_cluster >> cluster_ready >> run_job >> delete_cluster >> archive_dataNous avons utilisé la commande gcloud pour générer les ressources et soumettre le travail puisque Dataproc sur GKE a récemment été publié en version bêta. Au moment d’écrire ces lignes, le DataprocClusterCreateOperator ne prend pas encore en charge les options impliquant les clusters GKE puisque Composer n’utilise pas la dernière version d’Airflow.
Comme solution de contournement, j’ai créé cinq tâches ainsi :
- Créez un cluster Dataproc au dessus du cluster GKE précédemment créé
- Vérifiez que ce cluster est opérationnel
- Soumettre le travail Spark au cluster Dataproc
- Supprimer le cluster une fois le travail terminé
- Archivez les données ingérées (afin que les lots à venir n’ingèrent pas deux fois les mêmes données)
Nous archivons les données ingérées pour ne pas stoquer deux fois les mêmes données. Notez également que le DAG utilise des variables d’environnement pour remplir des valeurs spécifiques (cf. os.environ['XxX']).
Ces valeurs ainsi qu’une nouvelle phase seront définies en mettant à jour le .gitlab-ci.yml du projet tf_gcp_gitclab_project. Nous le ferons juste après la création du deuxième DAG.
Ingestion de données
L’objectif est de générer de faux fichiers contenant une quantité importante de dates aléatoires - fixons-le à 10000 lignes par fichier. Ces fichiers circuleront dans le compartiment GCS toutes les six minutes. En attendant, le travail de l’application batch Spark sera programmé pour être déclenché toutes les dix minutes.
Pour la génération de données, créez un nouveau DAG nommé data_generator.py dans le dossier composer :
from datetime import timedelta, datetime
from airflow.operators.python_operator import PythonOperator, PythonVirtualenvOperator
from airflow import DAG
def data_generator():
import sys, csv, random, os
from google.cloud import storage
from datetime import timedelta, datetime
if __name__ == '__main__':
input_bucket = os.environ['INPUT_BUCKET']
filename1 = "-".join(["date-data", f"{datetime.now().strftime('%y%m%d%H%M%S')}.csv"])
date_list1 = []
for i in range(0, 9999):
date_list1.append(f"{random.randint(10,31)}-0{random.randint(1,9)}-{random.randint(1990,2200)}")
with open(filename1, 'w', newline='') as myfile1:
wr = csv.writer(myfile1)
wr.writerows([r] for r in date_list1)
client = storage.Client()
bucket = client.get_bucket(input_bucket)
blob = bucket.blob(filename1)
blob.upload_from_filename(filename=filename1)
default_args = {
'depends_on_past': False,
'retries': 1,
'retry_delay': timedelta(minutes=1)}
with DAG(
dag_id='generate_input_data_to_gcs',
schedule_interval=timedelta(minutes=6),
start_date=datetime(2000, 5, 4),
default_args=default_args,
catchup=False
) as dag:
generate_data_one = PythonVirtualenvOperator(
task_id='generate_data_to_gcs_one',
python_callable=data_generator,
requirements=['google-cloud-storage==1.28.1',
'DateTime==4.3'
],
dag=dag,
system_site_packages=False,
)
generate_data_two = PythonVirtualenvOperator(
task_id='generate_data_to_gcs_two',
python_callable=data_generator,
requirements=['google-cloud-storage==1.28.1',
'DateTime==4.3'
],
dag=dag,
system_site_packages=False,
)
generate_data_three = PythonVirtualenvOperator(
task_id='generate_data_to_gcs_three',
python_callable=data_generator,
requirements=['google-cloud-storage==1.28.1',
'DateTime==4.3'
],
dag=dag,
system_site_packages=False,
)
generate_data_one >> generate_data_two >> generate_data_three3 phases vont créer un fichier contenant 10000 lignes avec des dates au format européen et le déposer dans le bucket du Composer DAG.
Nous avons aussi besoin d’une phase deploy_dag pour déposer des fichiers DAG dans Composer. A la fin du fichier .gitlab-ci.yml du projet tf_gcp_gitlab_project, ajouter les phases suivantes :
# The new stages part looks like this:
# stages:
# - validate
# - plan
# - apply
# - deploy_dag
deploy_dag:
stage: deploy_dag
image: google/cloud-sdk:alpine
variables:
COMPOSER_CLUSTER: 'composer-cluster-spark-workflow-project'
COMPOSER_REGION: 'europe-west2'
GCP_PROJECT_ID: 'spark-workflow-automation-k8s'
DATAPROC_BUCKET: 'dataproc-bucket-k8s-metadata'
INPUT_BUCKET: 'input-data-workflow-automation-project'
OUTPUT_BUCKET: 'output-data-workflow-automation-project'
ARCHIVE_BUCKET: 'archives-data-workflow-automation-project'
DATAPROC_REGION: 'europe-west1'
GKE_NAME_CLUSTER: 'gke-spark-k8s-dataproc'
before_script:
- echo $GOOGLE_CREDENTIALS > token.json
- gcloud auth activate-service-account --key-file=token.json
script:
- cd $CI_PROJECT_DIR/composer
- gcloud composer environments update $COMPOSER_CLUSTER --location=$COMPOSER_REGION --update-env-variables=COMPOSER_CLUSTER=$COMPOSER_CLUSTER,COMPOSER_REGION=$COMPOSER_REGION,GCP_PROJECT_ID=$GCP_PROJECT_ID,DATAPROC_BUCKET=$DATAPROC_BUCKET,INPUT_BUCKET=$INPUT_BUCKET,OUTPUT_BUCKET=$OUTPUT_BUCKET,ARCHIVE_BUCKET=$ARCHIVE_BUCKET,DATAPROC_REGION=$DATAPROC_REGION,GKE_NAME_CLUSTER=$GKE_NAME_CLUSTER
- gcloud composer environments storage dags import --environment=$COMPOSER_CLUSTER --location=$COMPOSER_REGION --source dataproc_k8s.py
- gcloud composer environments storage dags import --environment=$COMPOSER_CLUSTER --location=$COMPOSER_REGION --source data_generator.py
when: manualLa phase deploy_dag se déclenche manuellement et consiste à :
- Définir des variables Composer spécifiques utilisées par les DAG, vous devez les adapter avec vos propres valeurs.
- Télécharger les DAG dans le compartiment Composer DAG.
Commitez et pushez les ressources nouvelles et modifiées. Une fois cela fait, accédez au Pipeline CI/CD de tf_gcp_gitlab_project et déclenchez deploy_dag une fois que plan a réussi. Il n’est pas nécessaire de déclencher l’étape apply car aucune nouvelle ressource n’a été ajoutée dans nos fichiers .tf.

Une fois que deploy_dag réussit, accédez à la console Composer en recherchant Composer dans la barre de navigation et cliquez sur le bouton Airflow à côté du cluster Composer. Il ouvrira l’interface utilisateur Airflow sur une nouvelle page.

Il faut environ une minute pour que le DAG commence à apparaître dans la console Airflow du projet GCP. Actualisez la page après une minute. Deux nouveaux DAG devront apparaître. Ils seront déclenchés automatiquement.

Pour voir la progression d’un DAG, cliquez sur son nom puis sélectionnez Graph View. À partir de là, vous pouvez actualiser la page et vérifier la sortie du journal des tâches en cours d’exécution ou passée. Pour ce faire, cliquez sur un travail spécifique puis sur View Log.

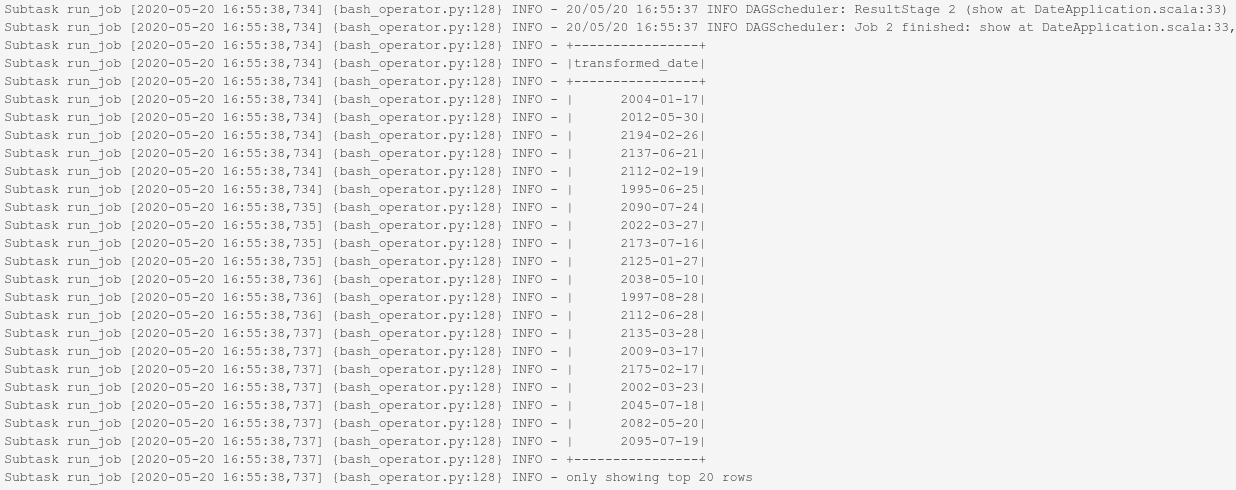
Ces journaux peuvent également être récupérés dans la console Dataproc via la fenêtre Jobs.
Une fois l’application réussie, vérifiez le compartiment GCS où la sortie de données est stockée. Dans notre cas, nous avons :
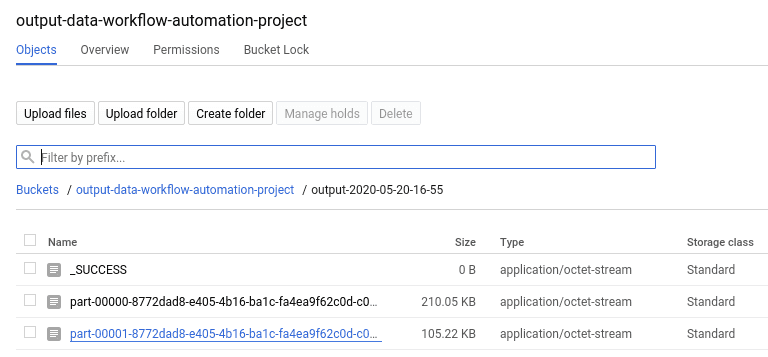
Étant donné que le travail a utilisé 2 exécuteurs (avec l’option --num-workers=2), il y a deux fichiers de résultats dans le blob créé par l’action finale write de l’application Spark. Un exemple du premier est :

Ça y est. Les DAG doivent être exécutés à intervalles réguliers, sauf si vous décidez de les arrêter. Ils généreront des données et exécuteront l’application Spark. Vous pouvez laisser les tâches planifiées s’exécuter pendant un certain temps, mais lorsque vous êtes satisfait du résultat, n’oubliez pas de supprimer toutes les ressources du projet GCP.
Il existe plusieurs façons de procéder :
- Ajoutez une étape CI manuelle
destroyavec des commandesterraformadaptées. - Exécutez les mêmes commandes localement.
Faisons-le localement. Ouvrez un shell à la racine du dossier de projet tf_gcp_gitlab_project et exécutez :
# For the plan command, no need to provide the values, just press Enter.
terraform init
terraform plan -destroy -out "destroyfile" -input=false
terraform apply "destroyfile"Ces commandes commenceront la destruction de toutes les ressources du projet. La dernière commande peut parfois échouer car les API GCP sont souvent désactivées avant la suppression des ressources. Même si la commande échoue, accédez à la page par défaut de votre projet GCP pour vérifier qu’aucun Compute Engine n’est en cours d’exécution ou si un bucket ou un réseau existe toujours. En ce qui concerne les paramètres de l’API GCP donnés dans Terraform via disable_dependent_services = true, les ressources sont censées être supprimées après la désactivation de l’API.
Une autre solution consiste à supprimer l’intégralité du projet GCP directement depuis la console GCP.
Remarques complémentaires
Le résultat de sortie de notre application Spark n’est pas utilisé ailleurs après avoir été transformé et stocké dans GCS. Il existe des limitations dans les quotas lors du déploiement de ressources via un compte d’essai gratuit qui empêchent toute autre ressource impliquant des ressources Compute Engine d’être déployée.
GitLab est un outil puissant et largement utilisé dans un environnement opérationnel pour héberger le contenu d’un projet et également exécuter un pipeline défini. Un exemple concret de son utilisation a été réalisé plus haut dans l’article. Le pipeline CI doit être plus sécurisé afin de fonctionner dans un environnement opérationnel.
Par souci de simplicité, deux projets ont été créés mais il aurait été préférable d’en créer un autre pour les fichiers Python du DAG. Un référentiel GitLab ne doit pas nécessairement héberger plusieurs types de fichiers de script de code différents : les scripts shell, les scripts python, un projet Scala ou les scripts terraform doivent être stockés dans des référentiels GitLab séparés. L’isolement des scripts de code apporte plus de simplicité lorsqu’il s’agit de gérer des projets en croissance. De plus, il est toujours recommandé d’utiliser le principe des merge request lorsqu’il s’agit d’ajouter de nouvelles fonctionnalités à la branche master en toute sécurité dans un environnement de production.
Dans notre cas particulier, un groupe GitLab aurait pu être créé pour héberger les projets. Il permet à un utilisateur de déclarer GitLab Runners en tant que Group Runners qui gèrent l’exécution du pipeline CI des projets du groupe. Les ressources de calcul des Runners doivent être augmentées pour exécuter les étapes plus rapidement et leur simultanéité doit être réduite pour ne pas surcharger leur charge de travail. Enfin, une image Docker aurait pu être développée pour avoir une image claire avec toutes les dépendances nécessaires (gcloud, terraform, sbt, etc.).
Il n’était pas simple de déployer la Helm chart via Terraform, le processus config_runner effectué précédemment pourrait être amélioré et faire partie d’une étape CI puisque le fichier ~/.kube/config généré et le token qu’il contient pour se connecter au GKE cluster peut expirer au fil du temps.
Dataproc sur Kubernetes a récemment été publié en version bêta ouverte. C’était intéressant de construire quelque chose impliquant cette nouvelle fonctionnalité. J’ai traversé de multiples problèmes tout en développant ce projet. Par exemple, j’ai eu des difficultés à déployer le cluster GKE en utilisant un compte de service ayant les mêmes droits que celui que nous avions donné avec le fichier iam.tf.
Une fois avoir lu la documention sur comment utiliser Spark sur Kubernetes, voici mes principales remarques :
- Pour ceux provenant de YARN,
kubeletdoit être considéré comme l’équivalent d’unNodeManager. - Le pilote Spark de chaque application est un contrôleur personnalisé :
- Il fait son travail de driver mais parle également à l’API.
- Les Spark Executors s’exécutent à l’intérieur de conteneurs qui s’exécutent à l’intérieur de pods, ces exécuteurs parlent au driver Spark comme il le ferait en utilisant un autre gestionnaire de cluster comme YARN ou Mesos.
- Les composants Spark Core (c’est-à-dire la configuration, les actions de ajout/suppression des exécuteurs, …) discutent avec le backend de Kubernetes.
- Spark dans des conteneurs apporte une flexibilité de déploiement, une gestion simple des dépendances et une administration simple :
- Il est facile d’isoler des packages avec un gestionnaire de packages comme
condainstallé directement sur le cluster Kubernetes. Il conduit à des mises à jour faciles des environnements. En comparaison, les packages doivent exister sur tous les nœuds utilisant YARN. - Un Dockerfile peut être créé par application Spark pour isoler les tâches et ses dépendances.
- La gestion des ressources de calcul est plus optimale car les nœuds inactifs peuvent être utilisés pour effectuer d’autres tâches.
- Kubernetes possède sa propre couche de sécurité qui peut être traduite directement vers IAM.
- Lorsqu’il s’agit de migrer un flux de travail d’un fournisseur à un autre, Kubernetes est le gestionnaire de cluster où les opérations de lift-and-shift sont les moins “douloureuses”. Lorsqu’une entreprise migre, la transition est facile au contraire de YARN. Ce ne sont que des fichiers de déploiement Kubernetes comparés aux projets basés sur YARN où chaque fournisseur de Cloud possède sa propre version gérée par les services avec des paramètres spécifiques.
- Il est facile d’isoler des packages avec un gestionnaire de packages comme
La possibilité d’exécuter Spark sur les pods Kubernetes est prometteuse. Apache Spark a compris cette demande et continuera à proposer de nouvelles fonctionnalités dans la version Spark 3 actuellement en “preview” et les suivantes.
Concernant le cluster Cloud Composer, ses ressources de calcul devraient être augmentées dans un environnement opérationnel. Les DAG écrits dans l’article sont de bons points de départ pour apprendre comment fonctionne un opérateur. Nous avons utilisé les commandes gcloud comme solution de contournement car les opérateurs concernés ne prennent pas encore en charge les actions impliquant Dataproc sur GKE. Certaines variables Composer ont été déclarées via le pipeline CI, mais il pourrait être possible de les déclarer directement dans le code Terraform.
Conclusion
Construire ce projet a été amusant et m’a aidé à me familiariser avec certains des outils impliqués dans l’article. J’espère que vous avez découvert de nouvelles choses au cours de cet article. L’architecture a été construite suivant un certain ordre pour respecter la construction du projet.
Après la création des projets, nous avons instancié un cluster GKE et nous l’avons connecté au référentiel GitLab pour commencer à utiliser le pipeline CI. Une application Spark a été développée en utilisant SBT et programmée pour s’exécuter périodiquement sur un cluster Dataproc s’exécutant sur le cluster GKE (en plus des GitLab CI Runners) grâce à un cluster Composer.
Vous pouvez trouver le code source des deux projets disponibles ici :
tf_gcp_gitlab_project: https://gitlab.com/ferdi7/gcp_gitlab_project_tfspark_gcp_gitlab_project: https://gitlab.com/ferdi7/gcp_gitlab_project_spark
