Configuration à distance et auto-indexage des pipelines Logstash

13 déc. 2019
- Catégories
- Data Engineering
- Infrastructure
- Tags
- Docker
- Elasticsearch
- Kibana
- Logstash
- Log4j [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Logstash est un puissant moteur de collecte de données qui s’intègre dans la suite Elastic (Elasticsearch - Logstash - Kibana). L’objectif de cet article est de montrer comment déployer un cluster Logstash entièrement géré, incluant l’accès aux logs et aux pipelines configurables à distance.
Auparavant, la suite Elastic avait deux problèmes lorsqu’il s’agissait d’un service entièrement géré : Kibana ne supportait pas Elasticsearch High Availabilty et Logstash Pipelines n’était pas configurable à distance.
Ces deux problèmes sont résolus depuis ELK 6, Kibana supporte maintenant plusieurs hôtes (et peut autodécouvrir de nouveaux hôtes) et les pipelines logstash peuvent être modifiées directement sur Kibana en utilisant la [gestion centralisée des pipelines (Centralized Pipeline Management)] (https://www.elastic.co/guide/en/logstash/current/logstash-centralized-pipeline-management.html).
Configurer la gestion centralisée des pipelines
La gestion centralisée des pipelines est disponible depuis ELK 6.0 et nécessite une licence Elasticsearch Gold ou Platinium valide. Si vous n’en avez pas, ne vous inquiétez pas ! Vous ne pourrez pas modifier les pipelines sur Kibana mais le reste du billet du blog sera toujours pertinent.
Le fonctionnement de la gestion des pipelines est simple : la configuration des pipelines est stockée sur Elasticsearch sous l’index .logstash. Un utilisateur ayant un accès d’écriture à cet index peut configurer les pipelines via une interface graphique sur Kibana (sous Settings -> Logstash -> Pipeline Management)

Sur les instances de Logstash, vous devez définir quels pipelines doivent être gérés à distance. Logstash vérifiera alors régulièrement les modifications et les appliquera. Une fois la gestion à distance activée, la configuration locale des pipelines ne s’appliquera plus.
Voici un extrait de ce à quoi ressemble le fichier logstash.yml :
...
xpack:
management:
enabled: true
elasticsearch:
hosts:
- 'host1.mydomain:9200'
- 'host2.mydomain:9200'
- 'host3.mydomain:9200'
username: logstash_admin_user
password: MySecretPassword
ssl:
certificate_authority: /usr/share/logstash/config/certs/cacert.pem
pipeline:
id:
- logstash_logs
- client_pipeline1
- client_pipeline2Si vous livrez ceci à un client dans un environnement sécurisé, vous devez établir avec lui :
- Combien de pipelines sont nécessaires, puisque l’ajout d’une pipeline est une opération administrateur et nécessite le redémarrage des instances Logstash.
- Si les pipelines sont à l’écoute des connexions (écouter du contenu Filebeat par exemple), vous devrez ouvrir les ports où le client peut écouter.
- Si vous utilisez SSL en utilisant vos propres certificats, n’oubliez pas de rendre le CACert lisible par le processus Logstash.
Trucs et astuces :
- Créez le pipeline sur Kibana avant de démarrer votre instance Logstash ! Si le pipeline n’est pas créé, Logstash ne démarrera pas correctement. Seul le pipeline vide par défaut fera l’affaire.
logstash_admin_usernécessite les droits suivants :- CRUD sur l’index
.logstash*(disponible dans le rôle par défautlogstash_admin) - Privilèges du cluster :
manage_index_templates,monitor,manage_ilm
- CRUD sur l’index
Donner accès aux logs de Logstash sur Kibana
Les modifications sur la définition du pipeline sont appliquées sur vos instances Logstash, génial ! Mais l’utilisateur se plaint que ses pipelines ne fonctionnent pas et veut accéder aux logs Logstash pour voir pourquoi. En tant qu’administrateur, vous ne voulez pas que l’utilisateur accède directement aux logs sur la machine. Pourquoi ne pas utiliser le cluster Elasticsearch pour indexer les logs Logstashs ? Voyons comment faire !
Faire écrire Logstash dans les fichiers (sur Docker)
Logstash utilise log4j2 pour gérer son logging. Le fichier par défaut log4j2.properties est disponible sur le repo GitHub de Logstash. Sachez qu’un fichier log4j2.properties très simplifié est expédié à l’intérieur de l’image Docker officielle. Cette version simplifiée n’écrira que les logs standard dans stdout.
Ce que nous voulons réaliser ici, c’est :
- Écrire les logs dans un fichier
- Pouvoir faire un rollover du fichier en fonction de la date et/ou de la taille
- Rendre ce fichier disponible sur la machine hôte (lors de l’utilisation du Docker)
Le fichier par défaut log4j2.properties gérera le rollover, mais il écrira aussi dans stdout.
Désactiver la connexion à stdout
Je ne recommande pas de diregier les logs vers la console quand vous pourriez utiliser des fichiers à la place. Surtout sur Docker, où cela finira probablement par remplir un système de fichiers dont vous n’avez pas le contrôle.
Pour désactiver la connexion à la console, commentez ces deux lignes dans votre log4j2.properties (si vous utilisez celui par défaut). Vous pourrez le réactiver dynamiquement à l’aide de l’API Logstash.
#rootLogger.appenderRef.console.ref = ${sys:ls.log.format}_console
#logger.slowlog.appenderRef.console_slowlog.ref = ${sys:ls.log.format}_console_slowlogDéfinir le chemin et le format du journal
Je recommande d’utiliser le format PLAIN et non le format JSON. Il est beaucoup plus facile à lire et pas si difficile à analyser. Placez ces propriétés dans votre configuration logstash.yml.
path.logs: /usr/share/logstash/logs
log.format: plain(Docker uniquement) Créer un utilisateur Logstash sur la machine hôte
Puisque nous voulons que nos conteneurs Logstash puissent écrire sur notre machine hôte, nous devons créer un utilisateur avec des permissions d’écriture dans notre fichier log. L’utilisateur doit avoir le même UID dans le conteneur et sur la machine hôte. Par défaut, l’utilisateur “logstash” dans le conteneur se verra assigner l’UID 1000 qui sera souvent associé à “root”, ce qui n’est pas quelque chose que vous voulez faire.
# Sur la machine hôte
groupadd -g 1010 logstash
useradd -u 1010 -c "Logstash User" -d /var/lib/logstash -g logstash logstash
mkdir /var/logs/logstash/mycluster/logstash_logs
chown -R logstash:logstash /var/logs/logstash/mycluster/logstash_logsNous venons de créer un groupe “logstash” avec un GID spécifié (1010), un utilisateur “logstash” avec un UID spécifié (1010) et l’avons placé dans son groupe. Nous avons également créé un répertoire dans lequel le conteneur Logstash peut écrire.
(Docker uniquement) Changer l’utilisateur et l’UID dans le conteneur Logstash
Nous avons besoin de modifier un peu notre image Docker pour refléter notre nouvel utilisateur “logstash”. Ce fichier Docker fonctionne avec la version 7.3 de Logstash.
FROM logstash:7.3.1
USER root
RUN groupmod -g 1010 logstash && usermod -u 1010 -g 1010 logstash && chown -R logstash /usr/share/logstash && \
sed -i -e 's/--userspec=1000/--userspec=1010/g' \
-e 's/UID 1000/UID 1010/' \
-e 's/chown -R 1000/chown -R 1010/' /usr/local/bin/docker-entrypoint && chown logstash /usr/local/bin/docker-entrypoint
USER logstashPour construire l’image : docker build --rm -f Dockerfile -t logstash-set-user:7.3.1 .
Nous devrons alors utiliser l’image logstash-set-user:7.3.1 au lieu de celle par défaut.
Gérez vos points de montage dans votre fichier docker-compose (Docker uniquement)
Lorsque vous utilisez un fichier de composition pour déployer votre Logstash, vous pouvez déclarer :
...
services:
logstash:
user: logstash
volumes:
- '/etc/elasticsearch/mycluster/logstash/conf/logstash.yml:/usr/share/logstash/config/logstash.yml'
- '/etc/elasticsearch/mycluster/logstash/conf/log4j2.properties:/usr/share/logstash/config/log4j2.properties'
- '/var/log/elk/mycluster/logstash:/usr/share/logstash/logs'
image: 'logstash-set-user:7.3.1'Ajouter un pipeline qui collecte les logs et les envoie à Elasticsearch
La définition de pipeline que j’utilise à cette fin est la suivante :
input {
file {
path => "/usr/share/logstash/logs/*.log"
sincedb_path => "/usr/share/logstash/logs/sincedb"
}
}
filter {
grok {
match => { "message" => "\[%{TIMESTAMP_ISO8601:tstamp}\]\[%{LOGLEVEL:loglevel} \]\[%{JAVACLASS:class}.*\] %{GREEDYDATA:logmessage}" }
}
date {
match => ["tstamp", "ISO8601"]
}
mutate {
remove_field => [ "tstamp" ]
}
}
output {
elasticsearch {
hosts => ["host1.mydomain:9200", "host2.mydomain:9200", "host3.mydomain:9200"]
index => "logstash_logs-%{+YYYY.MM.dd}"
user => "logstash_logs_user"
password => "MySecretPassword"
ssl => true
cacert => "/usr/share/logstash/config/certs/cacert.pem"
}
}C’est très simple : il vérifie les fichiers dans mon répertoire de logs. Lorsqu’il en trouve un, il analyse un peu le contenu pour en extraire le timestamp, le niveau du journal, la classe et le message. Il remplace également le timestamp par celui disponible dans les journaux (s’il n’est pas défini, Logstash utilisera le timestamp de l’heure actuelle à la lecture du répertoire de log). Ces logs sont ensuite envoyés au cluster Elasticsearch dans l’index logstash_logs-(+ date).
Quelques notes :
- Vous pouvez également utiliser Filebeat à cette fin. Je ne l’ai pas fait parce qu’il faudrait ajouter encore plus de contenants. L’utilisateur peut également désactiver le pipeline (il suffit de commenter la section d’input).
- Mon filtre grok n’est pas parfait, il ne gère pas la journalisation multilignes mais correspond à mes besoins.
- Si vous n’avez pas de licence X-Pack, vous pouvez toujours utiliser ce pipeline sauf que vous ne pourrez pas le configurer sur Kibana.
- Un champ nommé “host” est ajouté automatiquement par Logstash. Vous pouvez utiliser ce champ pour filtrer si vous avez plusieurs instances Logstash.
Résultats sur Kibana
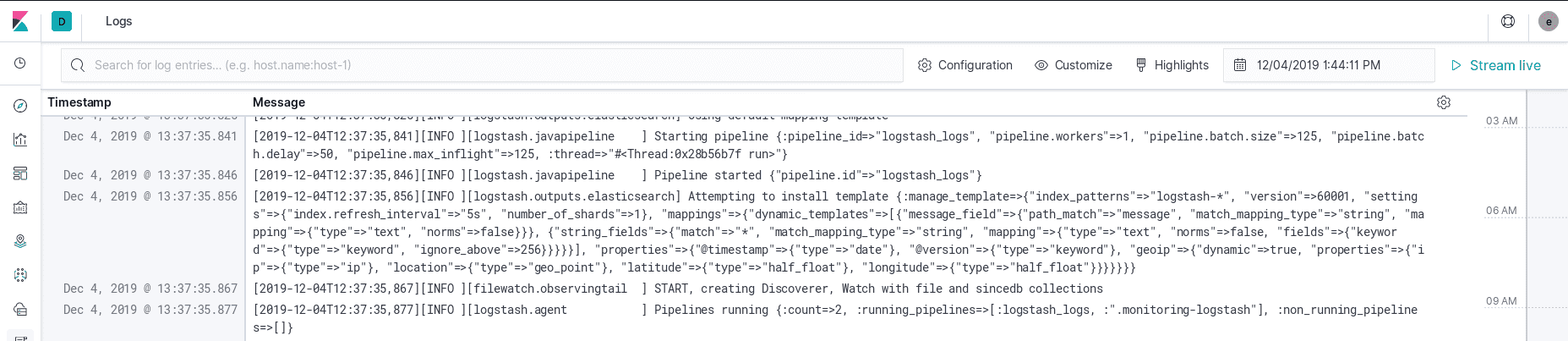
Nous pouvons maintenant utiliser Kibana pour voir les logs de nos instances Logstash.
Nous pouvons utiliser l’onglet “Discover”.

Ou l’onglet “Logs” très pratique. C’est comme si on utilisait tail -f sur le fichier !