


Apache Hadoop YARN 3.0 – State of the union

May 31, 2018
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
This article covers the ”Apache Hadoop YARN: state of the union” talk held by Wangda Tan from Hortonworks during the Dataworks Summit 2018.
What is Apache YARN?
As a reminder, YARN is one of the two central components of Apache Hadoop (with HDFS) and allows data processing by managing and scheduling physical resources of your cluster. For example, it can run Apache Hive queries as Apache Spark or Mapreduce batch jobs.
YARN also takes care of ressources isolation and allows complete multitenancy of an Apache Hadoop cluster regarding RAM and CPU (no disk and network ressources however).
Quick history
The YARN project was initiated around June-July 2010 through the MapReduce project, a framework for parallel processing of large data sets. It went GA in october 2013 on version 2.2 in Horonworks’ HDP distribution. The latest major iteration, YARN 3.0, went GA on 13 December 2017.
Let’s walk through the new features of Apache YARN 3.0/3.1.
Scalability & federation
Many companies already use YARN with thousands of nodes, like Yahoo, Twitter, Linkedin and other, but the limit is currently of about 20k nodes for a single cluster, and 40k for a federated cluster. In 3+ version, the goal is to manage 100k nodes per cluster and beyond.
The main issue in running large cluster is that resource scheduling evaluation is made per node, and the few milliseconds spent per node can easily become minutes.
It is unacceptable for a company to wait a few minutes before each job execution, which is why an effort has been made to parallelize and optimize this procees. YARN is now able to allocate 3k+ containers per minutes, meaning a 10 times higher troughput.
Federation capacities were also improved as YARN will now divide a single huge clusters into multiple “subclusters”, each subcluster having it’s own ResourceManager and HistoryServer. With this architecture it is able to handle more than 100k nodes and an application will be able to run on any node of any cluster.
Autocreation of Leaf Queues - YARN 7117
It will allow to easily map a queue explicity to user or group without additional configs.
Better usability of queues - YARN-5734
Now there is a dedicated API dedicated to queue management, the capacity-scheduler.xml file is not ore the centralized place for queue management.
Resources isolation
As already stated, YARN allows resources scheduling/isolation only for Memory and CPU. The new version introduces GPU and FPGA resources support. Data Scientist have been waiting this feature for a long time to run some of their work on Hadoop clusters.
GPU isolation will have a granularity of per-GPU device, and YARN will use Cgroups/Docker to enforce isolation.
Better placement strategy
YARN-6592 is about affinities and anti-affinities, adding new rules on process and containers co-location. Here are some rule examples:
- Try to run containers co-located with Storm processs.
- Try to run containers where there are containers running HBase RegionServers.
- Do not run HBase RegionServer containers on a host already running another RegionServer container.
Packaging
Previously, only Jar-based jobs could be executed. YARN now supports:
- Docker containers can be used as instances or applications.
- Native container runtimes (such as Tupperware).
Now you choose at run time, you can run wih our without docker on the same cluster!
Moreover docker on YARN, helps to solve Spark package isolation issues with PySpark - and R (versions, packages).
Running YARN on YARN
each system-test cluster is an app on YARN!
Each system-test cluster is a group of containers
YARN inception allows to test HADOOP on a HADOOP Cluster :) .
Services support
- Application & Services upgrades (YARN-4726, work in progress): will allow to upgrade an application with minimal impact and downtime.
It depends on other works from the community: take care of auto-restart of containers (YARN-4725), allow an Application Master and/or a simple container to keep it’s resource allocation on restart (currently YARN reclaims the resources on end of lifecycle), and allow an Application Master to restart itself with new resources (self-upgrade) (YARN-1040). - Simplified discovery of services (YARN-4757): makes the Yarn Service Registry available and easy to use.
The Registry is a service exposing the services running on a cluster annd their configurations. For now (3.0), the registry is accessible through Java and REST APIs. As a consequence, it is hard to read and dynamicly update a configuration without rewriting code. The feature exposes the registry with a DNS to ease resource access, for example: regionserver-0.hbase-app-3.hadoop.yarn.site points to the yarn-siteconfiguration of your HBase app running on the regionserver-0service.
Service Definition
YARN-4793 is about making the service definition easier (a service is a long-time running process inside a YARN 3 container).
Currently, setting up a new service is complicated and requires you to use low level APIs (native YARN), to write new code (framework with programmatic APIs like Spark), or to write complex specs (declarative APIs). The API is simplified to ease deployment, spawning, scaling and management.
User Experience
A big improvement of YARN 3+ is its UX and UI. As a picture is worth a thousand words, let’s compare screenshots:
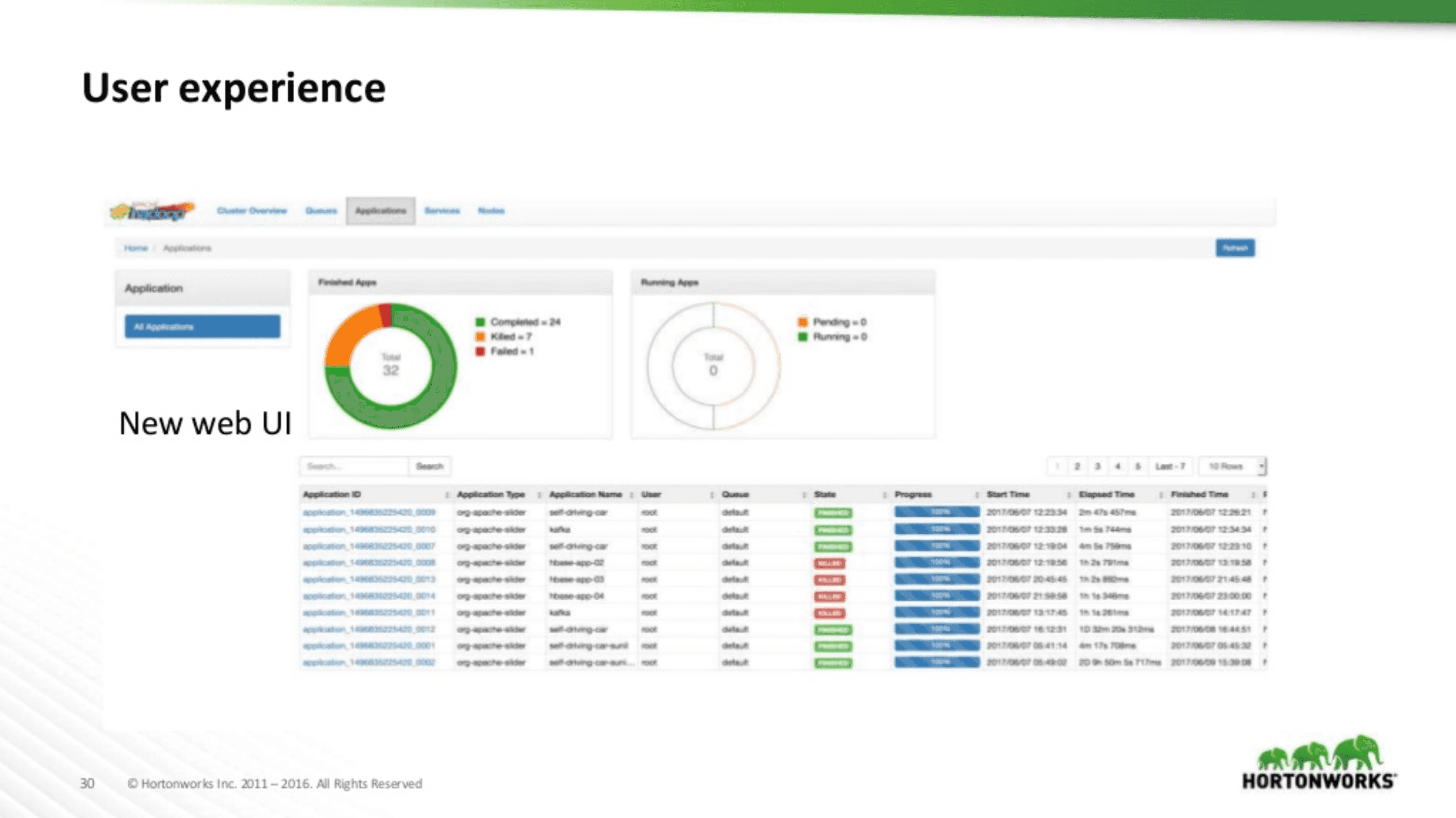
As you can see, the UI has been completely remodeled on the same model as Ambari’s current UI.
TimeLine service
The YARN Timeline Server is a service collecting data on a job’s execution in YARN.
Up until now Timeline service was slow, not exhaustive, not scalable and had no High Availability.
YARN 3.x focused efforts on Yarn Timeline Service 2.0. The backend used to be based on a local database (LevelDB) and is now using HBase. It will allow adminsitrators to analyze more efficiently their application’s metadata and understand the bottlenecks while being scalable without latency issues.
Conclusion
YARN 3.x is very exciting as the developers focused on improving what makes it so popular: GPU isolation positions YARN as a viable alternative to current execution environments for Data Scientists, the Timeline server is way more efficient, and the UI makes YARN more friendly to non-developers and Data Scientists.
