


Surveillance d'un cluster Hadoop de production avec Kubernetes

21 déc. 2018
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
La surveillance d’un cluster Hadoop de production est un vrai challenge et se doit d’être en constante évolution. Aujourd’hui, la solution que nous utilisons se base sur Nagios. Efficace en ce qui concerne la surveillance la plus simple, elle n’est pas en mesure de répondre aux besoins de lancement de vérifications plus poussés.
Dans cet article, nous proposerons une architecture que nous souhaitons développer utilisant Kubernetes. Ce projet est en cours de développement et va encore évoluer dans les prochains mois. Tout d’abord, nous présenterons notre infrastructure actuelle, ses limites ainsi que nos besoins. Dans un second temps, nous verrons comment une architecture Kubernetes peut nous aider. Enfin, nous proposerons une façon de mettre en place cette infrastructure.
De la difficulté de surveiller un cluster Hadoop
Notre besoin se définit simplement : nous devons nous assurer qu’à tout moment, toutes les chaînes de connexions à nos clusters Hadoop fonctionnent avec un temps de réponse acceptable.
Ce n’est pas chose aisée ! Par exemple, pour lire une valeur dans une table HBase, les applications peuvent utiliser :
- une connexion Java via Thrift
- une connexion HTTP via HBase Rest
- une connexion HTTP via la passerelle Knox
- une connexion JDBC via Phoenix
Ces appels peuvent provenir de job Spark, YARN, être externes au cluster, et chacun utilisant une authentification via Kerberos ou LDAP.
Lorsqu’il s’agit de faire du support au client, l’objectif est toujours de reproduire le comportement qui tombe en erreur ou qui est trop lent. Cela consiste le plus souvent à envoyer une requête vers un service du cluster. Cette requête peut être envoyée via les outils CLI (beeline, Hbase shell…) ou au travers du lancement d’une application YARN par exemple. A chaque fois, nous souhaiterions pouvoir exécuter à nouveau ce test de manière périodique pour être prévenu en cas d’erreur.
Aujourd’hui, notre monitoring utilise Shinken, un fork de Nagios. A l’origine, il fut installé afin de surveiller et redémarrer les services Hadoop. Au fil des années ont été ajoutées de nombreuses surveillances plus “intelligentes”, comme des chaînes de connexion. Shinken n’est pas adapté à cette utilisation. Il en résulte des instabilités et des difficultés croissantes à se fier à Shinken pour notre surveillance. Il est très complexe de lancer des vérifications plus lourdes comme celles nécessitant les configurations clientes de connexion.
Kubernetes
Les vérifications orchestrées par Shinken sont exécutées dans un container Docker, afin de déployer simplement le script de test avec ses dépendances (comme un environnement Python). Suivant cette logique, nous pouvons exécuter chacun de nos tests dans un container. L’image contiendra le code du script et ses dépendances.
Les prochaines étapes consistent à exécuter ces vérifications périodiquement, obtenir leurs résultats, les afficher et alerter en cas de problèmes. Pour cela nous utiliserons Kubernetes. C’est un choix assez logique car il nous permet de mettre à disposition une infrastructure pour exécuter des containers de manière périodique. Il est de plus très demandé de surveiller les temps de réponse, mesurer des taux de disponibilités et de visualiser des tableaux de bords. Shinken ne répond pas à ces besoins.
Ecriture d’une image
L’écriture d’une image de test doit être très simple afin de pouvoir l’ écrire sans perdre de temps. Pour cela, le contrat d’interface entre le script et notre infrastructure doit être léger.
Nous avons identifié trois possibilités :
- Ecrire un objet sérialisé via
stdout - Ecrire un objet sérialisé dans un port défini
- Ecrire un objet sérialisé dans un fichier
Nous ne souhaitons pas directement écrire dans une base de données. En effet cela impliquerait d’intégrer une logique complexe dans notre image et nous perdrions une grande partie de notre flexibilité. Le contrat le plus simple est le premier mais risque d’être trop limité. Les deux autres nécessitent une logique supplémentaire entre le test et l’infrastructure : plus complexe mais pas insurmontable. Cette partie nécessitera d’essayer et nous pourrons ainsi définir ce qui fonctionne le mieux.
Lecture du résultat
Une fois l’exécution terminée, nous souhaitons lire et stocker le résultat. Il faut donc s’attacher au container sans perturber son exécution.
Deux architectures sont possibles :
Node agent
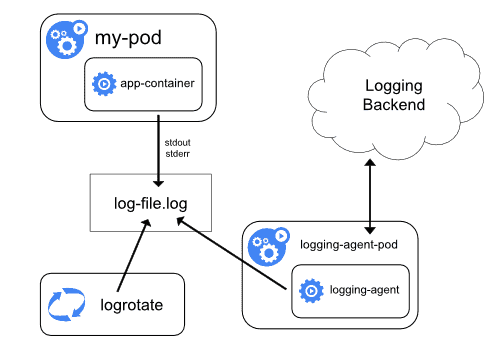
Sur chacun des noeuds du cluster Kubernetes, un container agent va être exécuté en parallèle des autres containers. Son rôle est simple : il va lire les logs de tous les containers et les envoyer dans une base de données. C’est le seul container qui a connaissance de la base de données et qui en a l’accès en écriture. On peut également lancer plusieurs agents sur un noeud, chacun connecté à une base de données différente pour gérer les différents cas d’usage.
Néanmoins, cela fonctionne uniquement en ce qui concerne stdout et stderr. C’est souvent suffisant mais pour des applications plus complexes il est nécessaire d’utiliser un container sidecar.
Sidecar container
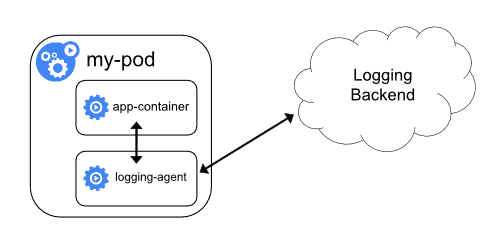
Un sidecar est un container s’exécutant dans le même pod que notre test. Comme il partage le même espace réseau et le même noeud physique, il est possible d’échanger facilement entre ces deux containers (via localhost ou des montages de volume). C’est un peu plus complexe que de logger au niveau du noeud mais beaucoup plus flexible en ce qui concerne la variété des sources.
Mise à disposition
Ces métriques doivent ensuite être mises à disposition pour consultation.
Pour cela, le plus simple est une base de données connue comme Elasticsearch qui peut simplement être lue par Grafana pour créer des dashboards et des alertes.
Récapitulatif
Récapitulons ce dont nous avons besoin :
- Des images Docker contenant un script et ses dépendances qui va tester un composant du cluster
- Un cluster Kubernetes capable d’exécuter ces containers de manière périodique et de stocker les configurations
- Des agents de logging, qui vont récupérer les résultats des tests et les envoyer dans une ou plusieurs bases de données
- Des bases de données servant d’historique. Elles serviront pour consulter et alerter sur l’état du cluster
