


Intégration de Spark et Hadoop dans Jupyter

1 sept. 2022
- Catégories
- Adaltas Summit 2021
- Infrastructure
- Tech Radar
- Tags
- Infrastructure
- Spark
- YARN
- CDP
- HDP
- Jupyter
- Notebook
- TDP [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Depuis quelques années, Jupyter notebook s’impose comme la principale solution de notebook dans l’univers Python. Historiquement, Jupyter est l’outil de prédilection des data scientists développant principalement en Python. Jupyter à su évoluer et dispose aujourd’hui d’un grand éventail de fonctionnalités grâce à ses plugins. Sa facilité de déploiement est également l’un de ses principaux atouts.
De plus en plus de développeurs Spark privilégient désormais Python à Scala pour développer leurs différents jobs dû à la rapidité de développement en Python.
Dans cet article, nous allons voir ensemble de quelle manière nous pouvons connecter un serveur Jupyter à un cluster Spark tournant sur Hadoop YARN et sécurisé avec Kerberos.
Comment installer Jupyter ?
Deux méthodes seront couvertes pour connecter Jupyter à un cluster Spark :
- Utiliser un script lançant une instance Jupyter qui disposera d’un interpréteur Python Spark.
- Connecter Jupyter notebook à un cluster Spark via l’extension Sparkmagic.
Méthode 1 : Créer un script de démarrage
Prérequis :
- Avoir accès à une machine du cluster Spark, usuellement de type master node ou edge node ;
- Disposer d’un environnement Python (Conda, Mamba, virtualenv, ..) possédant le package
jupyter.
Exemple avec Conda :conda create -n pysparktest python=3.7 jupyter
Ajouter dans le répertoire /home le script suivant en modifiant les paths pour qu’ils correspondent à son environnement :
#! /bin/bash
# Définit l'environnement Python à utiliser
export PYSPARK_PYTHON=/home/adaltas/.conda/envs/pysparktest/bin/python
# Définit le driver IPython
export PYSPARK_DRIVER_PYTHON=/home/adaltas/.conda/envs/pysparktest/bin/ipython3
# Définit la configuration Spark à utiliser
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --no-browser --ip=10.10.20.11--port=8888"
pyspark \
--master yarn \
--conf spark.shuffle.service.enabled=true \
--conf spark.dynamicAllocation.enabled=false \
--driver-cores 2 --driver-memory 11136m \
--executor-cores 3 --executor-memory 7424m --num-executors 10Exécuter ce script permet de créer un serveur Jupyter pouvant être utilisé pour développer des jobs Spark.
Principaux avantages de cette solution :
- Rapidité du lancement ;
- Pas besoin de modifier la configuration du cluster ;
- Personnalisation de l’environnement Spark par client ;
- Environnement local de la node depuis lequel a été lancé le serveur ;
- Environnement dédié par utilisateur ce qui évite les problèmes liés à la surcharge du serveur.
Principaux inconvénients de cette solution :
- Dérives de personnalisations (utilisation de trop de ressources, mauvaise configuration, etc…) ;
- Nécessite d’avoir accès à un edge node du cluster ;
- L’utilisateur dispose seulement d’un interpréteur Python (PySpark en réalité) ;
- Un seul environnement est disponible par serveur (Conda ou autre).
Methode 2 : Connecter un cluster Jupyter via Sparkmagic
Qu’est-ce que Sparkmagic ?
Sparkmagic est une extension Jupyter qui permet de lancer des jobs Spark au travers de Livy.
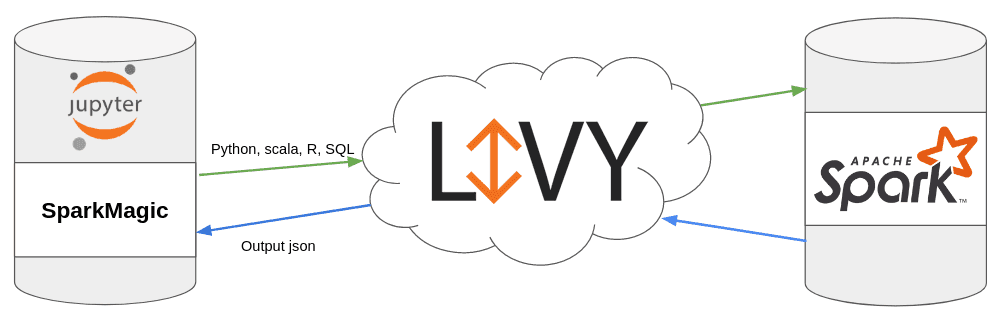
Prérequis :
- Disposer d’un cluster possédant au minimum Livy et Spark (par exemple HDP, CDP ou TDP) ;
- Disposer d’un serveur Jupyter. JupyterHub est utilisé pour cette démonstration ;
- Avoir configuré l’impersonnisation sur le cluster, en anglais
user impersonation, avec Kerberos.
Création de l’utilisateur jupyter au sein du cluster
Dans ce test, les utilisateurs sont gérés via FreeIPA sur un cluster HDP Kerberisé.
Création de l’utilisateur jupyter :
ipa user-add
Définition du mot de passe :
ipa passwd jupyter
Vérifier que l’utilisateur dispose bien d’une keytab sur l’un des egde nodes du cluster et que l’impersonnisation est bien actif :
kinit jupyter
curl --negotiate -u : -i -X PUT
"http://edge01.local:9870/webhdfs/v1/user/vagrant/test?doas=vagrant&op=MKDIRS"Note, la commande ci-dessus crée un répertoire
/user/vagrantdans HDFS. Elle nécessite des permissions de type administrateur via l’impersonnisation décrite dans la section suivante.
Pour finir, vérifier que l’utilisateur jupyter fait bien partie du groupe sudo sur le serveur où sera installé Jupyter.
Emprunt d’identité de l’utilisateur jupyter
Dans le cas d’un cluster HDP Kerberisé, comme c’est le cas ici, il faut activer l’impersonnisation pour l’utilisateur jupyter.
Pour cela, il faut modifier le fichier core-site.xml :
<property>
<name>hadoop.proxyuser.jupyter.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.jupyter.groups</name>
<value>*</value>
</property>Installation et activation de l’extension Sparkmagic
Comme précisé dans la documentation, l’installation de l’extension Sparkmagic s’effectue de la façon suivante :
pip install sparkmagic
jupyter nbextension enable --py --sys-prefix widgetsnbextension
pip3 show sparkmagic
cd /usr/local/lib/python3.6/site-packages
jupyter-kernelspec install sparkmagic/kernels/sparkkernel
jupyter-kernelspec install sparkmagic/kernels/pysparkkernel
jupyter-kernelspec install sparkmagic/kernels/sparkrkernelL’exemple fourni utilise le gestionnaire de packages pip, néanmoins l’installation peut s’effectuer avec n’importe quel autre gestionnaire de packages Python.
Configuration de Sparkmagic
Pour fonctionner, Sparkmagic nécessite que chaque utilisateur possède un dossier .sparkmagic à la racine de chaque utilisateur dans le répertoire /home/, contenant un fichier de configuration config.json.
Voici un exemple de fichier config.json :
{
"kernel_python_credentials":{
"username":"{{ username }}",
"url":"http://master02.cdp.local:8998",
"auth":"Kerberos"
},
"kernel_scala_credentials":{
"username":"{{ username }}",
"url":"http://master02.cdp.local:8998",
"auth":"Kerberos"
},
"kernel_r_credentials":{
"username":"{{ username }}",
"url":"http://master02.cdp.local:8998",
"auth":"Kerberos"
},
"logging_config":{
"version":1,
"formatters":{
"magicsFormatter":{
"format":"%(asctime)s\t%(levelname)s\t%(message)s",
"datefmt":""
}
},
"handlers":{
"magicsHandler":{
"class":"hdijupyterutils.filehandler.MagicsFileHandler",
"formatter":"magicsFormatter",
"home_path":"~/.sparkmagic"
}
},
"loggers":{
"magicsLogger":{
"handlers":[
"magicsHandler"
],
"level":"DEBUG",
"propagate":0
}
}
},
"authenticators":{
"Kerberos":"sparkmagic.auth.kerberos.Kerberos",
"None":"sparkmagic.auth.customauth.Authenticator",
"Basic_Access":"sparkmagic.auth.basic.Basic"
},
"wait_for_idle_timeout_seconds":15,
"livy_session_startup_timeout_seconds":60,
"fatal_error_suggestion":"The code failed because of a fatal error:\n\t{}.\n\nSome things to try:\na) Make sure Spark has enough available resources for Jupyter to create a Spark context.\nb) Contact your Jupyter administrator to make sure the Sparkmagic library is configured correctly.\nc) Restart the kernel.",
"ignore_ssl_errors":false,
"session_configs":{
"driverMemory":"1000M",
"executorCores":2,
"conf":{
"spark.master":"yarn-cluster"
},
"proxyUser":"jupyter"
},
"use_auto_viz":true,
"coerce_dataframe":true,
"max_results_sql":2500,
"pyspark_dataframe_encoding":"utf-8",
"heartbeat_refresh_seconds":30,
"livy_server_heartbeat_timeout_seconds":0,
"heartbeat_retry_seconds":10,
"server_extension_default_kernel_name":"pysparkkernel",
"custom_headers":{
},
"retry_policy":"configurable",
"retry_seconds_to_sleep_list":[
0.2,
0.5,
1,
3,
5
],
}Modifier /etc/jupyterhub/jupyterhub_config.py - SparkMagic
Par soucis d’optimisation, j’ai décidé de modifier le fichier /etc/jupyterhub/jupyterhub_config.py afin d’automatiser certains process liés à SparkMagic :
- Création du dossier
.sparkmagicdans le répertoire home de chaque nouvel utilisateur ; - Génération du fichier
config.json.
c.LDAPAuthenticator.create_user_home_dir = True
import os
import jinja2
import sys, getopt
from pathlib import Path
from subprocess import check_call
def config_spark_magic(spawner):
username = spawner.user.name
templateLoader = jinja2.FileSystemLoader(searchpath="/etc/jupyterhub/")
templateEnv = jinja2.Environment(loader=templateLoader)
TEMPLATE_FILE = "config.json.template"
tm = templateEnv.get_template(TEMPLATE_FILE)
msg = tm.render(username=username)
path = "/home/" + username + "/.sparkmagic/"
Path(path).mkdir(mode=0o777, parents=True, exist_ok=True)
outfile = open(path + "config.json", "w")
outfile.write(msg)
outfile.close()
os.popen('sh /etc/jupyterhub/install_jupyterhub.sh ' + username)
c.Spawner.pre_spawn_hook = config_spark_magic
c.JupyterHub.authenticator_class = 'ldapauthenticator.LDAPAuthenticator'
c.LDAPAuthenticator.server_hosts = ['ipa.cdp.local']
c.LDAPAuthenticator.server_port = 636
c.LDAPAuthenticator.server_use_ssl = True
c.LDAPAuthenticator.server_pool_strategy = 'FIRST'
c.LDAPAuthenticator.bind_user_dn = 'uid=admin,cn=users,cn=accounts,dc=cdp,dc=local'
c.LDAPAuthenticator.bind_user_password = 'passWord1'
c.LDAPAuthenticator.user_search_base = 'cn=users,cn=accounts,dc=cdp,dc=local'
c.LDAPAuthenticator.user_search_filter = '(&(objectClass=person)(uid={username}))'
c.LDAPAuthenticator.user_membership_attribute = 'memberOf'
c.LDAPAuthenticator.group_search_base = 'cn=groups,cn=accounts,dc=cdp,dc=local'
c.LDAPAuthenticator.group_search_filter = '(&(objectClass=ipausergroup)(memberOf={group}))'Principaux avantages de cette solution :
- Disposer de trois interpréteurs (Python, Scala et R) ;
- Personnalisation des ressources Spark via le fichier
config.json; - Pas d’accès direct au cluster par les utilisateurs ;
- Possibilité d’avoir plusieurs environnements Python ;
- Connexion de JupyterHub via un serveur LDAP.
Principaux inconvénient de cette solution :
- Dérives de personnalisations (utilisation de trop de ressources, mauvaise configuration, etc…) ;
- Modification de la configuration du cluster ;
- Déploiement plus complexe ;
- Un notebook dispose d’un seul interpréteur.
Conclusion
Si vous développez des jobs Spark et que les solutions historiques telles que Zeppelin ne vous conviennent plus ou que vous êtes limités par sa version, vous pouvez dès à présent déployer à moindre frais un serveur Jupyter afin de développer vos jobs tout en profitant des ressources de vos clusters.
