


Introduction à Cloudera Data Science Workbench

28 févr. 2019
- Catégories
- Data Science
- Tags
- Azure
- Cloudera
- Docker
- Git
- Kubernetes
- Machine Learning
- MLOps
- Notebook [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Cloudera Data Science Workbench est une plateforme qui permet aux Data Scientists de créer, gérer, exécuter et planifier des workflows de Data Science à partir de leur navigateur. Cela leur permet ainsi de se concentrer sur leur tâche principale, qui consiste à tirer des informations des données, sans penser à la complexité des outils opérants en arrière-plan. CDSW a été publié après l’acquisition par Cloudera de la start-up Data Science Sense.io. C’est une plateforme puissante pour automatiser la mise en production de Machine Learning et pousser vos modèles entre plates-formes et environnements hybrides (Edge/Fog/Cloud/sur site).
Avant d’explorer les fonctionnalités de CDSW, parlons un peu du public ciblé par la plateforme.
Les difficultés auxquels les Data Scientists font face
Ces derniers temps, il y a une forte, certain diront trop, couverture médiatique autour de l’IA. Les data scientists sont qualifiés de rock stars en raison des attentes que l’intelligence artificielle pourrait offrir aux organisations en tant que nouvelles opportunités.
Le travail de Data Scientist consiste à utiliser des données pour influer sur les activités et les opérations de la société. Il regroupe 3 compétences principales : expertise de domaine, mathématiques et informatique. La réalité de ceux que nous appelons Data Scientists a quelque peu divergé. En tant que résolveur de problèmes, il doit avoir une forte capacité de compréhension et être un excellent communicateur. Il possède de bonnes compétences en mathématiques et en statistiques ainsi qu’une solide compréhension du domaine des affaires. La plupart d’entre eux possèdent des connaissances de programmation intermédiaires qui ne leur permettent pas de relever les défis auxquels ils sont confrontés : intéragir avec des workflows d’ingestion de données en batch et streaming, publication de KPIs et d’APIs, partage de modèles entre plusieurs plates-formes et environnements, mise à l’échelle ou optimisation des performances, exploitation, compréhension et utilisation des outillages et des pratiques DevOps, mise en production du code avec des contraintes sécuritaire et opérationnelles …
L’écosystème Big Data est complexe. Le temps est limité. La prolifération d’outils et de technologies et le rythme de l’industrie peuvent être accablants. Choisir les bons outils pour le bon problème est crucial. La courbe d’apprentissage peut être raide. Les outils sont censés rendre la vie plus facile, pas plus difficile.
Les Data Scientists doivent faire face à de nombreuses difficultés pour obtenir les bonnes données au bon moment. Surtout dans des environnements sécurisés et opérationnels. Les IT imposent des normes élevées qui sont sous-estimées par les entreprises, les écoles et les scientifiques. Cela affecte leur productivité et ralentit la progression globale des projets. Par conséquent, cela limite les avantages attendus par les entreprises qui investissent dans la Data Science.
Cela étant dit, examinons ce que CDSW fournit à ses utilisateurs et ce qui le rend idéal pour les Data Scientists travaillant avec des clusters Hadoop. Nous avons commencé à tester CDSW dans ses premières versions il y a plus d’un an. Dernièrement, dans la version 1.4, CDSW a été mis à jour avec de nouvelles fonctionnalités intéressantes.
Avant tout, comment tout cela marche ?
Vue d’ensemble
Cloudera Data Science Workbench (CDSW) peut être déployé sur site ou dans le cloud. Il fournit un accès sécurisé prêt à l’emploi aux clusters Hadoop. Il a d’abord été développé pour fonctionner avec la distribution CDH (Cloudera Distribution of Hadoop) de Cloudera. Suite à la récemment fusion entre Cloudera et Hortonworks, CDSW 1.5 prend désormais en charge l’intégration avec les versions 2.x et 3.x de la distribution HDP (Hortonworks Data Platform) d’Hortonworks.
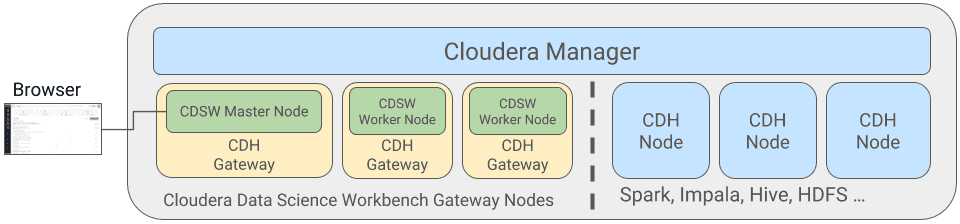
CDSW est déployé sur des machines gateways dédiées. Une machine gateway est mis à jour avec la configuration cliente des services exécutés sur le cluster Hadoop. Il existe deux types de nœuds CDSW, les nœuds maîtres et les nœuds de travail (workers). Un nœud maître chargé de l’exécution de l’application Web, de la persistance des fichiers de projet et des données avec état. Les workers, en revanche, ne sont pas requis, ils servent uniquement d’unités de calcul. Ils peuvent être ajoutés si nécessaire ou supprimés en fonction de la charge de travail des utilisateurs.
CDSW fournit une isolation des ressources par session / travail (mémoire et CPU) via l’utilisation de conteneurs Docker. Il permet l’orchestration de ces conteneurs via les nœuds Kubernetes. Lors du lancement de la session, les fichiers de projet, les bibliothèques et les configurations clientes sont montés sur un container Docker récemment démarré. Celui-ci permettra un accès sécurisé au cluster Hadoop.
Cette architecture est transparente pour les utilisateurs finaux. En réalité, ils ne doivent pas se soucier de ces composants et n’interagiront avec la plateforme que via l’application Web.
Types de déploiement
CDSW prend en charge deux types de déploiement. Le déploiement basé sur les packages et celui basé sur CSD (Custom Service Descriptor). Un CSD est un fichier jar contenant la description et les fichiers binaires nécessaires pour gérer, surveiller et configurer un service à partir de Cloudera Manager.
Le déploiement basé sur les packages peut être utilisé avec les distributions CDH et HDP. Il faut installer manuellement le paquet CDSW sur les gateways masters et de workers. Les machines gateways doivent être gérés par Cloudera manager dans le cas de CDH, ou Ambari dans le cas de HDP. CDSW peut être déployé sur un cluster à 1 nœud ou à plusieurs nœuds. Dans l’architecture multi-nœuds, CDSW doit être installé, configuré et démarré sur le nœud maître. Et ensuite, les nœuds workers peuvent être configurés pour rejoindre le cluster.
Le déploiement basé sur CSD a été introduit dans CDSW 1.2 et a rendu les choses beaucoup plus faciles. Il permet d’installer, de mettre à jour et de surveiller Cloudera Data Science Workbench à partir de Cloudera Manager (CM). Depuis lors, CDSW est disponible en tant que service pouvant être géré à dans CM. Il suffit d’ajouter le Custom Service Descriptor (CSD) de CDSW à l’hôte du serveur CM, d’installer et de déployer le colis CDSW sur les gateways via CM. CDSW peut facilement être ajouté en tant que service CM. Malheureusement, ce modèle de déploiement ne peut être utilisé qu’avec un cluster CDH.
CDSW est lié à un cluster. Il n’est pas possible de fédérer plusieurs clusters et de piloter le déploiement vers un cluster ou un autre. Par exemple, la plupart de nos clients ont au moins 2 clusters représentant 2 environnements (DEV / PROD). Le déploiement (Job ou modèle) d’un environnement à l’autre semble être un point à traiter.
Déploiement hybride, CDSW sur cloud public avec CDH sur site.
Nous suivons Cloudera Data Science Workbench (CDSW) depuis un certain temps. Lorsque nous voulions nous lancer, nous n’avions pas le matériel nécessaire à son déploiement à disposition. L’achat de nouveaux serveurs n’était pas une option. Alors naturellement, nous nous sommes tourné une plateforme Cloud. Pourquoi ne pas déployer des nœuds CDSW sur un cloud public (Azure dans notre cas) et le connecter à notre cluster CDH sur site ? Pourquoi aussi ne pas pousser davantage des rôles comme HUE sur Azure ?
Les types d’instance recommandés sont DS13-DS14 v2 sur tous les hôtes (les séries DSv2 sont des tailles de machines virtuelles optimisées en mémoire avec un rapport mémoire / processeur élevé. Les analyses en mémoire sont un des workloads ciblés. Un rapide coup d’œil aux Cloudera Director scripts montre que les machines virtuelles doivent utiliser un stockage LRS premium, avec 3 disques reliés au maître et 2 aux workers. Sur la base de Cloudera Reference Architecture for Azure deployments, la connectivité avec le data center sur site doit être basée sur ExpressRoute.
Nous avons opté pour une infrastructure beaucoup plus légère, 4 instances DS4 v2 standard (1 maître CDSW, 2 ouvriers CDSW, 1 HUE périphérique), basée sur l’image Cloudera CentOS 7.4 disponible sur le catalogue Azure, image incluant une optimisation du niveau de système d’exploitation pour CDH mais pas de JDK). L’ensemble de la configuration a été mis en œuvre en connectant le data center sur site et le réseau VNET Azure via un VPN de site à site. Nous avons utilisé le RRAS Windows 2012 R2 comme gateway sur site (nous avons essayé la configuration par défaut d’OpenSwan fournie par Microsoft, mais cela n’a pas fonctionné, nous y reviendrons probablement). Du côté Azure, la passerelle de réseau Microsoft Virtual est le choix par défaut. Nous avons également établi un réseau privé virtuel point-à-site et dissocié les adresses IP publiques des machines virtuelles Azure.
Le déploiement final ressemblait à ceci :
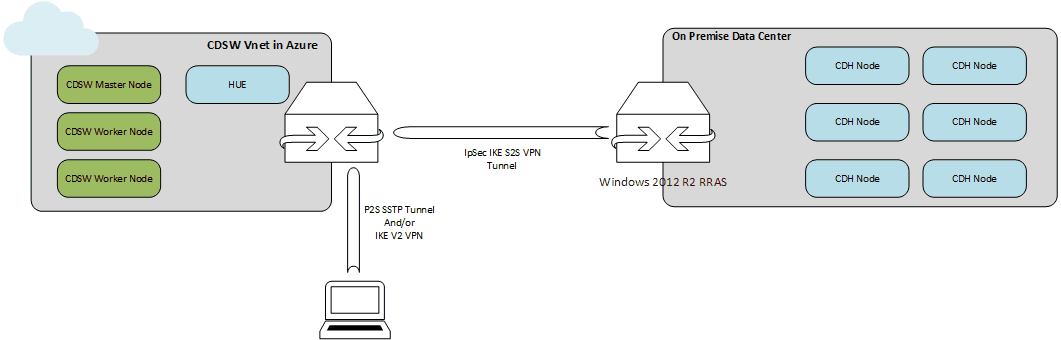
Les nœuds CDSW sont toujours gérés par Cloudera Manager et peuvent accéder aux données de CDH et tirer parti de Spark sur YARN. Les jobs comportant un traitement intensif des données sont toujours exécutés sur le cluster constitué de disques JBOD, c’est à dire directement connectés à la carte mère.
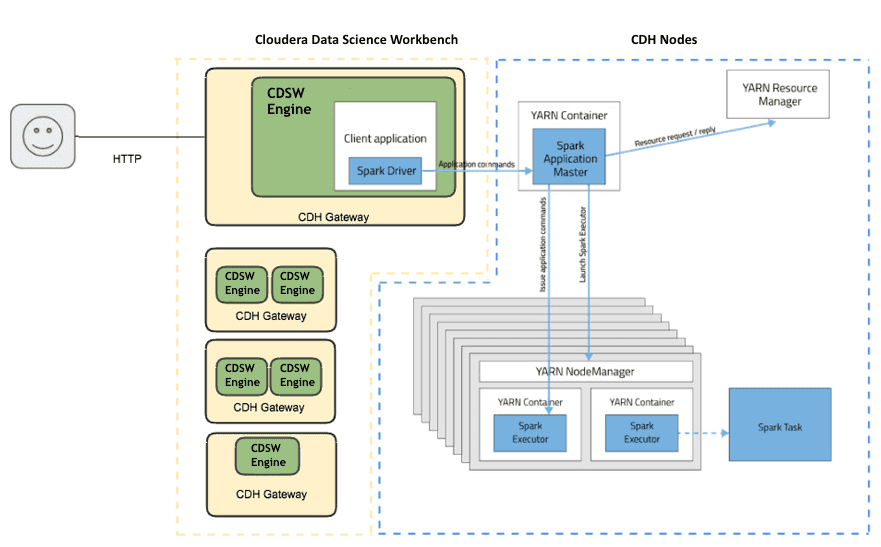
Nous n’avons pas vérifié cette architecture dans un environnement de production, ni vérifié si elle était supportée par Cloudera. mais cela a fonctionné pour nous et a définitivement ouvert de nombreuses nouvelles perspectives, avec de nouvelles architectures hybrides à la périphérie, de nouvelles façons d’essayer de nouveaux composants, et le dernier mais non des moindres : la possibilité d’utiliser des machines virtuels des GPU non disponibles sur site.
CDSW déploie et pilote sont propre cluster Kubernetes. Il nous parait pas possible de le connecter à un cluster externe. Il nous semble important de pouvoir se connecter à un cluster présent pour mettre à profil des resources disponible ou, dans le cas présent, piloter une instance de service Azure Kubernetes.
Les fonctionnalités de Cloudera Data Science Workbench.
Les projets, le coeur de CDSW.
CDSW fournit une application Web intuitive et facile à utiliser. Cela donne la possibilité de faire toutes les analyses de données via un navigateur. Les utilisateurs peuvent organiser leur travail dans des projets. Chaque projet est indépendant et sert à regrouper le code, les bibliothèques et la configuration. La visibilité du projet peut être privée, en équipe ou publique. Si le projet est privé, seul le propriétaire aura accès à son contenu. S’il est en mode public, chaque utilisateur aura le droit de voir le contenu. Outre la visibilité du projet, lorsqu’il est nécessaire de travailler ensemble sur le même projet, ce qui nous amène à la partie collaboration, le propriétaire / l’administrateur peut ajouter des collaborateurs au projet et leur accorder un niveau d’accès.
Les collègues travaillant sur les mêmes projets ou problèmes peuvent créer des équipes sur CDSW. Il existe une notion de contexte utilisée pour distinguer le compte personnel des comptes d’équipe dont un utilisateur peut faire partie. La visibilité de l’équipe rend un projet visible uniquement pour les membres d’une équipe.
La plateforme permet également d’utiliser Git pour contrôler les versions des projets, ce qui est également recommandé pour la collaboration.
Le Workbench : Où la magie opère
Regardons maintenant la console Workbench, c’est un IDE simpliste pour R, Python et Scala qui inclut un éditeur de code, une vue où les résultats sont affichés. Une invite de commande pour exécuter des commandes de manière interactive et un terminal dont nous parlerons plus tard.
Après avoir ouvert le plan de travail, nous devons lancer une session pour pouvoir exécuter du code. CDSW lance un moteur pour chaque session lancée. C’est en fait un conteneur responsable de l’exécution du code. Il fournit un environnement isolé par session, tout en disposant de tout le nécessaire (dépendances CDH et configuration client, gérée par Cloudera Manager) pour permettre un accès sécurisé aux services de cluster CDH tels que HDFS, Spark 2, Hive et Impala. Chaque moteur peut être personnalisé avec un noyau. Un moteur exécute un noyau avec un processus R, Python ou Scala pouvant être utilisé pour exécuter du code. Les profils de moteur définissent les ressources que CDSW réservera pour une session particulière en termes de mémoire et de vCPU. Lorsque la session est en cours d’exécution, l’utilisateur peut utiliser le terminal fourni par l’interface utilisateur pour installer les packages ou les bibliothèques requis, comme il le ferait sur son ordinateur local.
Un utilisateur peut souhaiter travailler de manière interactive ou automatiser des charges de travail. Le second besoin peut également être satisfait par le biais de Jobs.
Exécuter une charge de travail
Un Job permet d’automatiser les actions effectuées manuellement par l’utilisateur, notamment la configuration d’un moteur, le lancement d’une session et l’exécution d’un workload. Il se lance en tant qu’un traitement en batch et offre la possibilité de suivre les résultats en temps réel et/ou de configurer des alertes par courrier électronique. Chaque Job peut être planifié pour s’exécuter de manière récurrente (toutes les X minutes, ou selon un programme horaire, quotidien, hebdomadaire ou mensuel) ou dépendre d’un autre Job, conditionnant l’exécution au succès du Job précédent. Cette dernière option permet la création de pipelines (séquence de Job).
Il existe également une fonctionnalité appelée expérience, qui peut être utilisée pour exécuter le même traitement avec différentes configurations, jeux de données et paramètres d’entrée. Il offre la possibilité de suivre différentes versions de code, d’entrée et de sortie qui peuvent être une simple variable ou le contenu d’un fichier entier. Cette dernière fonctionnalité peut être bénéfique lors de la phase de formation d’un modèle, où les Data Scientists doivent essayer plusieurs paramètres pour en suivre l’exactitude et les ajuster en conséquence.
Deployer en production
CDSW s’intègre parfaitement à CDH. Il donne l’accès aux Data Scientists à votre Data Lake et à ses sources de données complémentaires de manière sécurisée, y compris l’authentification Kerberos, les règles d’autorisation et le chiffrement des données en mouvement. En s’appuyant sur Kubernetes, il exploite les avantages des architectures de conteneurs tels que la facilité d’exploitation de la plateforme, la vitesse d’exécution, l’isolation des tâches, l’évolutivité des ressources ou la résilience des exécutions de processus.
Le workbench fournit aux data scientists une plateforme complète pour la création, la formation et le déploiement de modèles d’apprentissage automatique.
Récemment, la plateforme permet aux équipes de Data Scientists d’exposer facilement les modèles développés en tant qu’API REST, sans l’assistance des équipes de DevOps. Les scientifiques de données doivent seulement sélectionner une fonction dans un fichier de projet. Cette fonction pourrait par exemple être la mise en œuvre d’un modèle de prédiction. CDSW se chargera du déploiement de chaque modèle dans un environnement isolé. Il est également possible de créer jusqu’à 9 répliques du même modèle permettant un équilibrage de charge.
Vous trouverez un exemple dans la documentation de Cloudera, dans laquelle ils utilisent CDSW pour créer un modèle qui prédit la largeur du pétale d’une fleur en fonction de la longueur du pétale. Cet exemple exploite les capacités de CDSW pour former un modèle à l’aide de Experiments afin de construire et d’exposer le modèle.
L’image ci-dessous présente la création d’un modèle. Il est nécessaire de spécifier le nom de la fonction à exposer, qui est “prédire” dans l’exemple, et le script contenant cette fonction.
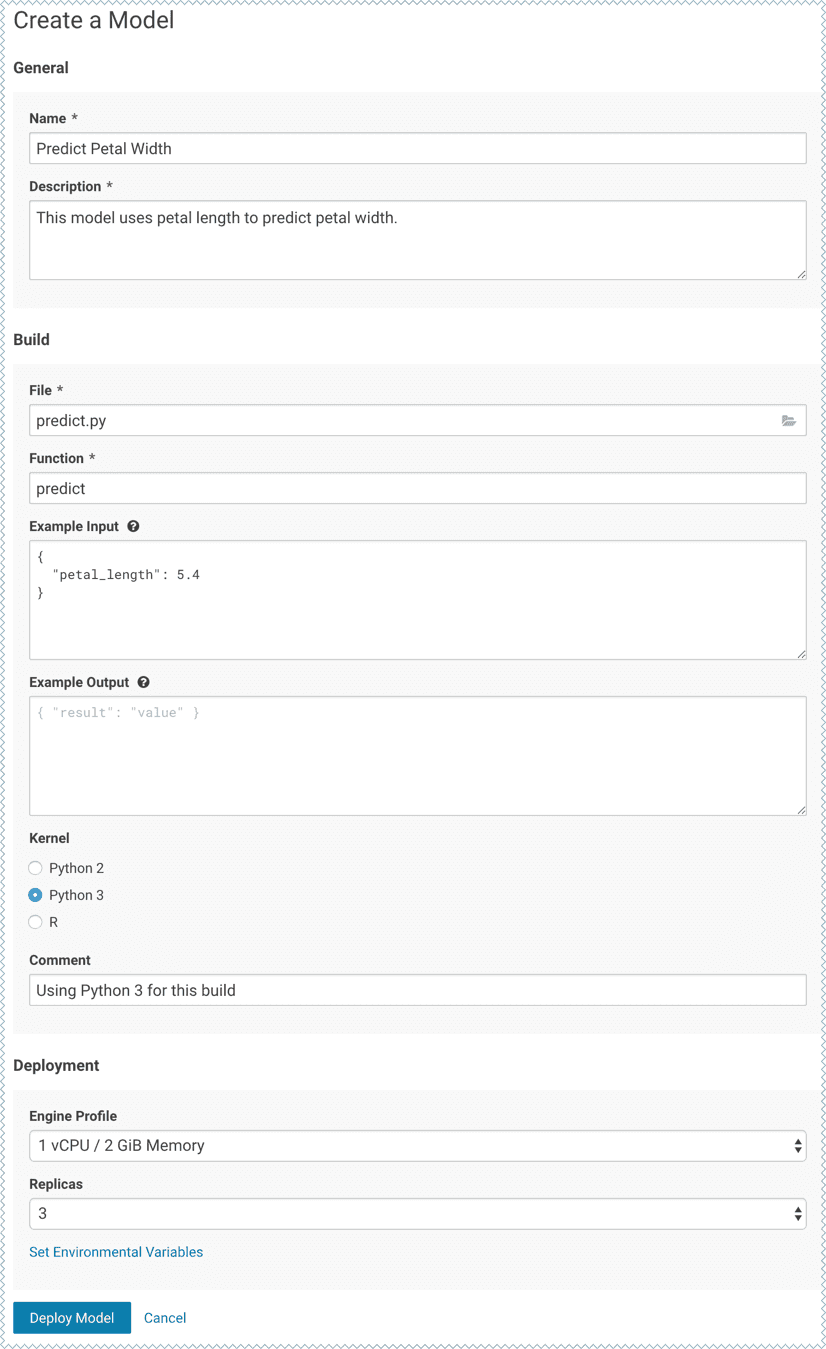
La fonction predict charge un modèle formé, l’utilise en fonction des paramètres d’entrée et renvoie la sortie. Voici le contenu du fichier predict.py :
# Read the fitted model from the file model.pkl
# and define a function that uses the model to
# predict petal width from petal length
import pickle
import numpy as np
model = pickle.load(open('model.pkl', 'rb'))
def predict(args):
iris_x = np.reshape(float(args.get('petal_length')), (-1,1))
result = model.predict(iris_x)
return result[0][0]CDSW permet de surveiller le modèle une fois qu’il a été déployé. Pour chaque replica du modèle, de nombreuses informations utiles sont affichées dans la page monitoring. Tels que l’état du réplica, le nombre de demandes traitées, le nombre d’opérations réussies et ayant échouées et ses logs.
En outre, il peut être intéressant que CDSW puisse à l’avenir s’appuyer sur la fédération pour déployer des modèles ML sur des architectures de type Edge et Fog Computing.
Ce lot de fonctionnalités peut faciliter le travail du Data Scientist. Être capable de travailler avec des données sans limites et de développer et déployer des applications d’apprentissage automatique à grande échelle avec les outils / bibliothèques préférés. Être tout le temps dans des équipes avec des compétences et des expériences différentes. Aller plus vite et efficacement de la phase d’exploration à la production. Tout cela, peut avoir un impact énorme sur l’entreprise.
Conclusion et avis.
CDSW a été principalement conçu pour fournir aux équipes de Data Scientists la flexibilité et la simplicité dont elles ont besoin pour être innovantes et productives, sans négliger les problèmes de sécurité des équipes informatiques. Outre le fait que cela ne fonctionne qu’avec Hadoop, le produit est excellent et ne nécessite pas beaucoup de temps pour se déployer ni pour se maîtriser et se lancer.
L’expérience globale de l’utilisateur est agréable, mais certains points méritent d’être améliorés. Surtout, la partie sécurité quand on collabore sur les mêmes projets. Un collaborateur peut utiliser l’identité d’un utilisateur via ses sessions en cours pour interagir avec le cluster Hadoop. Selon moi, le propriétaire de la session devrait avoir la capacité de gérer les autorisations dont disposent les collaborateurs. Moins important mais à mentionner quand même, les utilisateur de Scala seront un peu déçus. La complétion de code est disponible uniquement pour R et Python, mais pas pour Scala qui, à mon avis, est une fonctionnalité indispensable. Les Experiments Scala manquent de fonctionnalités. Par exemple, spécifier les arguments qui seront utilisés lors de l’expérimentation et la possibilité de suivre les métriques et le contenu des fichiers. Les modèles Scala ne sont pas non plus pris en charge. Enfin, l’ajout de fonctionnalités de visualisation prêtes à l’emploi, comme celles fournies par Zeppelin par exemple, serait bienvenu.
Du point de vue du déploiement, pouvoir se connecter à notre propre cluster Kubernetes ou à une instance de service Azure Kubernetes Service aurait eu beaucoup de sens.
