


Apache Metron dans le monde réel

29 mai 2018
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Apache Metron est une plateforme d’analyse et de stockage spécialisé dans la sécurité informatique. La conférence a été présentée par Dave Russell, ingénieur en chef des solutions - EMEA + APAC chez Hortonworks au Dataworks Summit 2018 (Berlin). Elle a pour objectif de démontrer les usages et les capacités d’Apache Metron dans le monde réel.
Présentation
Apache Metron est un framework de sécurité informatique permettant aux entreprises d’intégrer, de traiter et de stocker divers flux de données afin de détecter les anomalies et de permettre aux organisations de réagir rapidement.
Il fournit une structure d’analyse de sécurité évolutive se basant sur les technologies Hadoop. Il permet de surveiller le trafic réseau et les journaux machines en consommant des flux continus de données.
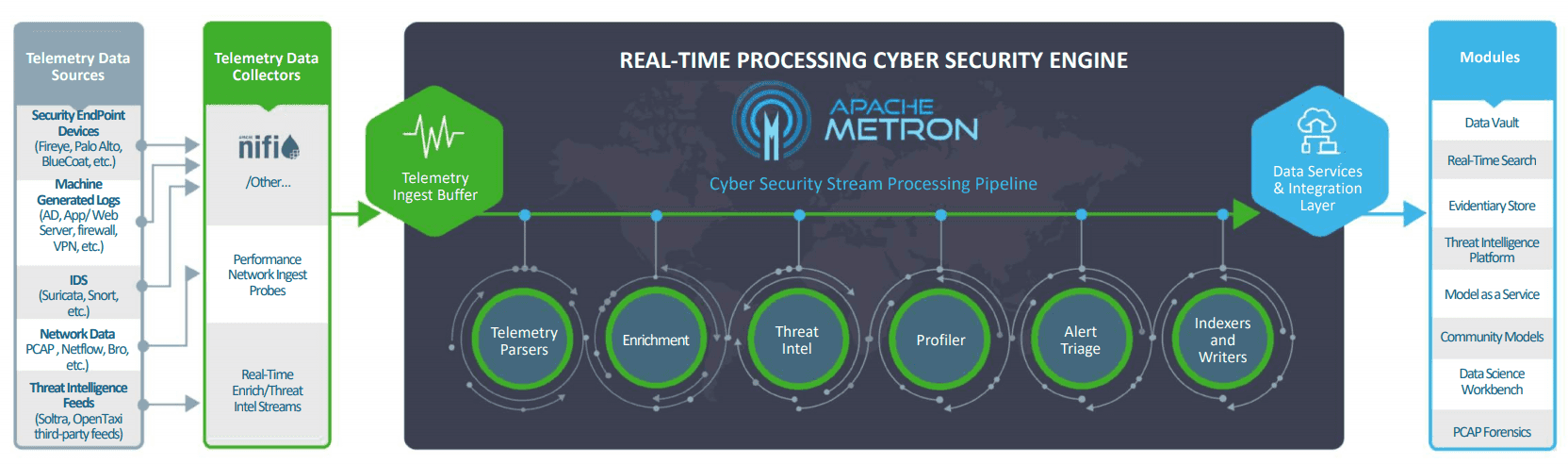
Panorama d’Apache Metron
Metron possède une interface claire et intuitive.
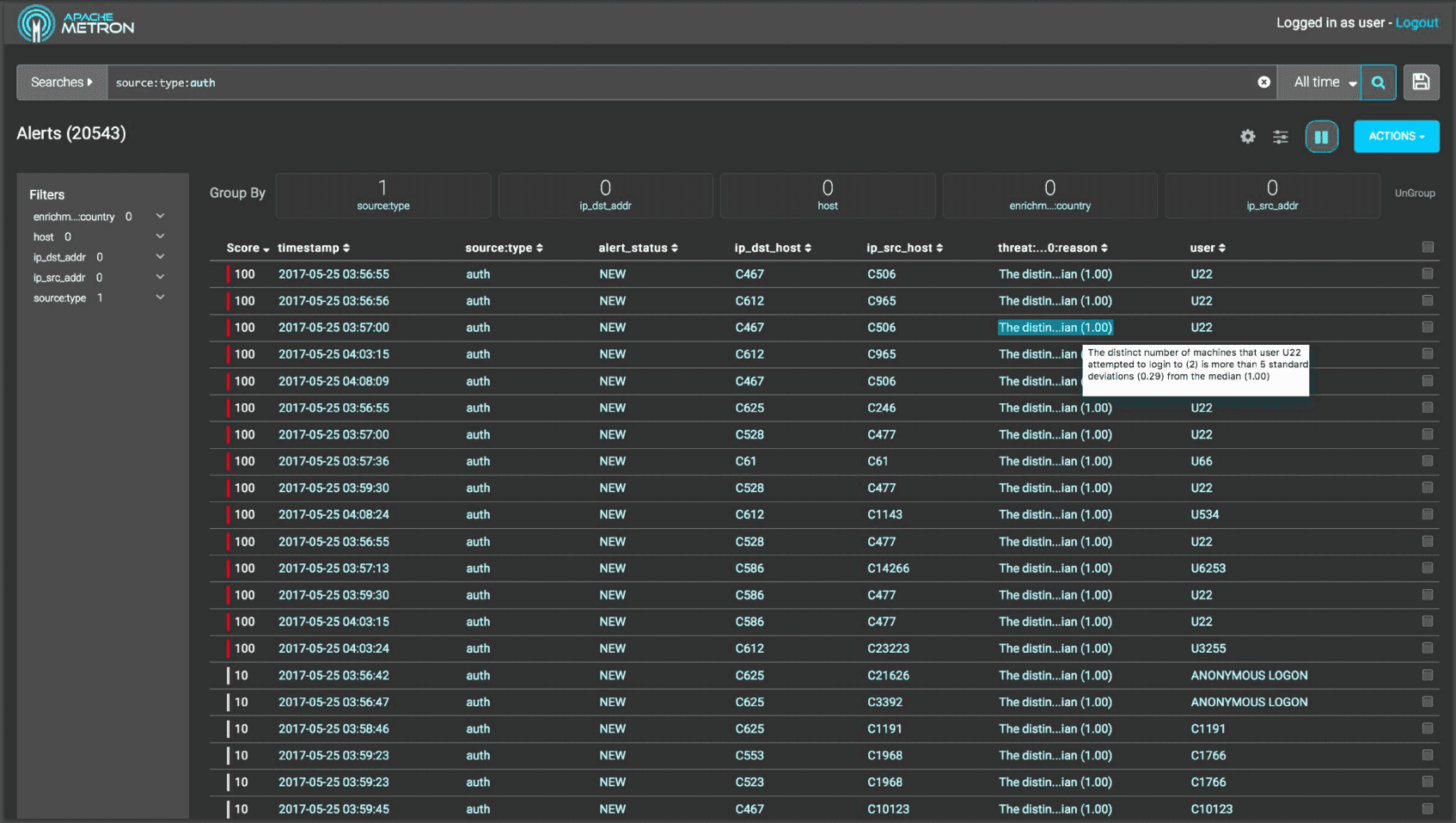
Interface d’Apache Metron
Pour chaque entrée, nous avons des informations techniques générées par la solution, des informations des données sources et celles des différents enrichissements que l’on peut faire via l’interface.
- Un score pour évaluer le niveau de l’alerte
- Un timestamp
- Le status de l’alerte
- La raison de la menace (par exemple “The distinct number of machines that user U22 attempted to login to (2) is more than 5 standard deviations (0.29) from the median (1.00)“)
- L’utilisateur associé
Quelle réponse apporte Metron ?
Actuellement, le temps de rétention des données est très inférieur au temps de détection d’une menace, la durée moyenne de rétention est de 6 mois alors que la durée moyenne de détection d’une menace est de 8 mois. Nous avons donc besoin d’un système qui stocke d’énormes quantités de données sur plusieurs années et c’est là qu’intervient Metron.
”Sometime in the next few years we’re going to have out first category-one cyber-incident ; one that will need a national response”
Ian Levy, Directeur Technique du National Cyber Security Center
Metron embarque de nombreux algorithmes permettant de détecter avec plus de précision les différentes menaces potentielles.
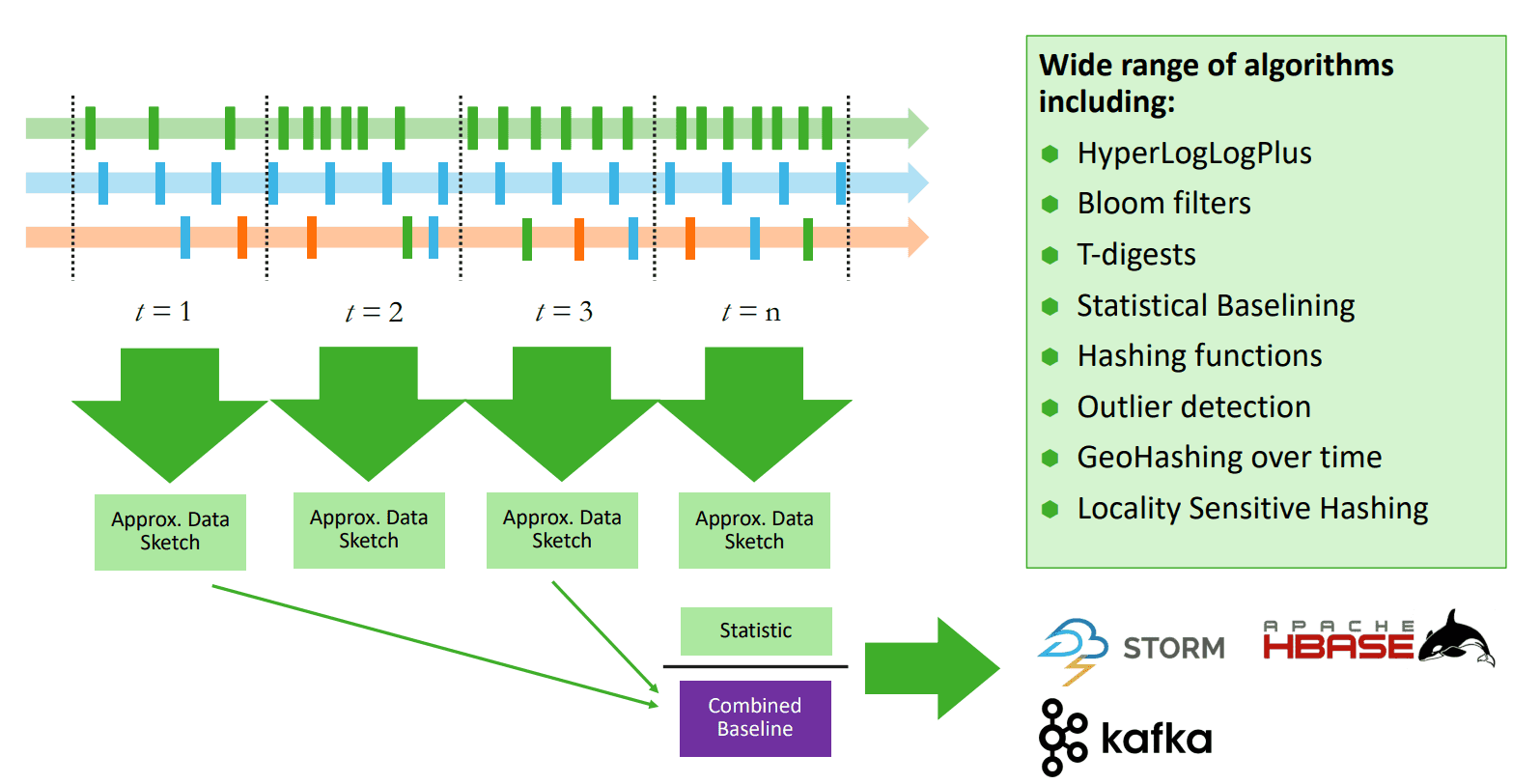
Profilage par le temps
Dimensionnement
Plusieurs points sont à considérer pour le dimensionnement d’un cluster Metron :
- Les événements par secondes (en moyenne et au maximum)
- La durée de rétention pour les zones Chaudes/Tiède/Froide
- L’enrichissement de la donnée
- Les caractéristiques techniques des noeuds
- Les problématiques d’entrée/sortie
- PCAP (interface et outils de supervision réseau afin de capturer les paquets transitant sur le réseau)
La montée en charge du cluster doit être progressive :
- Aujourd’hui à 3 mois : couche de stockage rapide et indexée (Apache Solr ou ElasticSearch)
- 3 mois à 12 mois : couche HDFS tiède
- Après 12 mois : couche HDFS froide
Fiche technique
Metron propose de nombreuses solutions différentes pour chaque problématique :
Ingestion
- Apache Nifi : syslog, socket, file, web services, SQL, RDBMS, Windows Event Log, FTP, MQ, JMS, Splunk et autres
- DPDK capture de paquets haute performance
Analyseurs
- Cisco ASA
- Fireeye
- Palo alto
- Sourcefire
- Websphere
- Snort IDS
- Bro DPI
- Netflow, IPFIX
- Grok (Custom)
- Java (Custom)
- JSON
- CEF, LEEF (ArcSight, Qradar compat.)
- Applications : DHCPD, AD
Enrichissements et flux de menaces
Fonctions d’analyses
- Moteur de profilage et moteur statistique de base
- Services de modélisation pour Machine Learning avancé
- Règles de triage des menaces et moteur de scoring
Indexation et recherche
Fonctionnalités de Data Science
- Spark Machine Learning
- Zeppelin notebooks
- Eco-système des partenaires Wide
Fonctionnalités légales
- Inspecteur PCAP
- Requête PCAP
- Data store de longue durée
Déploiement d’Apache Metron
Comme le dimensionnement, le déploiement de Metron doit être progressif.
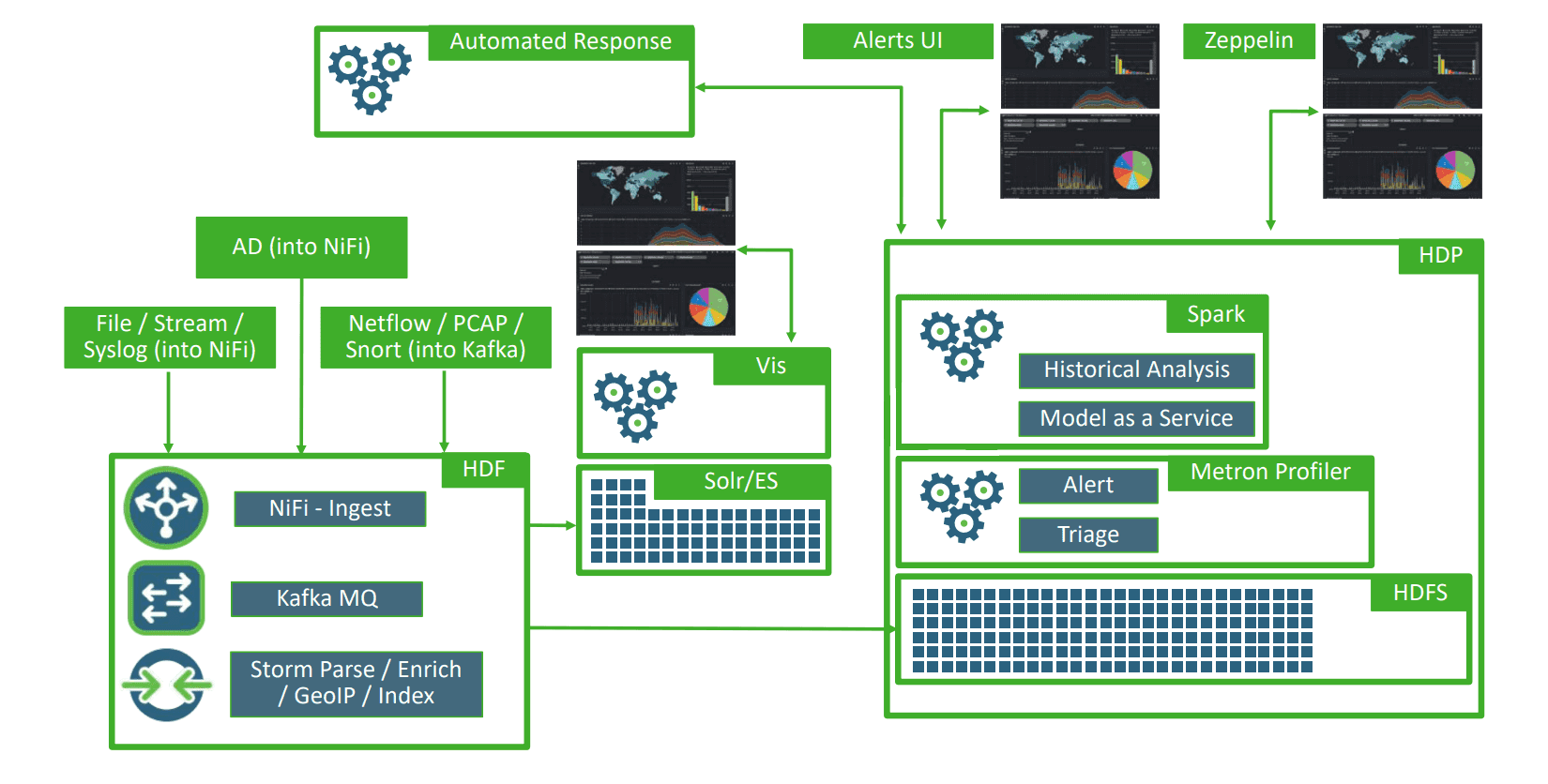
Un éco-système complet basé sur Apache Metron
Par exemple, un déploiement en 3 phases :
- Phase 1 : Installation d’un cluster HDP et HDF. Ingestion des fichiers, flux et log système (via Apache NiFi) et enrichissement de la donnée avec Storm, Parse, GeoIP, etc. Mise en place d’outils de visualisation comme Grafana ou Kibana.
- Phase 2 : Installation d’Apache Metron Profiler (pour le triage et les alertes) et enrichissement de la donnée avec Netflow, PCAP, Snort (via Apache Kafka).
- Phase 3 : Analyse des données historiques via Apache Spark et mise en place des alertes via des interfaces et des réponses automatiques.
Sources
- Datawork Submit 2018 session (Apache Metron in the Real World by Dave Russell) (edit : url inactive)
- Metron Architecture
- Metron Installation
