


Apache Liminal, quand le MLOps rencontre le GitOps

31 mars 2021
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Apache Liminal propose une solution clés en main permettant de déployer un pipeline de Machine Learning. C’est un projet open-source, qui centralise l’ensemble des étapes nécessaires à l’entrainement de modèles de Machines Learning, de la préparation des données au déploiement du modèle.
Cette solution propose une approche déclarative à vos projets orientés MLOps. La pipeline représentant les différent étapes pour la préparation, la construction et le déploiement de vos modèles de Machine Learning est décrite en YAML.
Le fichier et les scripts Python qu’il référence sont aisément versionnés dans un outil comme Git ouvrant la voie à un workflow the type GitOps. Le terme GitOps décrit une architecture dans laquelle un système est reproductible à partir de l’état stocké dans un dépôt Git. De plus, grâce à Git, les data engineers et les data scientists peuvent collaborer ensemble et faire évoluer le modèle.
Liminal s’appuie sur Apache Airflow, Docker et Kubernetes afin de créer et de déployer votre pipeline.
L’installation
Pour reproduire les commandes de cet article, Apache Liminal requière l’installation de Docker et Kubernetes sur votre machine. Kubernetes peut être installé avec minikube.
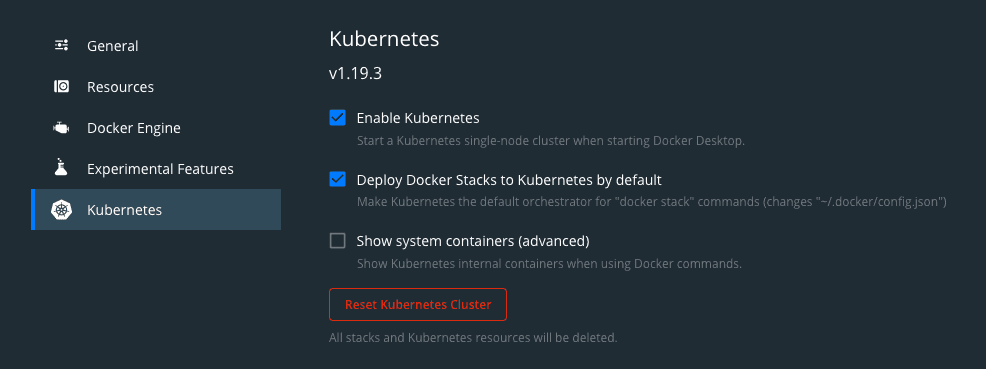
Si vous êtes sur MacOS et que Docker est déjà installé, le plus simple est d’activiter le support Kubernetes en cliquant sur le bouton “Deploy Docker Stacks to Kubernetes by default” dans Docker Desktop.
Nous installons Apache Liminal via pip.
pip install git+https://github.com/apache/incubator-liminal.gitCréation d’un pipeline Liminal
Création des scripts Python
Nous allons tous d’abord commencer par créer un répertoire à la racine de notre projet afin de stocker l’ensemble des scripts Python nécessaires à la création de notre pipeline.
Le premier fichier que nous allons créer est requirements.txt. En effet ce fichier est nécessaire afin qu’Apache Liminal installe les différents packages Python nécessaires au fonctionnement de nos scripts sur les images Docker générées. Dans notre exemple nous avons besoin des packages suivants :
urllib3
pandas
numpy
tensorflow
scikit-learnDans notre cas la préparation des données consiste simplement à aller récupérer le fichier wine-quality.csv qui sert à entrainer notre modèle. Ces données seront directement accéssibles depuis les pods.
Nous allons donc créer un fichier download.py qui ira récupérer le fichier et nettoyer les noms des champs :
#!/usr/bin/env python
import urllib3
import pandas as pd
import numpy as np
import os
PATH = "/mnt/data/"
file_path = str(PATH) + "file.csv"
http = urllib3.PoolManager()
url = os.environ['url']
r = http.request('GET', url)
if os.path.exists(file_path):
os.remove(file_path)
else:
print("file not exist")
with open(file_path, 'xb') as f:
f.write(r.data)
dataset = pd.read_csv(file_path)
for field in dataset.columns:
if type(dataset[field][0]) == np.int64 :
new_field = field.replace(' ', '_')
dataset = dataset.rename(columns={field : new_field})
print('i - field = ' + str(new_field))
elif type(dataset[field][0]) == np.float64 :
new_field = field.replace(' ', '_')
dataset = dataset.rename(columns={field : new_field})
print('f - field = ' + str(new_field))
dataset.to_csv(file_path, index=False)Ici nous récupérons le fichier via une variable d’environnement url qui est définie dans le script YAML de la manière suivante :
env_vars:
url: "https://raw.githubusercontent.com/mlflow/mlflow/master/examples/sklearn_elasticnet_wine/wine-quality.csv"Ensuite, nous créons un script python qui nous permet d’entrainer notre modèle, nous l’appellerons wine_linear_regression.py :
#!/usr/bin/env python
import os
import sys
import numpy as np
import pandas as pd
import tensorflow as tf
from six.moves import urllib
from sklearn.model_selection import train_test_split
## Load Dataset
PATH = "/mnt/data/"
path = str(PATH) + "file.csv"
dataset = pd.read_csv(path)
labels = dataset['quality'].tolist()
dataset = dataset.drop(["quality"], axis=1)
x_train, x_test, y_train, y_test = train_test_split(dataset,
labels,
train_size=0.9)
NUMERIC_COLUMNS = ['alcohol', 'chlorides', 'citric_acid', 'density', 'fixed_acidity',
'free_sulfur_dioxide', 'pH', 'residual_sugar', 'sulphates', 'total_sulfur_dioxide',
'volatile_acidity']
CATEGORICAL_COLUMNS = ['quality']
feature_columns = []
for feature_name in NUMERIC_COLUMNS:
feature_columns.append(tf.feature_column.numeric_column(feature_name, dtype=tf.float32))
def make_input_fn(data_df, label_df, num_epochs=10, shuffle=True, batch_size=32):
def input_function():
ds = tf.data.Dataset.from_tensor_slices((dict(data_df), label_df))
if shuffle:
ds = ds.shuffle(1000)
ds = ds.batch(batch_size).repeat(num_epochs)
return ds
return input_function
train_input_fn = make_input_fn(x_train, y_train)
eval_input_fn = make_input_fn(x_test, y_test, num_epochs=1, shuffle=False)
linear_est = tf.estimator.LinearRegressor(
feature_columns=feature_columns,
model_dir=str(PATH) + "train"
)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
print("--> OUTPUT = " + str(result))
def serving_input_receiver_fn():
inputs = {}
for feat in feature_columns:
inputs[feat.name] = tf.compat.v1.placeholder(shape=[None], dtype=feat.dtype)
print("--> INPUTS = " + str(inputs))
return tf.estimator.export.ServingInputReceiver(inputs, inputs)
linear_est.export_saved_model(export_dir_base=str(PATH) + "model", serving_input_receiver_fn=serving_input_receiver_fn)Enfin nous allons créer un script python permettant de comparer le dernier modèle entrainé avec celui en production afin de garder le meilleur modèle en production. Nous nommerons ce fichier validation.py :
import pandas
import random
from pathlib import Path
import tensorflow as tf
import numpy as np
import sys
import os
PATH = "/mnt/data/"
# Load last model
model_dir = str(PATH) + "model"
subdirs = [x for x in Path(model_dir).iterdir()
if x.is_dir() and 'temp' not in str(x)]
latest = str(sorted(subdirs)[-1])
print("--> LATEST = " + str(latest))
# Load model in prod
model_prod_dir = str(PATH) + "model_prod"
if not os.path.exists(model_prod_dir):
os.makedirs(model_prod_dir)
subdirs_prod = [x for x in Path(model_prod_dir).iterdir()
if x.is_dir() and 'temp' not in str(x)]
if not subdirs_prod:
os.rename(latest, model_prod_dir + "/" + latest.split("/")[-1])
sys.exit(0)
latest_prod = str(sorted(subdirs_prod)[-1])
print("--> PROD = " + str(latest_prod))
# Read file and select 10% of random row
randomlist = []
df = pandas.read_csv(str(PATH) + 'file.csv')
nb_raw = len(df)
for i in range(0, int((nb_raw/10))):
n = random.randint(0,nb_raw)
if n<nb_raw and n>=0:
randomlist.append(n)
else:
print(" _BAD_RANDOM_ ")
# Predict on random row
## Load TensorFlow model
def build_predict(df, model):
res = model(chlorides=tf.constant(df['chlorides'], dtype=tf.float32, shape=1),
alcohol=tf.constant(df['alcohol'], dtype=tf.float32, shape=1),
citric_acid=tf.constant(df['citric_acid'], dtype=tf.float32, shape=1),
residual_sugar=tf.constant(df['residual_sugar'], dtype=tf.float32, shape=1),
total_sulfur_dioxide=tf.constant(df['total_sulfur_dioxide'], dtype=tf.float32, shape=1),
free_sulfur_dioxide=tf.constant(df['free_sulfur_dioxide'], dtype=tf.float32, shape=1),
pH=tf.constant(df['pH'], dtype=tf.float32, shape=1),
fixed_acidity=tf.constant(df['fixed_acidity'], dtype=tf.float32, shape=1),
sulphates=tf.constant(df['sulphates'], dtype=tf.float32, shape=1),
density=tf.constant(df['density'], dtype=tf.float32, shape=1),
# quality=tf.constant(df['quality'], dtype=tf.int64, shape=1),
volatile_acidity=tf.constant(df['volatile_acidity'], dtype=tf.float32, shape=1)
)
return res
model = tf.saved_model.load(export_dir=str(latest)).signatures['predict']
model_prod = tf.saved_model.load(export_dir=str(latest_prod)).signatures['predict']
pred = []
pred_prod = []
score_train=0
score_prod=0
## Compare prediction with the real value
for x in randomlist:
value = df.drop(["quality"], axis=1).iloc[x]
real = df['quality'].iloc[x]
pred_train = round(np.array(build_predict(value, model)['predictions'])[0][0])
if real == pred_train:
score_train += 1
pred_prod = round(np.array(build_predict(value, model_prod)['predictions'])[0][0])
if real == pred_prod:
score_prod += 1
print("score_train : " + str(score_train))
print("score_prod : " + str(score_prod))
## Replace new model in prod if it better than the last, Predict on random rows
if score_train > score_prod:
model_old_dir = str(PATH) + "model_old"
if not os.path.exists(model_old_dir):
os.makedirs(model_prod_dir)
os.rename(latest_prod, str(PATH) + "model_old/" + latest_prod.split("/")[-1])
os.rename(latest, model_prod_dir + "/" + latest.split("/")[-1])Création du pipeline
À présent nous allons créer à la racine de notre projet un fichier YAML que nous appellerons ici liminal.yml.
Tous d’abord nous allons déclarer le montage de nos volumes. D’abord nous allons créer un volume kubernetes nommé data avec le repertoire courant où est situé le fichier liminal.yml.
name: GettingStartedPipeline
volumes:
- volume: data
local:
path: .Par la suite, nous allons déclarer de quelle manière nous souhaitons que notre pipeline s’exécute au travers d’une tasks.
Une tasks est un ensemble de task qui se caractérise par :
taskqui sera le nom de la tâche. (attention chaque tâche doit avoir un nom unique)typequi est le type de script utilisé, dans notre cas nous utiliseront des scripts pythondescriptionqui permet de décrire l’objectif de la tâcheimagequi permet d’indiquer à quelles images le script sera associésourcequi permet d’indiquer le répertoire où le script python se situecmdqui permet de personnaliser la commande d’execution du scriptmountschaque tâche montera en interne le volume défini ci-dessus dans un repertoireenv_varscomme indiqué précédemment nous pouvons provisionner des variables d’environnement directement dans l’image
Chacune des tâches est lancée par le Dag Airflow dans un pod distinct. Dans notre cas elles partagent toute la même image déclarée dans la section image de chacune des tâches ainsi que le même point de montage indiqué dans mounts.
name: GettingStartedPipeline
volumes:
- volume: data
local:
path: .
pipelines:
- pipeline: getting_started_pipeline
owner: Aargan
start_date: 1970-01-01
timeout_minutes: 10
schedule: 0 * 1 * *
default_array_loaded: [2, 3, 4]
default_object_loaded:
key1: val1
key2: val2
metrics:
namespace: TestNamespace
backends: [ ]
tasks:
- task: load_data
type: python
description: Load Dataset
image: python_hello_world_example_image
source: pythonscript
mounts:
- mount: mymount
volume: data
path: /mnt/data
cmd: python -u download.py
env_vars:
url: "https://raw.githubusercontent.com/mlflow/mlflow/master/examples/sklearn_elasticnet_wine/wine-quality.csv"
- task: training_model
type: python
description: training model
image: python_hello_world_example_image
source: pythonscript
mounts:
- mount: mymount
volume: data
path: /mnt/data
cmd: python -u wine_linear_regression.py
- task: validation_model
type: python
description: validation model
image: python_hello_world_example_image
source: pythonscript
mounts:
- mount: mymount
volume: data
path: /mnt/data
cmd: python -u validation.pyLancer Apache Liminal
Maintenant nous déployons notre pipeline en utilisant les commandes suivantes :
liminal build
liminal deploy --clean
liminal startLiminal est démarré. Nous accéder à l’interface d’Apache Airflow via l’adresse suivante : http://127.0.0.1:8080
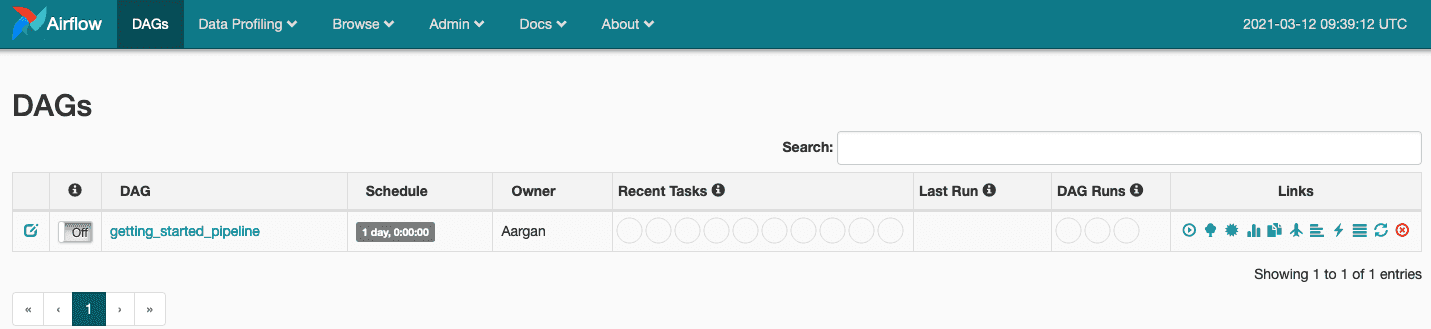
Il n’y a plus qu’à activer le DAG et notre pipeline démarrera automatiquement.
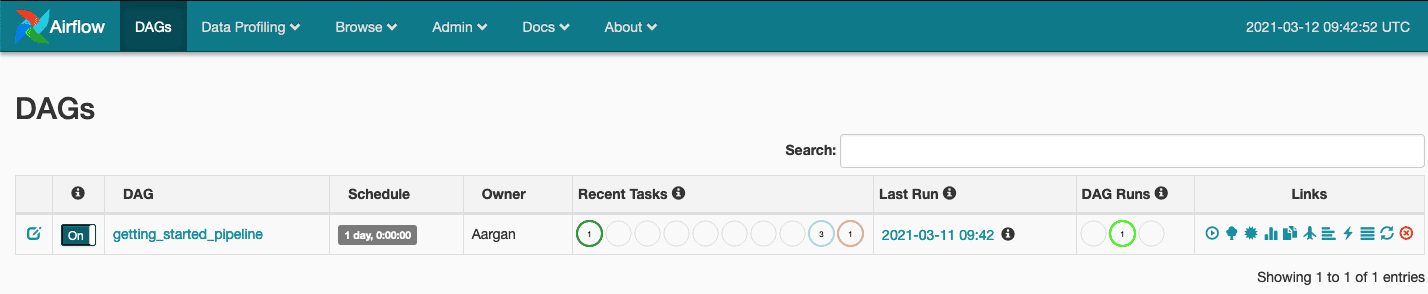
Nous pourrons observer l’exécution de notre DAG et accéder aux logs au travers de la Tree View (voir article Premier pas avec Apache Airflow sur AWS si vous souhaitez mieux comprendre les fonctionnalités de Apache Airflow)
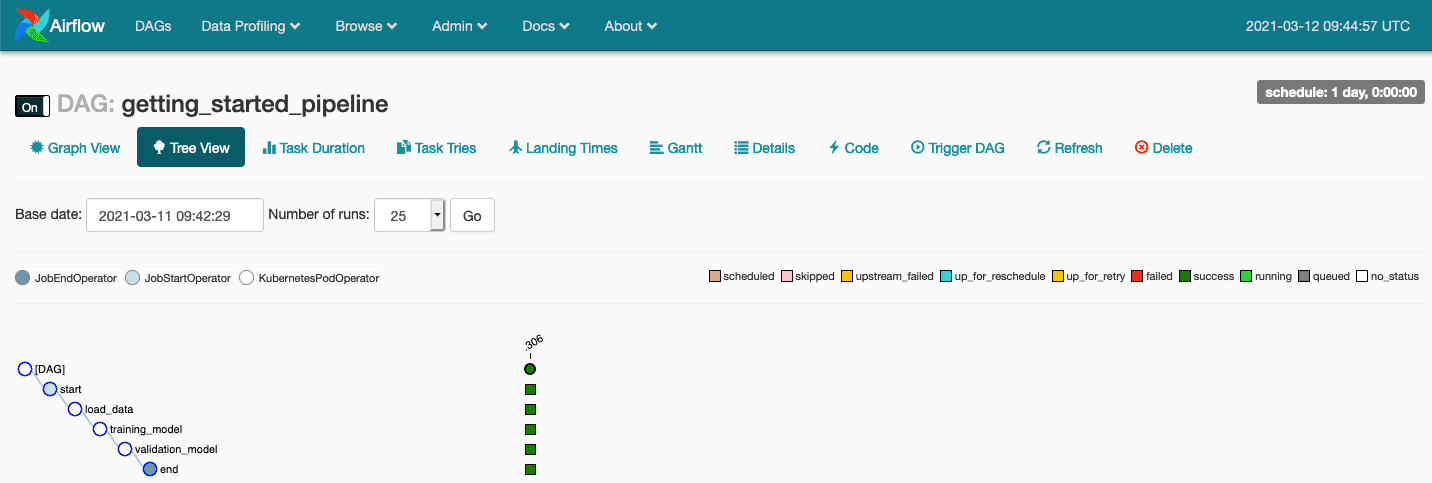
Maintenant que l’exécution de notre pipeline est terminée nous stoppons notre serveur Liminal en utilisant de la commande :
liminal stopConclusion
Apache Liminal est une solution simplifiant la création de pipelines de Machine Learning. Comme nous avons pu le constater au sein de cet article, le pari est réussi. En effet, un fichier YAML permet de décrire le fonctionnement de vos pipelines de Machines Learning, en y introduisant l’ensemble des étapes nécessaires afin d’avoir une vraie cohérence au sein de vos projets.
De plus, le projet s’appuyant sur Kubernetes il est possible de déployer vos pipelines vers un cluster distant :
# Cette fonctionnalité n'a pas été testée dans le cadre de cet article
kubectl config set-context <your remote kubernetes cluster>Pour finir, le déploiement d’Apache Liminal se faisant au travers de fichiers déclaratif, il est aisé donc d’automatiser au travers d’un pipeline CI/CD le versionnement, le déploiement et l’exploitation de vos pipelines.
