


Premier pas avec Apache Airflow sur AWS

5 mai 2020
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Apache Airflow offre une solution répondant au défi croissant d’un paysage de plus en plus complexe d’outils de gestion de données, de scripts et de traitements d’analyse à gérer et coordonner. C’est est une solution open-source visant à simplifier la création, l’orchestration ainsi que le monitoring de vos différents traitements. Le projet est issu des équipes de AirBnb en 2014 pour arriver à gérer un nombre toujours plus important de workflow.
Airflow vous offre donc la possibilité de créer des DAGs (Directed Acyclic Graph) grâce au langage Python, qui vont tous simplement vous permettre de créer des ensembles de tâches qui peuvent être connectés et déprendre les une des autres afin de réaliser vos flux.
Installation
L’installation de Airflow se fait au travers de pip.
# Guide d'installation Airflow : https://airflow.apache.org/docs/stable/start.html
# airflow needs a home, ~/airflow is the default,
# but you can lay foundation somewhere else if you prefer
# (optional)
export AIRFLOW_HOME=~/airflow
# install from pypi using pip
pip install apache-airflow
# initialize the database
airflow initdb
# start the web server, default port is 8080
airflow webserver -p 8080
# start the scheduler
airflow schedulerUne fois Airflow démarré, rendez vous à l’adresse localhost:8080 dans votre navigateur et activez l’exemple DAG depuis la page d’accueil.
La majeure partie de la configuration de Airflow se réalise dans le fichier airflow.cfg. Vous pouvez entre autre configurer :
- Connexion à un annuaire LDAP
- Configuration d’un mail smtp
- La configuration du webserver
- La configuration des différents opérateurs
Il existe six types d’installations possibles :
- Sequential_Executor : Lance les tâches une à une ;
- Local_Executor : Lance les tâches en parrallèle localement ;
- Celery_Executor : Celery est un des types d’executeur prévilégie, en effet il permet de répartir les traitements en parrallèle sur un grand nombre de noeuds ;
- Dask_Executor : ce type d’executeur permet a airflow de lancer ces différentes tâches dans un cluster python Dask ;
- Kubernetes_Executor : ce type d’executeur permet a airflow de créer ou grouper des tâches dans des pods Kubernetes. (Depuis la version 1.10 de Airflow)
- Debug_Executor : le DebugExecutor est conçu comme un outil de débogage et peut-être utilisé à partir d’IDE.
Dans le cadre de cet article, je me suis appuyé sur les fichiers airflow.cfg, le Dockerfile ainsi que le docker-compose-LocalExecutor.yml qui sont fournis sur le github de Mathieu ROISIL qui permet d’avoir une première approche technique de Airflow. En effet ils permettent de construire une image Docker de Airflow afin d’effectuer des tests rapidement. Note, l’environnement utilisé dans cette article s’appuie sur Linux. L’execution des containers sous Windows peut entrainer des ajustements.
Pour les besoins de l’article, j’ai modifié les fichiers afin de réaliser quelques exemples de DAGs autour de la plateforme Big Data d’Amazon AWS EMR.
L’objectif de cet article est de découvrir la technologie en créant 4 Dags :
- Le premier consiste à faire apparaître dans les logs la configuration du AWSCLI du container Docker.
- Le second installe AWSCLI sur une machine distante disposant de
ssh. - Le troisième configure le client AWSCLI avec vos identifiants.
- Le quatrième a pour objectif de lancer un cluster AWS EMR afin d’y exécuter un job PySpark.
Lancement des containers :
# clone the project
git clone https://github.com/AarganC/docker-ariflow
# go to the folder
cd docker-airflow/
# Create images
docker build --rm -t adaltas/docker-airflow .
# run Apacha Airflow in Local_Executor
docker-compose -f docker-compose-LocalExecutor.yml up -d
# visit localhost:8080 in the browser for access to UIDAGs
Les DAGs sont des fichiers python permettant d’implémenter la logic des workflows ainsi que leurs configurations sous forme de taches au travers de code python ou Bash.
Tous d’abord nous allons commencé par implémenter un DAG très simple qui va nous permettre d’afficher dans les logs notre DAG notre configuration AWSCLI.
from airflow import DAG
from airflow.operators import BashOperator
from datetime import datetime as dt
from datetime import timedelta
# Default _DAG_ parameters
default_args = {'owner': 'airflow', 'depends_past': False, 'start_date': dt(2020, 3, 23),
'retries': 0}
dag = DAG('task_example', default_args=default_args, schedule_interval='30 07 * * *')
task = BashOperator(task_id='show',
bash_command='aws configure list',
dag=dag)La variable default_args contient un dictionnaire d’arguements nécessaire à la création d’un DAG :
owner: le propriétaire du DAG ;depends_past: Permet d’interompre un DAG si une tâche n’a pas foncitonnée ;start_date: Date de démarrage du DAG. Si vous définnisez une date anterieure de deux ans lors de l’activation du DAG celui-ci va rattraper l’ensemble des journés manquantes. (Attention en LocalExecutor !)retries: Le nombre d’éssai qu’il peut réaliser.
Mais dans ce dictionnaire il est également possible de configurer entre autre l’envoi de mail automatique.
Il est également nécessaire de créer un objet de type DAG prenant ici trois paramètres :
- Le nom de la tâche
- Un dictionnaire d’arguments
- Le
schedule_intervalqui va nous permètres de programmé l’execution de notre DAG. Leschedule_intervalest au format crontab]
Ensuite, nous pouvons voir la création d’un objet de type BashOperator, il sera la seul et unique tâche de notre DAG task_example.
BashOperator prend par défaut trois paramètres :
task_idqui correspond au nom de notre tâchebash_commandest le paramètre contenant notre commandeBash.dagqui correspond à notre objectdagcréé précédemment.
Vous pouvez retrouver le résultat de l’exécution des taches de votre DAG directement dans votre DAG, cliquer sur votre DAG -> cliquer sur Tree View -> ici vous allez retrouver l’arbre d’execution de vos tâches.
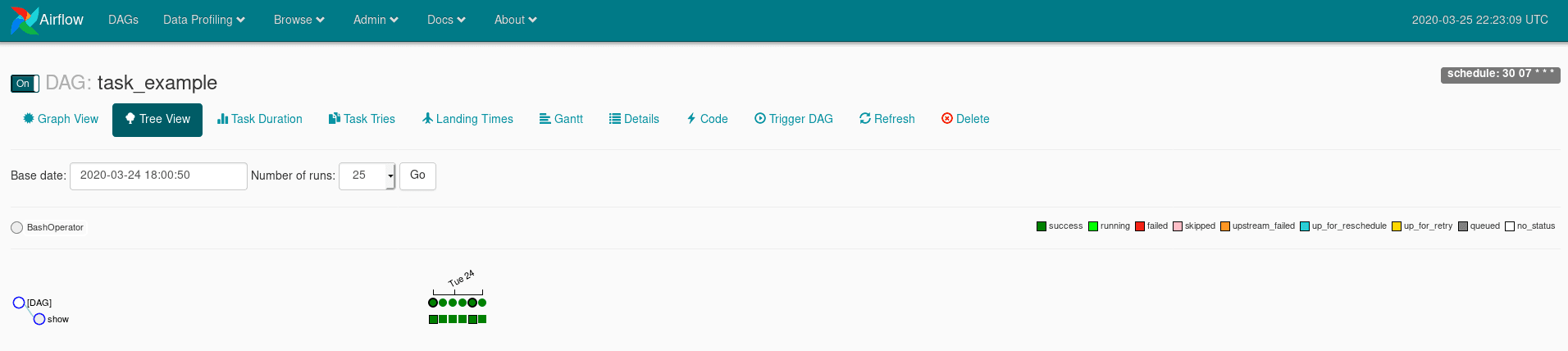
- chaque colonne est associée à une exécution ;
- chaque ligne est associée à une tâche (sauf la ligne
[DAG]) ; - si vous cliquez sur le rond, vous pourrez voir modifier les résultats d’exécution de votre DAG dans sa globalité ;
- si vous cliquez sur un des carrés vous pourrez obtenir des informations sur l’execution de vos tâches ainsi que leurs logs (http://localhost:8080/admin/variable/).
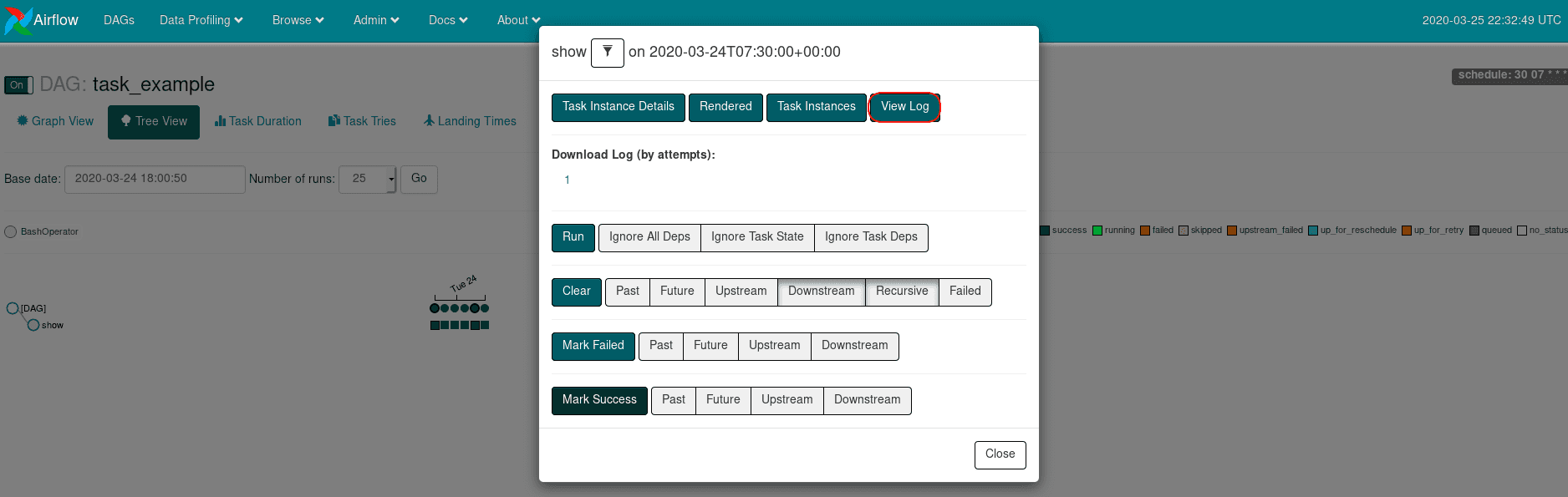
Ces DAGs peuvent s’appuyer sur un grand nombre d’outils afin de les rendre les plus modulables possibles.
Variables et Connection
Les Variables permettent d’appeler des variables propres à Airflow pouvant être défini dans Admin -> Variables.
Les Connection permettent d’automatiser des connections ssh, http, sft, ou autres afin de pouvoir les réutiliser rapidement. Cet exemple de DAG illustre comment installer le client AWSCLI où vous le souhaitez.
Il vous faut créer la variable Airflow directement depuis l’interface utilisateur en allant dans l’onglet Admin puis dans Variables.
Pour le fonctionnement du DAG, vous aurez besoin de créer les variables url_awscli et directory_dest qui dans mon cas correspondent à :
- url_awscli = https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip
- directory_dest =
/opt/AWS-CLI
Une connection SSH est utilisé pour l’installation du AWS-CLI sur un poste distant.
Tip : La valeur d’une Variable créée au travers de l’interface graphique sera masquée si cette variable contien les mots suivants :
- password
- secret
- passwd
- authorization
- api_key
- apikey
- access_token
from airflow import DAG
from airflow.models import Variable
from airflow.contrib.operators.ssh_operator import SSHOperator
from datetime import datetime as dt
# Default DAG parameters
default_args = {'owner': 'airflow', 'depends_past': False, 'start_date': dt(2020, 3, 23),
'retries': 0}
dag = DAG('variable_example', default_args=default_args, schedule_interval='30 07 * * *')
url_awscli = Variable.get("url_awscli")
directory_dest =Variable.get("directory_dest")
# Install aws CLI in ssh
cmd = """
mkdir -p {} \
curl "{}" -o "/tmp/awscli.zip" \
unzip /tmp/awscli.zip -d {} \
sudo {}aws/install \
rm /tmp/awscli.zip \
aws emr create-default-roles
""".format(directory_dest, url_awscli, directory_dest, directory_dest)
install_aws = SSHOperator(
ssh_conn_id='adaltas_ssh',
task_id='install_aws',
command=cmd,
dag=dag)Params
Airflow propose également la gestion de paramètres pour les tâches comme ici le dictionnaire Params.
Le DAG permet de préparer l’environnement en configurant le client AWSCLI et en créant les buckets S3 utilisé dans la suite de l’article.
Il aura besoin des variables Airflow suivantes qui pour moi corresponde à :
- secret_access_key : {AWS Access Key ID}
- secret_key : {AWS Secret Access Key}
- region : eu-west-1
- output_format : json
- bucket_log : au nom d’un bucket que j’ai créé pour stocker les logs de mes cluster AWS EMR
- bucket_pyton : au nom d’un bucket que j’ai créé pour stocker mes fichiers python
Tips : Vous pouvez regarder les templates de dictionnaire Jinja
from airflow import DAG
from airflow.models import Variable
from airflow.operators import BashOperator
from datetime import datetime as dt
from datetime import timedelta
# Default DAG parameters
default_args = {'owner': 'airflow', 'depends_past': False, 'start_date': dt(2020, 3, 23),
'retries': 0, 'sla': timedelta(hours=1)}
dag = DAG('variable_example', default_args=default_args, schedule_interval='30 07 * * *')
cmd = """
# Set aws credential
aws configure set aws_access_key_id {{ params.secret_access_key }}
aws configure set aws_secret_access_key {{ params.secret_key }}
aws configure set region {{ params.region }}
aws configure set output_format {{ params.output_format }}
# Create bucketif not exist
if aws s3 ls "s3://{{ params.bucket_log }}" 2>&1 | grep -q 'NoSuchBucket'
then
aws s3api create-bucket --bucket {{ params.bucket_log }} --region {{ params.region }}
fi
if aws s3 ls "s3://$bucket_pyton" 2>&1 | grep -q 'NoSuchBucket'
then
aws s3api create-bucket --bucket {{ params.bucket_pyton }} --region {{ params.region }}
fi
if aws s3 ls "s3://{{ params.bucket_pyton }}" | grep -q 'sparky.py'
then
aws s3 cp ../python/sparky.py s3://{{ params.bucket_pyton }}/
fi
"""
cmd = BashOperator(task_id='aws_configure',
bash_command=cmd,
params={"secret_access_key" : Variable.get("secret_access_key"), # AWS Access Key ID
"secret_key" : Variable.get("secret_key"), # AWS Secret Access Key
"region" : Variable.get("region"), # Default region name
"output_format" : Variable.get("output_format"), # Default output format
"bucket_log" : Variable.get("bucket_log"), # Bucket S3 for logs
"bucket_pyton" : Variable.get("bucket_pyton") # Bucket s3 for python
},
dag=dag)Xcom
Les Xcom permettent de faire transiter des données entre différentes tâches.
Dans ce DAG les variables Xcom permettent :
- de stocker un message json contenant entre autre l’id du cluster créé dans la tâche
start_emr - de stocker l’id du cluster nettoyé afin de pouvoir ajouter une step sur ce cluster
from airflow import DAG
from airflow.models import Variable
from airflow.operators import BashOperator, PythonOperator
from datetime import datetime as dt
from datetime import timedelta
import time
import json
# Default DAG parameters
default_args = {'owner': 'airflow', 'depends_past': False, 'start_date': dt(2020, 3, 23),
'retries': 0}
dag = DAG('xcom_example', default_args=default_args, schedule_interval='30 07 * * *')
driver_cores = Variable.get("driver_cores")
driver_memory = Variable.get("driver_memory")
executor_memory = Variable.get("executor_memory")
executor_cores = Variable.get("executor_cores")
bucket_pyton = Variable.get("bucket_pyton")
start_emr = """
cluster_id=`aws emr create-cluster \
--release-label emr-5.14.0 \
--instance-groups InstanceGroupType=MASTER,InstanceCount=1,InstanceType=m4.large InstanceGroupType=CORE,InstanceCount=1,InstanceType=m4.large \
--use-default-roles \
--applications Name=Spark
--log-uri s3://aws-emr-airflow \
--auto-terminate`
echo $cluster_id
"""
def parse_emr_id(**kwargs):
ti = kwargs['ti']
json_str = ti.xcom_pull(key="return_value", task_ids="start_emr")
cluster_id = json.loads(json_str)['ClusterId']
ti.xcom_push(key="emr_cluster_id", value=cluster_id)
add_step='bc=' + str(bucket_pyton) + ' dc=' + str(driver_cores) + ' dm=' + \
str(driver_memory) + ' em=' + str(executor_memory) + ' ec=' + str(executor_cores) + '''
cluster_id="{{ ti.xcom_pull(key="emr_cluster_id", task_ids="clean_emr_id") }}"
echo $cluster_id
aws emr add-steps --cluster-id $cluster_id --steps Type=spark,Name=pyspark_job,\
Jar="command-runner.jar",\
Args=[\
--deploy-mode,client,\
s3://$bc/sparky.py\
],ActionOnFailure=TERMINATE_CLUSTER
'''
start_emr = BashOperator(task_id='start_emr',
bash_command=start_emr,
provide_context=True,
xcom_push=True,
dag=dag)
clean_emr_id = PythonOperator(task_id='clean_emr_id',
python_callable=parse_emr_id,
provide_context=True,
dag=dag)
add_step = BashOperator(task_id='add_step',
bash_command=add_step,
provide_context=True,
dag=dag)
add_step.set_upstream(clean_emr_id)
clean_emr_id.set_upstream(start_emr)Les DAGs disposent également d’un grand nombre d’opérateurs. Ils permettent d’utiliser un service tel qu’hive ou autre de manière transparente. En effet dans le fichier airflow.cfg il est possible de configurer un grand nombres d’opérateurs.
Voir plus d’informations sur les Airflow opérateurs sur le site Airflow.
Airflow Cli
Airflow dispose aussi d’un client bash, il est très utile car il permet de modifier les Variables, les Connections, les utilisateurs, ect. Il peut être très utile pour créer des scripts de rattrapage ou automatiser certain process de Airflow.
Conclusion
J’utilise cette technologie dans des environnements de production. Elle présente de nombreux intérêts tout en s’avérant flexible. On peut concevoir Airflow comme un crontab distribué ou, pour ceux qui connaissent, comme une alternative à Oozie avec un langage accessible comme python et une interface agréable.
Tout au long de cet article nous avons utilisé Airflow dans un contexte DevOps mais cela ne représente qu’une infime partie des possibilités offertes.
Attention, en cas d’utilisation intensive, il est plus simple de mettre en place Airflow sur un serveur dédié à vos environnements de production, complété de copies dans des containers Docker afin de pouvoir plus facilement développer et ne pas impacter la production. Les problèmes de Connections ou encore de Variables sont courants !
