


Deep learning on YARN: running Tensorflow and friends on Hadoop cluster

Jul 24, 2018
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
With the arrival of Hadoop 3, YARN offer more flexibility in resource management. It is now possible to perform Deep Learning analysis on GPUs with specific development environments, leveraging available resources.
This article is a based on the presentation of Wandga Tan, Apache Hadoop PMC member, at the DataWorks Summit 2018. It mostly focus on GPU.
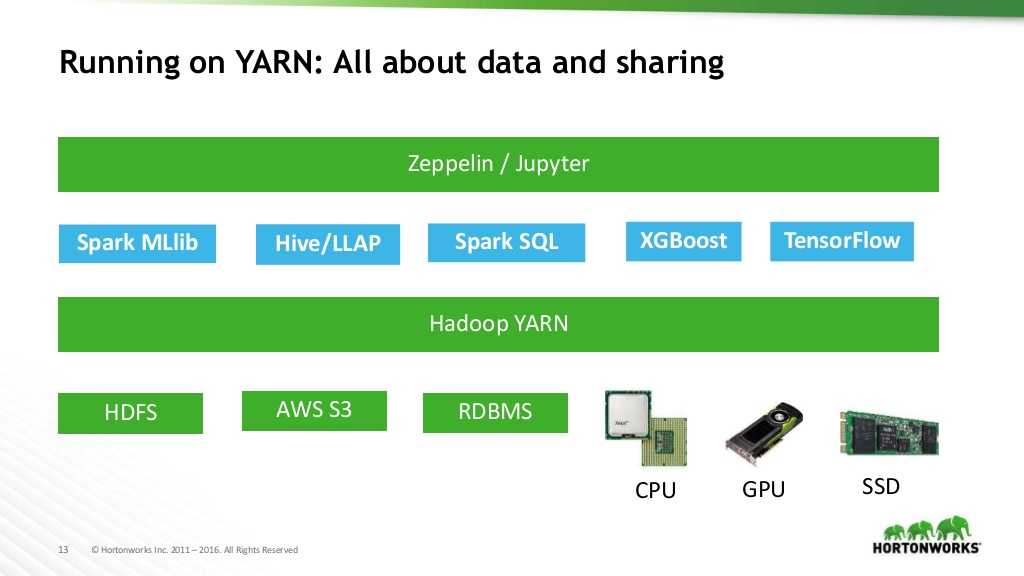
Artificial intelligence and its underlying technologies such as Deep Learning gain a lot of traction in the last few years. Hortonworks went in this direction by enriching its distribution with the integration of different frameworks of Deep Learning in HDP 3. Of course, it will still be possible to use the traditional machine learning models such as “Logistic Regression” and “Reinforcement Learning” through the Spark MLlib library or XGBoost. The big news is to have the possibility to run Deep Learning models “DNN”, “CNN”, “RNN”, “LSTM” through the famous TensorFlow framework and other Apache MXNet and Pytorch.
All the work of Deep Learning runs much faster on GPU, due to the higher core density compared to CPU.
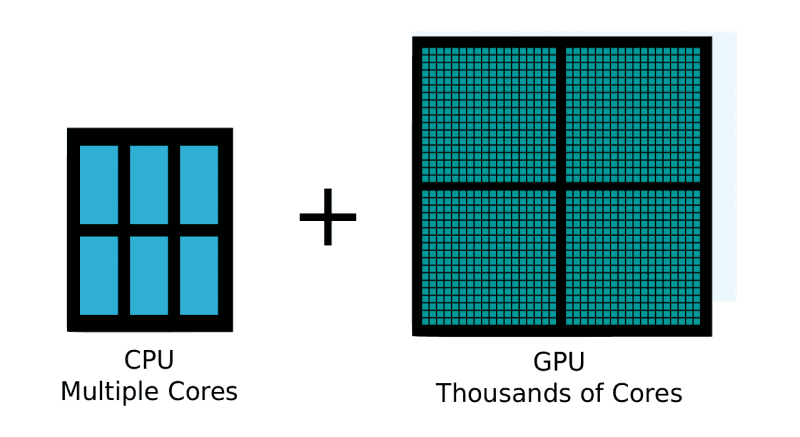
Without GPU support, researchers suffers from much longer waiting time.
YARN, the Hadoop Resource Manager allows:
- Maintaining SLA through its ability to schedule, preempt and allocate resources
- Monitoring of resources with a custom Grafana dashboard (HDP distribution)
- Organization of job execution and resource allocation with YARN queues
- Isolation of CPUs, memory, GPUs and FPGAs
YARN provides the opportunity to run the majority of Hortonworks services on a same platform. In addition, a set of nodes can be dedicated to specific usages:
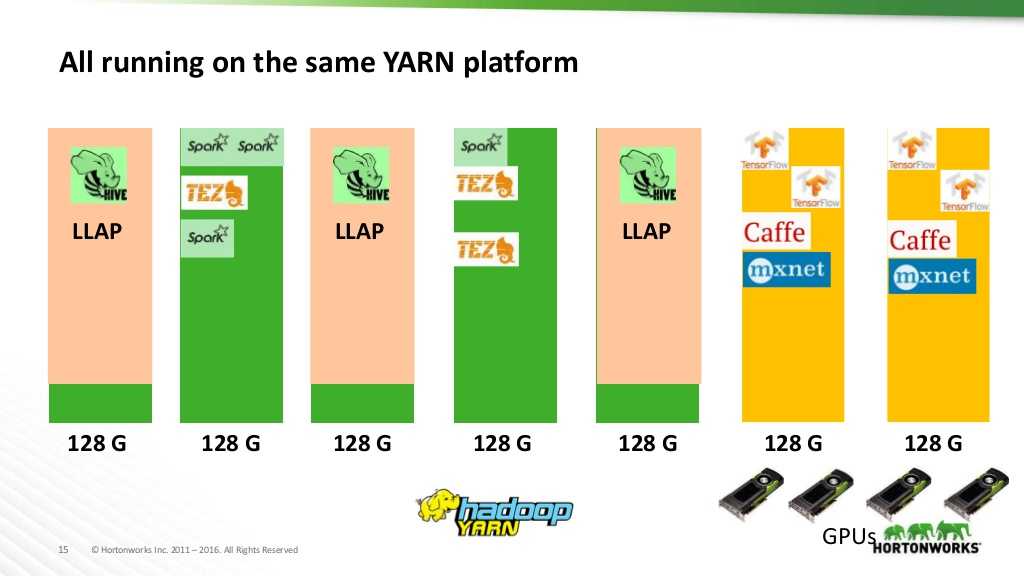
GPU isolation and orchestration will not be available in Hadoop in version 3.0.0. Support will start with version 3.1.0. GPU isolation support in YARN is required to garanty the availability of the resources to different users of the cluster. YARN uses the CGroups and Docker to set up the isolation.
Deep Learning is now in high demand. Many enterprises are looking into artificial intelligency as a solution to solve their needs and introduce new services. Today a significant number of solutions exist such as Kubernetes, Mesos, Docker Swarm, OpensShift and a few proprietary solutions. One wonders if Hortonworks and the Apache community are not late in offering Deep Learning on the Hadoop platform. Nevertheless it offers interesting possibilities. An Hadoop cluster may be splitted between dedicated nodes for storage and others dedicated nodes to DataLab usages including Deep Learning with multiple machines onboarding GPUs.In addition, Hortonworks offers an ecosystem rich of technical solutions and libraries.
