


Python moderne, partie 3 : établir une chaîne de CI et publier son package sur PiPy

By BRAZA Faouzi
28 juin 2021
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Avant de partager un package Python avec la communauté ou au sein de son organization, il est recommandé d’accomplir un certain nombres de tâches. Elles ont vocation à péréniser le bon fonctionnement du package sur le long terme tout en encourageant de nouvelles contributions. Tout d’abord assurez vous que votre code soit couvert par des tests unitaires. Respectez les conventions de style et de format d’écriture utilisées couramment avec Python. Ensuite Automatisez les tests et l’évaluation de la qualité de votre code afin d’intégrer ces étapes dans une chaîne d’intégration continue pour éviter de quelconques régressions qui émergerait dans cotre code après l’apport de modifications. Enfin, documentez suffisamment votre package pour en faciliter son utilisation et sa maintenance. Une fois ces tâches accomplies, partagez votre package en le publiant sur Python Package Index (PyPI). Dans cet article nous verrons justement comment accomplir chacune de ces étapes avec Poetry, Tox et GitHub Actions. Vous pouvez avoir accès au code du package sur notre dépôt.
Cet article est le dernier d’une série de trois dans laquelle nous partageons nos meilleures pratiques :
- Partie 1 : création d’un projet avec pyenv et poetry
- Partie 2 : tests unitaires et respect des conventions Git commit
- Partie 3 : Intégration continue avec GitHub Actions et publication sur PiPy
Automatiser l’évaluation de la conformité de votre code et ses tests avec tox
Si ce n’est déjà fait, activez votre environnement virtuel.
poetry shellPour évaluer la conformité de notre code, nous allons installer plusieurs packages. Ils vérifient le respect des conventions de style d’écriture et le format du code. Pour automatiser leurs exécutions et celle de nos tests unitaires nous utilisons tox. Pour installer ces packages, utilisez la commande :
poetry add black flake8 pylint tox --devL’utilisation de tox avec poetry demande certains ajustements préalables (voir les issues 1941 et 1745). Par défaut, ces deux packages ne fonctionnent pas ensemble de manière optimale. Par exemple, tox installe son propre environnement. Or pour installer les dépendances, vous devez déclarer la commande poetry install dans votre chaîne d’exécution tox. Ceci apporte beaucoup de redondance dans l’exécution et peut mener à certains problèmes. De plus ceci ne permet pas d’installer les dépendances développeurs qui sont nécessaires ici pour exécuter nos tests. Il est plus judicieux de permettre à tox d’exploiter le fichier poetry.lock et d’installer, si nécessaire, les dépendances développeurs. Pour ceci je vous conseille d’utiliser le package tox-poetry-installer, justement développé pour résoudre ces problèmes :
poetry add tox-poetry-installer[poetry] --devRédigeons maintenant notre fichier de configuration tox.ini :
# content of: tox.ini
[tox]
envlist = py38
isolated_build = true
[testenv]
description = Linting, checking syntax and running tests
require_locked_deps = true
install_dev_deps = true
commands =
poetry run black summarize_dataframe/summarize_df.py
poetry run flake8 summarize_dataframe/summarize_df.py
poetry run pylint summarize_dataframe/summarize_df.py
poetry run pytest -vNotre fichier contient deux sections :
[tox]: c’est ici que vous définissez les paramètres globaux de votre environnementtoxavec notamment les versions de Python que vous souhaitez utiliser dans vos environnements de test.[testenv]: c’est ici que vous définissez votre environnement d’exécution. Dans notre cas, nous avons deux variables, apportées par le package tox-poetry-installer,require_locked_depsetinstall_dev_depsqui permettent àtoxd’utiliser les dépendances définies dans le fichierpoetry.locket d’installer les dépendances développeur.
La documentation de
toxpermet d’approfondir les configurations possibles. En complément, lisez la documentation detox-poetry-installersi vous êtes intéressés de connaître les possibilités offertes par ce package.
Exécutons nos tâches :
tox
[...]
py38 run-test: commands[0] | poetry run black summarize_dataframe/summarize_df.py
All done! ✨ 🍰 ✨
1 file left unchanged.
py38 run-test: commands[1] | poetry run flake8 summarize_dataframe/summarize_df.py
py38 run-test: commands[2] | poetry run pylint summarize_dataframe/summarize_df.py
************* Module summarize_dataframe.summarize_df
summarize_dataframe/summarize_df.py:1:0: C0114: Missing module docstring (missing-module-docstring)
summarize_dataframe/summarize_df.py:4:0: C0103: Argument name "df" doesn't conform to snake_case naming style (invalid-name)
summarize_dataframe/summarize_df.py:11:4: C0103: Argument name "df" doesn't conform to snake_case naming style (invalid-name)
summarize_dataframe/summarize_df.py:23:4: C0103: Argument name "df" doesn't conform to snake_case naming style (invalid-name)
summarize_dataframe/summarize_df.py:43:0: C0103: Argument name "df" doesn't conform to snake_case naming style (invalid-name)
------------------------------------------------------------------
Your code has been rated at 7.62/10 (previous run: 7.62/10, +0.00)
ERROR: InvocationError for command /home/fbraza/Documents/python_project/summarize_dataframe/.tox/py38/bin/poetry run pylint summarize_dataframe/summarize_df.py (exited with code 16)
________________________________________________________ summary ________________________________________________________________
ERROR: py38: commands failedNous obtenons une erreur qui stipule que pylint a identifié des fautes dans notre code. Par défaut, l’exécution de tox stoppe si une erreur est rencontrée. Dans notre cas les messages d’erreur sont plutôt explicites. Corrigeons notre code et relançons tox :
tox
py38 run-test: commands[0] | poetry run black summarize_dataframe/summarize_df.py
All done! ✨ 🍰 ✨
1 file left unchanged.
py38 run-test: commands[1] | poetry run flake8 summarize_dataframe/summarize_df.py
py38 run-test: commands[2] | poetry run pylint summarize_dataframe/summarize_df.py
--------------------------------------------------------------------
Your code has been rated at 10.00/10 (previous run: 10.00/10, +0.00)
py38 run-test: commands[3] | poetry run pytest -v
================================================= test session starts =============================================================
platform linux -- Python 3.8.7, pytest-5.4.3, py-1.10.0, pluggy-0.13.1 -- /home/fbraza/Documents/python_project/summarize_dataframe/.tox/py38/bin/python
cachedir: .tox/py38/.pytest_cache
rootdir: /home/fbraza/Documents/python_project/summarize_dataframe
collected 2 items
tests/test_summarize_dataframe.py::TestDataSummary::test_data_summary PASSED [ 50%]
tests/test_summarize_dataframe.py::TestDataSummary::test_display PASSED [100%]
================================================= 2 passed in 0.30s ===============================================================
______________________________________________________ summary ____________________________________________________________________
py38: commands succeeded
congratulations :)La pipeline tox a été exécutée localement avec succès. Voyons maintenant comment exploiter GitHub Actions pour exécuter automatiquement notre pipeline après l’envoie de nos changements sur le dépôt de GitHub.
Intégration continue avec GitHub Actions
GitHub Actions facilite l’automatisation de vos pipelines CI. C’est un service dit “event-driven”, ce qui signifie que des commandes peuvent être exécutées en réponse à un événement particulier. Cet événement peut être un Git push ou une merge request. De plus, GitHub Actions vous laisse exécuter l’ensemble de vos tests en utilisant différentes versions de Python sur différents systèmes d’exploitation (Linux, macOS and Windows). Les seules choses dont vous avez besoin sont : un répertoire hébergé sur Github, un fichier .github/workflows/ :
mkdir -p .github/workflows
touch .github/workflows/ci.ymlLe contenu du fichier .github/workflows/ci.yml est :
name: CI Pipeline for summarize_df
on:
- push
- pull_request
jobs:
build:
runs-on: ${{matrix.platform}}
strategy:
matrix:
platform: [ubuntu-latest, macos-latest, windows-latest]
python-version: [3.7, 3.8, 3.9]
steps:
- uses: actions/checkout@v1
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v2
with:
python-version: ${{ matrix.python-version }}
- name: Install dependencies
run: |
python -m pip install poetry
poetry install
- name: Test with tox
run: poetry run toxDécrivons brièvement les sections présentes dans ce fichier :
on: c’est ici que l’on définit le type d’événement qui va activer la séquence de tâches présentes dans notre pipeline.jobs: c’est ici que l’on définit les différentes étapes de notre pipeline. Elles sont exécutées dans une machine virtuelle.build: c’est ici que la magie opère :- l’entrée
strategy.matrix.platformcontient la liste des différents systèmes d’exploitation que nous utiliserons. Chaque valeur est interpolée par templating dans l’entréebuild.runs-on. - l’entrée
strategy.matrix.python-versiondéfinit les différentes version de Python que nous allons utiliser. Chaque valeur est interpolée par templating dans l’entréewith:python-version:. - l’entrée
stepscontient les actions que nous utilisons (steps.uses) et quelle commande nous voulons exécuter (steps.run).
- l’entrée
Avant de terminer nous devons apporter certains changement à nos fichiers tox.ini et pyproject.toml. Initialement, nous avons choisi une seule version de Python, la 3.8. Or, nous allons tester notre package dans GitHub Actions avec les version 3.7 et 3.9 également. Pour le fichier pyproject.toml choisissez une version seuil qui englobera l’ensemble des versions que vous utiliserez dans votre pipeline CI. Ici nous choisissons de rendre notre package compatible avec Python à partir de la version 3.7.1. Voici les changements :
# content of: tox.ini
[tox]
envlist = py37,py38,py39
isolated_build = true
skip_missing_interpreters = true
[...]# content of: pyproject.toml
[...]
[tool.poetry.dependencies]
python = "^3.7.1"
[...]Lorsque vous modifiez la version de Python dans le fichier
pyproject.toml, pensez à toujours ré-exécuter la commandepoetry update. Cette commande évalue de potentielles incompatibilités entre la version de Python et vos dépendances.
Pour finir, installons le package tox-gh-actions qui permet d’exécuter tox en parallèle sur GitHub Actions tout en utilisant différentes versions de Python :
poetry add tox-gh-actions --devNous sommes maintenant prêt à exécuter notre pipeline CI. Nous pouvons ajouter et envoyer nos changements sur GitHub :
echo "!.github/" >> .gitignore
git add .gitignore
git commit -m "build: update .gitignore to unmask .github/ folder"
git add pyproject.toml tox.ini poetry.lock `.github/workflows/ci.yml`
git commit -m "build: tox pipeline + github actions CI pipeline"Pour observer notre pipeline s’exécuter, allez dans votre répertoire Git et cliquer sur l’onglet “Actions” :

C’est ici que vous verrez les exécutions en cours et précédentes :
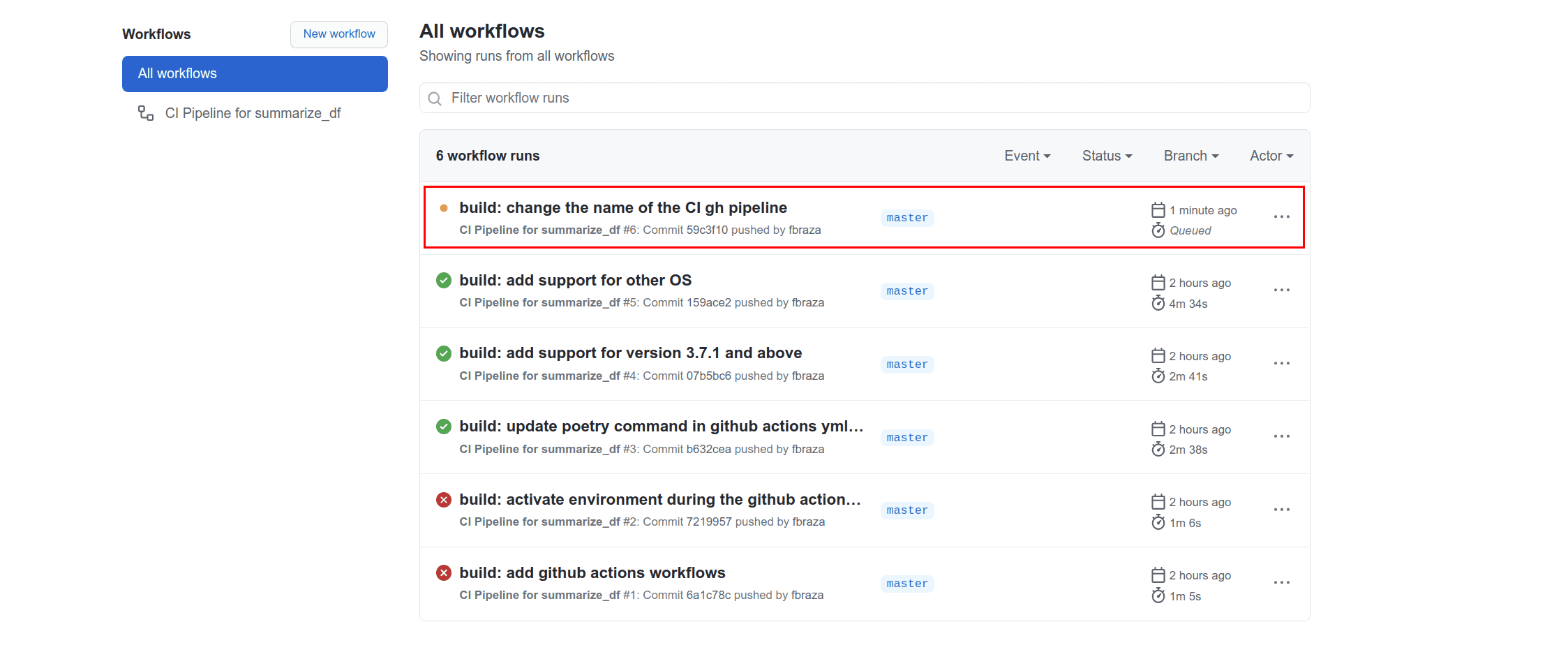
Cliquons sur l’exécution en cours. La pipeline s’exécute pour chaque système d’exploitation et pour chaque version de Python. Attendez quelques minutes :
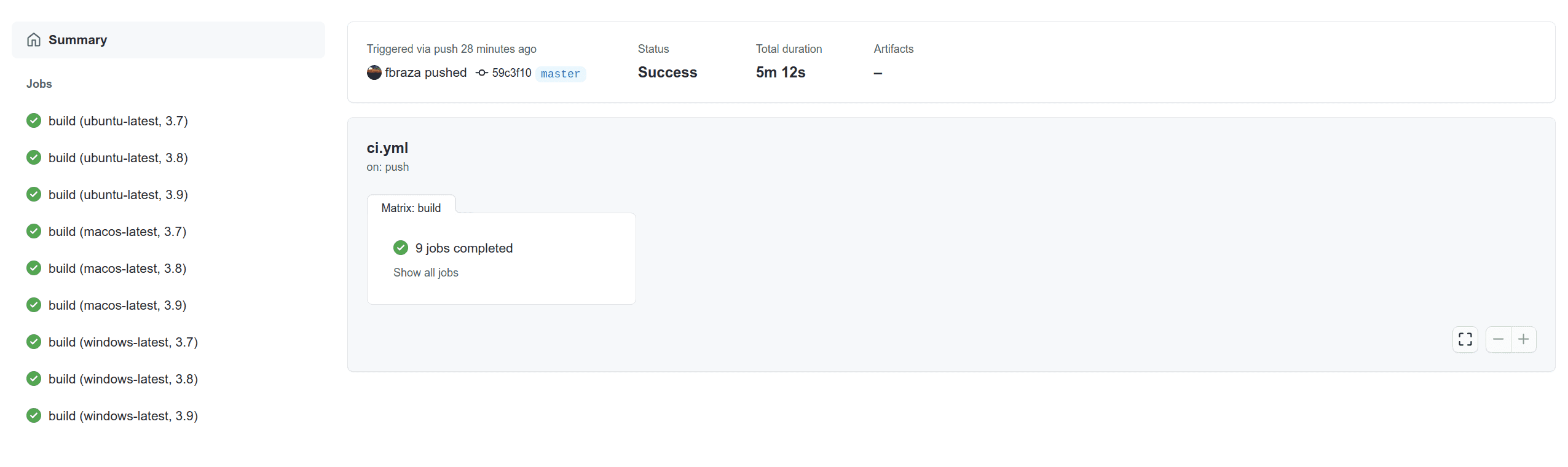
Bravo toutes les pipelines se sont exécutées avec succès. Nous sommes prêt à publier notre package.
Publier votre package sur PiPy avec poetry
Pour rendre votre package publiable, appliquez les changements suivants dans votre fichier pyproject.toml :
[tool.poetry]
name = "summarize_dataframe"
version = "0.1.0"
description = "A package to provide summary data about pandas DataFrame"
license = "MIT"
authors = ["fbraza <fbraza@tutanota.com>"]
keywords = ["pandas", "dataframe"]
readme = "README.md"
homepage = "https://github.com/fbraza/summarize_dataframe"
repository = "https://github.com/fbraza/summarize_dataframe"
include = ["CHANGELOG.md"]
[...]Les modifications apportées sont plutôt explicites. Ce sont des métadonnées nécessaires à la publication de votre package. La variable include est intéressante et très utile. Vous pouvez y ajoutez le nom de n’importe quel fichier que vous souhaitez inclure dans votre package. Dans notre cas nous ajoutons un fichier CHANGELOG.md qui contient l’historique des modifications apportées aux différentes versions de votre package. Vous souvenez-vous de commitizen ? Si ce n’est pas le cas, lisez notre article sur l’utilisation de commitizen et conventional commits. Utilisez la commande suivante :
cz bumpCelle-ci capture la version de votre package à partir de votre fichier pyproject.toml et crée un tag Git. Ensuite elle met à jour la version du package en fonction des messages Git commit. Ensuite, créons et lisons le fichier CHANGELOG.md :
cz changelog
cat CHANGELOG.md
## Unreleased
## 0.1.0 (2021-04-28)
### Refactor
- correct pylint warnings
- split the function into two: one returning df other for output
### Feat
- implementation of the summary function to summarize dataframeLe fichier CHANGELOG.md est prêt. Notez qu’il capture les modifications importantes apportées à votre package en se basant sur votre historique Git. C’est très pratique et facilite la maintenance de ce fichier sur le long terme. Maintenant, préparons notre package pour publication avec poetry :
poetry build
Building summarize_dataframe (0.1.0)
- Building sdist
- Built summarize_dataframe-0.1.0.tar.gz
- Building wheel
- Built summarize_dataframe-0.1.0-py3-none-any.whlNotez la création du répertoire dist qui contient le package compilé. Utilisez pip pour tester si tout fonctionne bien :
Faites cela en dehors de votre environnement virtuel.
pip install path/to/your/package/summarize_dataframe-0.1.0-py3-none-any.whlPour publier votre package surPyPi, vous devez créer votre propre compte. Ensuite lancez la commande :
poetry publish
Username: ***********
Password: ***********
Publishing summarize_dataframe (0.1.0) to PyPI
- Uploading summarize_dataframe-0.1.0-py3-none-any.whl 100%
- Uploading summarize_dataframe-0.1.0.tar.gz 100%Notre package est en ligne et partagé avec la communauté !
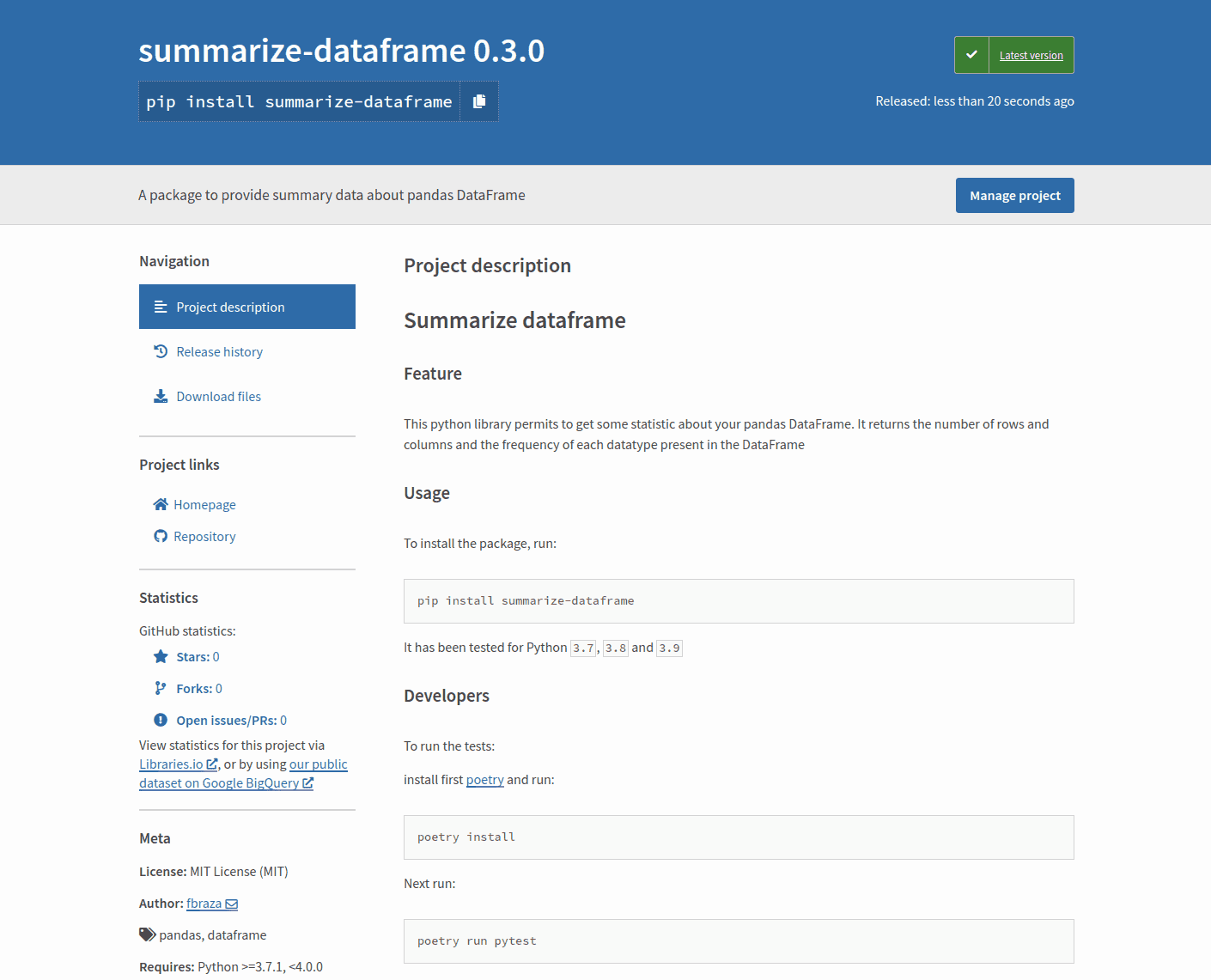
Conclusion
tox propose une interface qui permet d’automatiser un ensemble de tâches, comme l’exécution de nos tests unitaires ou encore le contrôle qualité de notre code. L’écosystème qui se construit autour de poetry gagne progressivement en maturité et propose par exemple des solutions adaptées pour une utilisation combinée avec tox. Ensemble, ces deux utilitaires permettent à l’utilisateur d’établir un environnement CI robuste et cohérent. GitHub Actions permet d’aller plus loin dans la démarche CI en donnant la possibilité à l’utilisateur d’exécuter sa pipeline CI dans des environnements de travail différents et en utilisant plusieurs versions de Python.
poetry était au cœur de notre démarche. De la création de projet à sa publication en passant par la gestion des packages et dépendances, poetry se révèle être un outil efficace et facile d’utilisation qui facilitera la vie des développeurs Python, des data scientists et des data engineers dans le développement et la gestion de leurs projets.
Ensemble cette série d’article propose donc une démarche pour développer vos propres projets Python en respectant quelques-unes des bonnes pratiques d’ingénierie logicielle.
Pense-bête
tox
-
Pour exécuter la pipeline
tox:tox
poetry
-
Pour construire votre package :
poetry build -
Pour publier votre package :
poetry publish
