


Apache Hadoop YARN 3.0 - État de l'art

31 mai 2018
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Cet article couvre la présentation ”Apache Hadoop YARN: state of the union” (YARN état de l’art) par Wangda Tan d’Hortonworks lors de la conférence DataWorks Summit 2018 Berlin (anciennement Hadoop Summit).
Qu’est-ce qu’Apache YARN ?
Pour rappel, YARN est l’un des deux composants majeur d’Apache Hadoop (avec HDFS). Il permet de planifier l’utilisation des ressources d’un cluster ainsi que les traitements appliqués sur les données. Il est par exemple capable d’exécuter les requêtes d’Apache Hive et les jobs MapReduce ou Spark.
YARN gère également l’isolation des ressources afin d’assurer la multi-tenance complète d’un cluster Hadoop pour la RAM et les CPU (pas de gestion des disques ou du réseau cependant).
Historique rapide
Le projet YARN a été initié en Juin-Juillet 2010 à travers le project MapReduce, un framework permettant de traiter en parallèle de gros volumes de données. YARN est passé GA en version 2.2 en Octobre 2013 dans la distribution HDP d’Hortonworks. La dernière version majeure, YARN 3.0, est passée GA en Décembre 2017.
Plongeons nous dans les nouvelles fonctionnalités d’Apache YARN 3.0/3.1.
Scalabilité et fédération
De nombreuses entreprises utilisent déjà YARN sur des clusters contenants plusieurs milliers de noeuds : Yahoo, Twitter, Linkedin et bien d’autres. Cependant la limite physique actuelle est d’environ 20k noeuds pour un seul cluster et 40k pour un cluster fédéré. Dans les version 3+ l’objectif est d’atteindre 100k (et plus) noeuds pour un seul cluster.
Le principal problème lors que le cluster dépasse les milliers de noeuds est que le calcul de disponibilité de ressources est fait par noeud, ainsi quelques millisecondes à l’échelle d’un noeud peuvent facilement devenir plusieurs minutes pour un cluster.
Ce délai est bien trop long d’autant plus qu’il apparait avant la soumission de chaque job, un cluster de production pouvant lancer plus de 10k jobs par jour. Un effort considérable a été effectué pour paralléliser d’avantage et optimiser le processus d’allocation. Désormais YARN est capable d’allouer plus de 3k containers par minute (ce qui revient à une amélioration de performance d’un facteur 10).
La fédération a également été améliorée, YARN divise maintenant un gros cluster en plusieurs sous clusters, chacun ayant son propre Resource Manager et History Server. C’est cette architecture qui permettra de gérer plus de 100k noeuds. Une application pourra tourner sur n’importe quel noeud, peu importe le cluster.
Isolation de ressources
Dans la future version de YARN, l’isolation physique des ressources ne concernera plus uniquement la RAM et les CPU, mais également les GPU et FPGA. Les Data Scientists attendent cette fonctionnalité depuis longtemps, puisqu’elle leur permettra d’intégrer leurs développements plus facilement à un cluster Hadoop.
L’isolation des GPUs se fera à l’échelle de la carte GPU, et YARN utilisera les Cgroups ou Docker pour gérer l’isolation.
Meilleure stratégie de placement
YARN-6592 introduit les notions d’affinités et d’anti-affinités. Ces propriétés permettent d’établir de nouveaux types de règles entre ressources et processus. Voici des exemples de règles :
- Provisionner des containers co-locallisés avec des containers Storm.
- Ne pas démarrer des containers sur les noeuds où un cluster HBase est démarré.
- Ne pas démarrer de RegionServer HBase sur les noeuds exécutant déjà un autre RegionServer.
Packaging
Aupravant seul des jar (JVM) pouvaient être utilisées, YARN supporte maintenant :
- Des containers Docker comme instance de services.
- Des containers natifs (ex : Tupperware)
Support de services
- Mise à jour d’applications et de services (YARN-4726, en cours de résolution) : minimisera le temps d’indisponibilité des services à la mise à jour.
Ce sujet dépend de plusieurs travaux : prendre en charge le redémarrage automatique de containers (YARN-4725), autoriser un container ou un Application Master à conserver ses ressources lors d’un redémarrage (actuellement YARN reprend les ressources à la fin du cycle de vie), et autoriser un Application Master à se redémarrer avec de nouvelles ressources pour afin de se mettre à jour (YARN-1040). - Découvertes simplifiées des services (YARN-4757) : rend le Yarn Service Registry disponible et plus facile d’accès.
Le Registry est un service exposant les services en cours d’exécution sur le cluster leurs configurations. Actuellement (en version 3.0), ce service n’est accessible que par les APIs Rest et Java. Par conséquent, il est difficile de lire la configuration et surtout de la modifier dynamiquement sans réécrire de code. La fonctionnalité implémentée permet d’exposer le Registry par DNS pour faciliter son accès. Ainsiregionserver-0.hbase-app-3.hadoop.yarn.sitepermet d’accéder à la configuration YARN du service HBase regionserver-0.
Définition de service
Cette fonctionnalité (YARN-4793) permet de définir facilement un service tel qu’il sera exécuté et démarré sur le cluster. Pour rappel un service est un programme (job) qui tourne de manière continue et indéfinie dans YARN 3.
Actuellement, la définition d’un nouveau service est compliquée et nécessite l’utilisation d’API bas niveau (YARN native), d’écrire du code (framework avec des APIs programmatiques comme Spark) ou bien de specs complexes (APIs déclaratives). L’API de service a été simplifiée pour faciliter le déploiement, l’instanciation, la montée en charge et le management de service.
Expérience utilisateur
Une très nette amélioration a été apportée dans YARN 3+ au niveau de l’UI comme le montre les aperçus suivant :
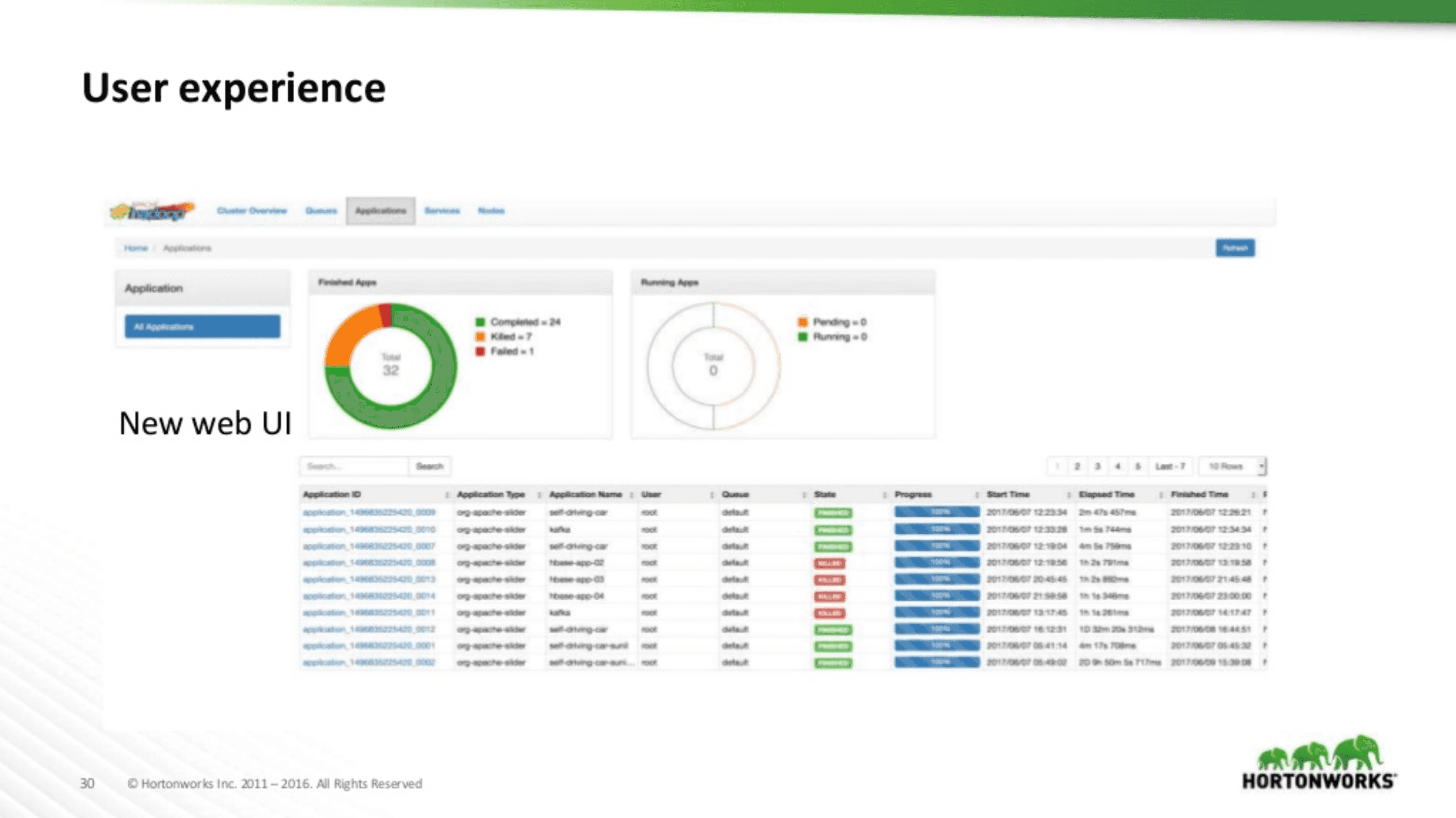
Comme on peut le voir l’UI a été complètement revue sur le modèle d’Ambari.
Service d’historique de donnée
Le YARN Timeline Server est un service qui permet de collecter les données sur l’exécution d’un job dans YARN.
Jusqu’à maintenant ce service était lent, non exhaustif (certains jobs manquaient), non scalable, et ne supportait pas la haute disponibilité (HA).
YARN 3.x introduit une ré-écriture complète de ce service. La principale innovation du TimelineServer 2.0 est que son MetaStore n’est plus une base de données local (LevelDB) mais HBase. Cela permet aux administrateurs d’analyser plus efficacement les données et métriques d’applications, et surtout d’avoir un historique bien plus conséquent sans perdre en latence.
Conclusion
Les nouvelles fonctionnalités offertes par YARN 3.x sont très intéressantes et mettent l’accent sur les demandes exprimées par ses utilisateurs : l’isolation des GPU fait de YARN une alternative viable aux environnements d’exécution actuels des Data Scientists, le service d’historique est bien plus performant, et l’expérience utilisateur est nettement améliorée et facilitant la prise en main pour des profils moins orientés infrastructure comme les développeurs et les Data Scientists.
