


Spark Streaming partie 1 : construction de data pipelines avec Spark Structured Streaming

18 avr. 2019
- Catégories
- Data Engineering
- Formation
- Tags
- Apache Spark Streaming
- Kafka
- Spark
- Big Data
- Streaming [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Spark Structured Streaming est un nouveau moteur de traitement stream introduit avec Apache Spark 2. Il est construit sur le moteur Spark SQL et utilise le modèle Spark DataFrame. Le moteur Structured Streaming partage la même API que le moteur Spark SQL. L’utilisateur ne devrait donc pas rencontrer de difficulté quant à son utilisation. L’une des caractéristiques principales est que les données de streaming sont modélisées comme des tableaux infinies. De ce fait, l’API permet l’exécution de requêtes SQL sur un stream abstrait comme un tableau. Un cas d’usage sera présenté, permettant de passer en revue certains concepts de Spark Structured Streaming. Nous utiliserons Kafka pour le transit de nos données. Découvrez, à travers cet article, l’un des moteurs de streaming les plus conviviaux pour les développeurs.
Dans la documentation on retrouve une phrase résumant l’existence de Spark Structured Streaming :
Spark Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing without the user having to reason about streaming.
Cet article est le premier article d’une série en quatre parties :
- Dans la première partie, un pipeline de données est créé en Python avec Spark Structured Streaming.
- La deuxième partie concerne la migration du pipeline vers un cluster Hadoop.
- Dans la troisième partie, l’application PySpark a été portée et testée dans un environnement Scala Spark et des test unitaires ont été ajoutés.
- La quatrième et dernière partie enrichie le pipeline de données avec un algorithme du regroupement par apprentissage automatique.
Nous aborderons dans un premier temps l’aspect streaming et nous présenterons un cas d’usage. Nos données seront ingestées avec Kafka puis traitées en temps quasi réel dans Spark Structured Streaming. Le deuxième article présentera le même cas d’usage cette fois dans un cluster Hadoop. Les difficultés associées y seront abordées, en terme de production.
Un jeu de données de taxi new-yorkais légèrement modifiées pour les tutos d’Apache Flink (edit : lien originel inactif, voir ici) seront utilisées. Ce dataset contient une collection de courses référencées par conducteur ainsi que des informations telles que la somme payée, la date ou encore une variable indicatrice nous informant si la course commence ou se termine, etc. Ces données sont disponibles dans les deux fichiers compréssés de ce site : nycTaxiRides.gz fournit les informations géographiques, nycTaxiFares.gz les informations pécuniaires. Ses deux fichiers ne sont pas gourmand en terme de mémoire (la taille en dessous de 100MB). Autrement, la base de données originale dépasse les 500GB et correspondra, de ce fait, à un environnement type cluster.
La problématique de ce cas d’usage sera d’identifier les zones géographiques de Manhattan (les quartiers) où les chauffeurs seraient le plus à même de recevoir un pourboire élevé. Un conducteur ayant cette information pourrait ainsi choisir stratégiquement son secteur d’activité. A noter que les données concernant les pourboires sont disponibles seulement lorsque le client règle en carte bancaire. L’analyse en sera impactée, mais ne perd pas totalement son sens. Cette problématique s’applique à l’environnement streaming. En effet, l’obtention rapide d’un résultat permettra aux conducteurs de s’orienter vers les dites zones le plus tôt possible.
Déploiement de Kafka et de Spark
Le code ci-dessus crée un nouveau dossier où seront installés Kafka et Spark :
mkdir spark-sstreaming-part1 && cd $_
#Spark 2.4.0 installation
curl http://mirrors.standaloneinstaller.com/apache/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz -o spark-2.4.0-bin-hadoop2.7.tgz
tar xzf spark-2.4.0-bin-hadoop2.7.tgz
ln -sf spark-2.4.0-bin-hadoop2.7 spark
#Kafka 2.2.0 installation
curl https://www-us.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz -o kafka_2.12-2.2.0.tgz
tar xzf kafka_2.12-2.2.0.tgz
ln -sf kafka_2.12-2.2.0 kafkaLes résultats seront redirigés vers la console. Le résultat du programme Spark Driver est riche en log de type INFO, ce qui peut obscurcir les résultats. Une stratégie possible est de changer le niveau de logs Spark vers WARN, en modifiant le fichier “spark/conf/log4j.properties”. Si des problèmes apparaissent, il vaut mieux revenir au niveau de logs INFO.
#Set Spark's console output log level to WARN
cp spark/conf/log4j.properties.template spark/conf/log4j.properties
sed -i -e 's/log4j.rootCategory=INFO/log4j.rootCategory=WARN/g' spark/conf/log4j.propertiesLe code suivant permet le lancement des serveurs ZooKeeper et Kafka ainsi que la création de nos topics :
kafka/bin/zookeeper-server-start.sh -daemon kafka/config/zookeeper.properties
kafka/bin/kafka-server-start.sh -daemon kafka/config/server.properties
kafka/bin/kafka-topics.sh \
--create --zookeeper localhost:2181 --replication-factor 1 \
--partitions 1 --topic taxirides
kafka/bin/kafka-topics.sh \
--create --zookeeper localhost:2181 --replication-factor 1 \
--partitions 1 --topic taxifaresIngestion des données dans Kafka
Dans une application réelle, garder à l’esprit que les données ne sont pas bornées. Pour avoir la flexibilité, le jeu de données est borné. Néanmoins, nous simulerons un flux de données puisque les données sont émises en tant qu’événements en cours dans Kafka. Aucune modification n’est nécessaire entre cette variante et ce qui se passerait réellement. Le code ci-dessous, grâce à des pipes Unix, importe les données dans les topics concernés :
( curl -s https://training.ververica.com/trainingData/nycTaxiRides.gz \
| zcat \
| split -l 10000 --filter="kafka/bin/kafka-console-producer.sh \
--broker-list localhost:9092 --topic taxirides; sleep 0.2"\
> /dev/null ) &
( curl -s https://training.ververica.com/trainingData/nycTaxiFares.gz \
| zcat \
| split -l 10000 --filter="kafka/bin/kafka-console-producer.sh \
--broker-list localhost:9092 --topic taxifares; sleep 0.2" \
> /dev/null ) &En détaillant ce code, il en ressort que :
- Un stream est crée depuis le fichier compressé, aucun fichier n’est stocké à l’ordinateur
- La commande
zcatpermet de lire le contenu d’un fichier compressé - La commande
splitpermet d’envoyer des données vers--filteren les regroupant en blocs de 10000 messages - Les événements sont publiés vers le topic Kafka avec le script kafka-console-producer.sh
- La commande
sleepproduit un délai de 100 milliseconds entre chaque “batch” de messages, on cherche ici à reproduire la nature séquentiel d’un stream - Sachant que le producer Kafka produit le caractère
>pour chaque évènement, on redirige ces caractères vers/dev/null - Le caractère
&permet de faire tourner cette commande en tâche de fond. Il libère le terminal pour lancer immédiatement un autre stream
Deux streams de données sont simulés dans cette exemple. Une situation réelle en impliquerait bien plus, émanant de plusieurs centaines de machines (cas d’un réseau IoT, par exemple). Les producers Kafka seraient également complexifiés.
Les consumers Kafka peuvent être utilisés pour vérifier la bonne ingestion de nos données dans les topics. Utiliser les commandes suivantes afin de voir apparaître vos résultats dans la console :
kafka/bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic taxirides --from-beginning
kafka/bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic taxifares –from-beginningLes données transitent désormais dans le bus de message qu’est Kafka, concentrons maintenant notre attention sur l’application Spark.
Intégration de Spark Structured Streaming avec Kafka
Spark Structured Streaming est la nouvelle approche streaming de Spark, disponible depuis Spark 2.0 et stable depuis Spark 2.2. Il est construit sur le moteur Spark SQL et partagent la même API. Le même code utilisé pour les traitements batch peut s’appliquer à du streaming, seules les méthodes d’entrées et de sorties devraient être modifiées. L’approche micro-batch processing sera utilisé dans cet exemple. Elle garantit une latence autour de 100 ms et un traitement unique des évènements. Avec Spark 2.3 est apparu le modèle continuous processing dôté d’une latence de 1ms, les évènements peuvent néanmoins être dupliqués.
La première étape consiste en la création d’une Session Spark. Nous récupérerons ensuite nos données de streamings depuis les topics Kafka, et les mettrons sous forme de DataFrame. Nous utiliserons Python dans cette partie, pourtant il est possible d’utiliser Java et Scala comme langage de programmation en Spark.
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("Spark Structured Streaming from Kafka") \
.getOrCreate()
sdfRides = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "taxirides") \
.option("startingOffsets", "latest") \
.load() \
.selectExpr("CAST(value AS STRING)")
sdfFares = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "taxifares") \
.option("startingOffsets", "latest") \
.load() \
.selectExpr("CAST(value AS STRING)")L’option startingOffsets est reglé sur latest, nous obligeant à relancer le flux de données dans Kafka lorsque l’application Spark attend des données. Nous sélectionnons seulement la colonne “value”, contenant nos données de Taxi sous forme de la chaîne de caractères. Les autres colonnes contiennent des métadonnées qui pourraient être utiles dans un environnement de production. Avant d’extraire les données, préparons le schéma afin de leurs donner du sens. Préparons les schémas de nos DataFrames en définissant les noms de nos attributs. Nous pourrons ensuite injecter les données dans les nouvelles colonnes.
from pyspark.sql.types import *
taxiFaresSchema = StructType([ \
StructField("rideId", LongType()), StructField("taxiId", LongType()), \
StructField("driverId", LongType()), StructField("startTime", TimestampType()), \
StructField("paymentType", StringType()), StructField("tip", FloatType()), \
StructField("tolls", FloatType()), StructField("totalFare", FloatType())])
taxiRidesSchema = StructType([ \
StructField("rideId", LongType()), StructField("isStart", StringType()), \
StructField("endTime", TimestampType()), StructField("startTime", TimestampType()), \
StructField("startLon", FloatType()), StructField("startLat", FloatType()), \
StructField("endLon", FloatType()), StructField("endLat", FloatType()), \
StructField("passengerCnt", ShortType()), StructField("taxiId", LongType()), \
StructField("driverId", LongType())])
def parse_data_from_kafka_message(sdf, schema):
from pyspark.sql.functions import split
assert sdf.isStreaming == True, "DataFrame doesn't receive streaming data"
col = split(sdf['value'], ',') #split attributes to nested array in one Column
#now expand col to multiple top-level columns
for idx, field in enumerate(schema):
sdf = sdf.withColumn(field.name, col.getItem(idx).cast(field.dataType))
return sdf.select([field.name for field in schema])
sdfRides = parse_data_from_kafka_message(sdfRides, taxiRidesSchema)
sdfFares = parse_data_from_kafka_message(sdfFares, taxiFaresSchema)Les DataFrames sdfRides et sdfFares sont prêt à être traités.
Requêtes streaming dans Spark
Il est bon de vérifier la disponibilité de nos données en lançant une requête simple retournant le nombre de courses effectuées par conducteur :
query = sdfRides.groupBy("driverId").count()
query.writeStream \
.outputMode("complete") \
.format("console") \
.option("truncate", False) \
.start() \
.awaitTermination()L’interface DataFrame.writeStream contrôle le comportement d’envoi de nos données streaming.
- Trois modes d’output sont à notre disposition, déterminant quels résultats (quelles lignes du “Result Table”) seront envoyés au collecteur de données externe :
outputMode("complete")utlisé au-dessus, s’applique dans le cas des requêtes agrégées. Toutes les lignes sont utilisées lors du traitement de la requêteoutputMode("update")sera utile dans le cas où vous voulez seulement considérer les nouvelles lignes et les lignes modifiés depuis le dernier triggeroutputMode("append")où seuls les nouvelles lignes seront prise en compte, précisément une fois. Les résultats précédents sont déjà affichés et, par conséquent, ne sont pas modifiables. En effet, il est impossible de modifier le contenu d’un fichier existant en ajoutant une nouvelle ligne de caractère. Seules les requêtes donnant un résultat unique (i.e select, filter) sont supportées. Les requêtes aggrégés (i.e count) ne fonctionneront pas dans ce mode, à part si vous utilisez le watermarking et le Windowing
- Le
format("console")est modifiable selon l’utilisation. Un autre topic Kafka, un fichier sink auraient pu être spécifiés comme un collecteur de données externe - Une requête Spark Structured Streaming peut être déclenchée à l’aide de triggers spécifiant l’interval de temps entre chaque exécution de micro-batch. L’option
.trigger()n’a pas été spécifiée, Spark procédera les nouvelles données une fois que le micro-batch précédent arrivera à terme
L’application test est prête à être soumis. Spark fonctionne en mode local sur un unique hôte. Nous aborderons dans l’article suivant comment l’utiliser avec le mode yarn sur un cluster Hadoop. Le package spark-sqk-kafka est obligatoire pour l’intégration de Kafka avec Spark. Les paramètres –num-executors , --driver-memory , --executor-memory sont réglés pour la machine avec 16GB de RAM.
spark/bin/spark-submit \
--master local --driver-memory 4g \
--num-executors 2 --executor-memory 4g \
--packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.0 \
sstreaming-spark-out.pyUne fois l’application Spark active et renvoyant un résultat vide ‘Batch : 0’ avec les noms des colonnes, il est temps de relancer le stream des données avec la commande Kafka expliqué précédemment :
( curl -s https://training.ververica.com/trainingData/nycTaxiRides.gz \
| zcat \
| split -l 10000 --filter="kafka/bin/kafka-console-producer.sh \
--broker-list localhost:9092 --topic taxirides; sleep 0.2" \
> /dev/null ) &Le code de cette section est disponible ici, voici un exemple de résultat :
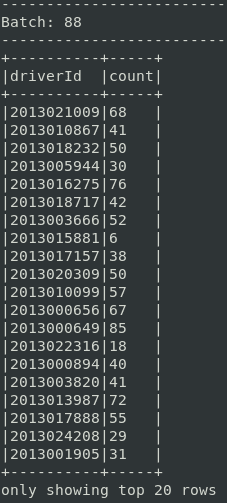
Nettoyage des données
C’est une tâche parfois fastidieuse mais essentielle au bon déroulement des requêtes. Nous portons notre étude sur la zone de Manhattan, il semble donc logique d’évincer les courses ne commençant pas ou ne finissant pas dans le périmètre de New York. Les évènements “START” sont également mis de côté car nous voulons les courses ayant débouchés sur un paiement, et possiblement un pourboire. Afin d’éviter toute confusion, l’ordre des colonnes “endTime” et “startTime” de sdfRides est inversé respectivement pour “START” et “END”. Aussi, sachant que seuls les évènements “END” sont gardés, un seul ordre est préservé.
LON_EAST, LON_WEST, LAT_NORTH, LAT_SOUTH = -73.7, -74.05, 41.0, 40.5
sdfRides = sdfRides.filter( \
sdfRides["startLon"].between(LON_WEST, LON_EAST) & \
sdfRides["startLat"].between(LAT_SOUTH, LAT_NORTH) & \
sdfRides["endLon"].between(LON_WEST, LON_EAST) & \
sdfRides["endLat"].between(LAT_SOUTH, LAT_NORTH))
# Notice that rides with faulty geospatial data as e.g. (0, 0) are filtered out also
sdfRides = sdfRides.filter(sdfRides["isStart"] == "END") #Keep only finished!Le nettoyage des données pourrait être complexifié. Si on prend en compte la nature temporelle des données, les trajets avec un temps de course négatif pourraient être écartées de l’analyse. Une stratégie concernant les données financières de sdfFares est également imaginable.
Jointure stream-stream grâce au Watermarking
Spark 2.3 introduit la joinutre stream-stream. Le but est de joindre les deux DataFrames sdfRides et sdfFares qui sont en train de recevoir leur stream. En combinant données spatio-temporelles et financières, le spectre d’analyse en serait grandi. Ce type de jointure n’est réalisable que dans le mode output("append"). Ces jointures peuvent bénéficier du concept de Watermarking, ce concept devrait être considéré comme essentiel pour réaliser optimalement des jointures.
Le watermark définit le délai qu’un timestamp peut prendre par rapport au temps maximal de l’événement observé jusqu’à présent. Prenons un exemple, le dernier événement a eu lieu à 14h05 et le watermark est défini sur 1 heure. Un nouvel événement apparaissant à 13h00 serait supprimé tandis que celui de 13h10 serait marqué comme valide et conservé en mémoire. Ce mécanisme limite la taille du buffer pour les jointures et garantit que les données ne se développent pas infiniment. Un événement n’est pas gardé éternellement pour un jointure ou un aggrégat. La suppression des données obsolètes résout également les problèmes de données hors cadre (out-of-order data).
Le but de cette jointure est de rassembler deux évènements concernés par un même sujet, la fin de la course, et non de lier les évènements selon le début et la fin de la course. Une stratégie consisterait à mettre un watermark sur la variable “endTime” des deux DataFrames et de définir une contrainte sur la différence de temps sur la variable de fin de course. Malheureusement, sdfFares n’a pas la variable “endTime”, seulement “startTime”. Une solution serait donc de baser la jointure en fixant deux watermark : sur “startTime” pour sdfFares et sur “endTime” pour sdfRides. Une contrainte de temps relative au début et à la fin de la course doit être envisagé pour la jointure.
# Apply watermarks on event-time columns
sdfFaresWithWatermark = sdfFares \
.selectExpr("rideId AS rideId_fares", "startTime", "totalFare", "tip") \
.withWatermark("startTime", "30 minutes") # maximal delay
sdfRidesWithWatermark = sdfRides \
.selectExpr("rideId", "endTime", "driverId", "taxiId", \
"startLon", "startLat", "endLon", "endLat") \
.withWatermark("endTime", "30 minutes") # maximal delay
# Join with event-time constraints
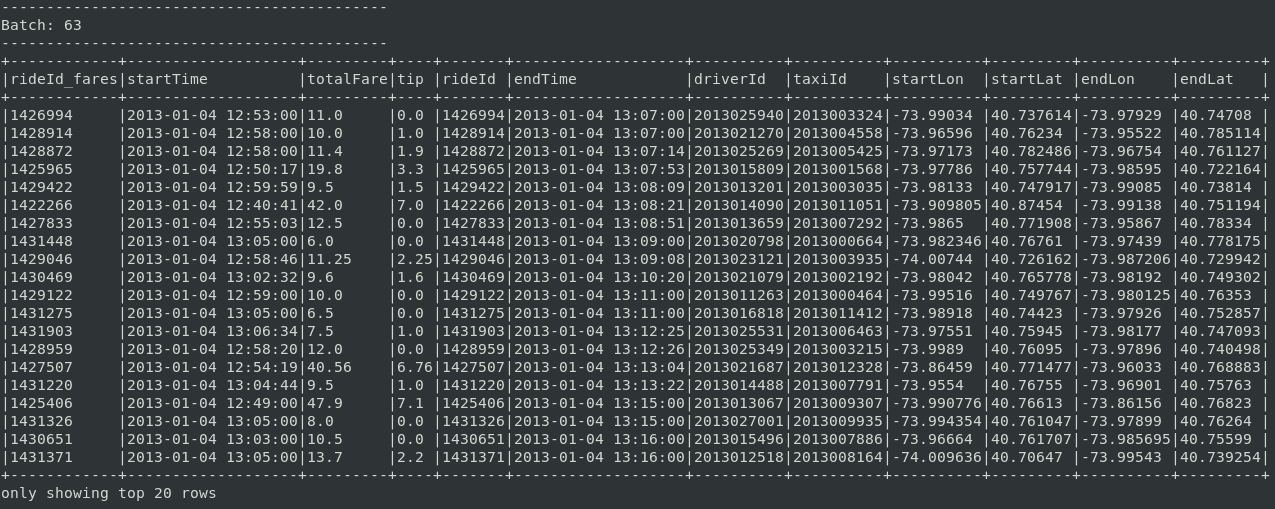
sdf = sdfFaresWithWatermark \
.join(sdfRidesWithWatermark, \
expr("""
rideId_fares = rideId AND
endTime > startTime AND
endTime <= startTime + interval 2 hours
"""))Nous avons fixé ci-dessus que les évènements des DataFrames ne pouvait pas dépasser 30 minutes. Un évènement sdfFares est gardé 30 minutes afin de matcher son homologue dans sdfRides, et vice versa. La contrainte utilisé pour la jointure écarte également les courses supérieures à 2 heures.
Un exemple de micro-batch à ce stade :
Feature engineering relatif à la géographie
Avant d’ajouter les aggrégations aux streamings, transformons les coordonnées géographiques afin de les représenter en terme de quartier. Cette section illustre l’association de données collectées en treaming avec les données batch distribuées sur l’ensemble des executeurs Spark. Pour ce faire, elle utilise le méchanisme de broadcasting présent dans Spark.
Afin de comparer les trajets similaires, les coordonnées géographiques de ces derniers nous sont utiles. On assigne aux couples latitude-longitude un nom de quartier. Ce faisant, des partitions de course sont créées, utile pour le regroupement. Une course est identifiée à un groupe si et seulement si celle-ci se déroule à l’intérieur du dit quartier. Cela revient à vérifier si un point “(Lon, Lat)” se trouve dans un polygone défini comme un ensemble de points ”[(Lon_A, Lat_A), (Lon_B, Lat_B), …]“.
Le travail de l’équipe Zillow, définissant les limites entres les quartiers des plus grandes villes américaines, est repris dans cette analyse. La librairie PyShp Python sera utilisée. Le fichier nbhd.jsonl crée ci-dessous comprend tous les quartiers New-Yorkais, ligne par ligne. Seules les données concernant Manhattan seront prises en compte dans notre analyse.
pip install pyshp # if needed
wget https://www.zillowstatic.com/static-neighborhood-boundaries/LATEST/static-neighborhood-boundaries/shp/ZillowNeighborhoods-NY.zip
unzip ZillowNeighborhoods-NY.zip
cat > prep.py <<- EOF
import shapefile
import json
with open('nbhd.jsonl', 'w') as outfile:
sf = shapefile.Reader("ZillowNeighborhoods-NY")
shapeRecs = sf.shapeRecords()
for n in shapeRecs:
State, County, City, Name, RegionID = n.record[:]
if City != 'New York' : continue
if County != 'New York' : continue # New York County corresponds to Manhattan borough
json.dump({"name":Name, "coord":n.shape.points}, outfile)
outfile.write('\n')
EOF
python3 prep.pyL’algorithme even-odd, dont l’implémentation est disponible sur Wikipédia, permettra de classifier les couples de positions géographiques en fonction de leurs polygons :
def isPointInPath(x, y, poly):
"""check if point x, y is in poly
poly -- a list of tuples [(x, y), (x, y), ...]"""
num = len(poly)
i = 0
j = num - 1
c = False
for i in range(num):
if ((poly[i][1] > y) != (poly[j][1] > y)) and \
(x < poly[i][0] + (poly[j][0] - poly[i][0]) * (y - poly[i][1]) /
(poly[j][1] - poly[i][1])):
c = not c
j = i
return cSpark est capable d’utiliser les fichiers multi-ligne JSON comme source de donnée. Les polygones sont injectés dans le DataFrame à l’aide de la commande spark.read.json(). Chaque fois qu’un worker traite un micro-batch, une copie séparée du DataFrame est envoyée. Sachant que ce DataFrame est un tableau de correspondances qui ne change pas et que les tâches concernées par plusieurs étapes nécessitent ce tableau, un envoi récurent n’est pas viable. La fonctionnalité de broadcast de Spark est plus appropriée. Une variable statique de correspondances contenant les polygones des quartiers pourrait être conservée, en mode lecture seule, dans le cache de tous les noeuds. Telle variable explicite pourrait être définie avec la méthode SparkContext.broadcast(), nécessitant un dictionnaire respectant un format clé-valeur :
nbhds_df = spark.read.json("nbhd.jsonl") # easy loading data
lookupdict = nbhds_df.select("name","coord").rdd.collectAsMap() # cast the DataFrame
broadcastVar = spark.sparkContext.broadcast(lookupdict) # use broadcastVar.value from now onL’envoi de la variable broadcast des quartiers permet d’accéder au tableau de correspondances à partir de n’importe quelle fonction définie par l’utilisateur (UDF). Un quartier peut être assigné à chaque course et stocké dans une colonne avec l’UDF défini ci-dessous :
#Approx manhattan bbox
manhattan_bbox = [[-74.0489866963,40.681530375],[-73.8265135518,40.681530375], \
[-73.8265135518,40.9548628598],[-74.0489866963,40.9548628598],[-74.0489866963,40.681530375]]
from pyspark.sql.functions import udf
def find_nbhd(lon, lat):
'''takes geo point as lon, lat floats and returns name of neighborhood it belongs to
needs broadcastVar available'''
if not isPointInPath(lon, lat, manhattan_bbox) : return "Other"
for name, coord in broadcastVar.value.items():
if isPointInPath(lon, lat, coord):
return str(name) #cast unicode->str
return "Other" #geo-point not in neighborhoods
find_nbhd_udf = udf(find_nbhd, StringType())
sdf = sdf.withColumn("stopNbhd", find_nbhd_udf("endLon", "endLat"))
sdf = sdf.withColumn("startNbhd", find_nbhd_udf("startLon", "startLat"))Les résultats dans la console devront prendre la forme suivante :
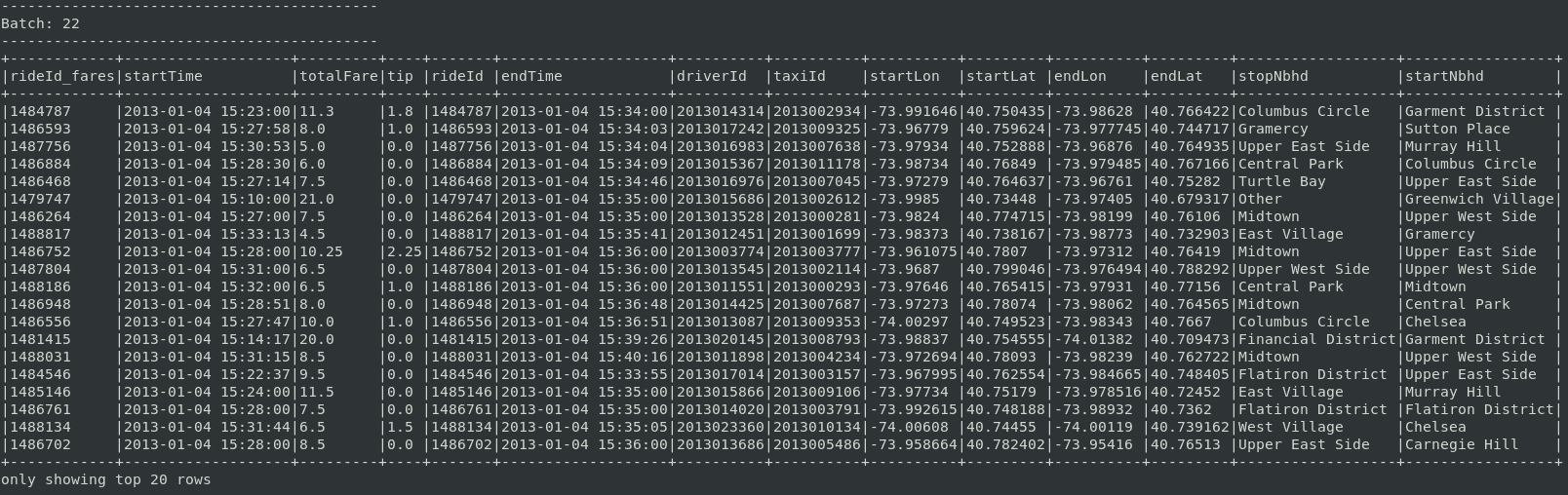
Les données des coursiers sont dorénavant prêtes à être questionnées sur des thèmes géographiques et financiers. Rappelons que notre problématique est la suivante :
Quelles sont les quartiers de Manhattan où les pourboires sont les plus élevés ?
Prise en compte de l’aggrégation
L’opération finale consiste à calculer le pourboire moyen au regard du quartier et d’un espace-temps défini : le fenêtrage est de 30 minutes avec un rafraîchissement toutes les 10 minutes. Dans une situation réelle, il serait préférable de traiter ce calcul en utilisant une fenêtre de 2 heures, avec des triggers toutes les minutes. Cette démarche nécessiterait des ressources plus conséquentes.
tips = sdf \
.groupBy(
window("endTime", "30 minutes", "10 minutes"),
"stopNbhd") \
.agg(avg("tip"))Le code complet est disponible dans ce fichier. Les résultats prennent la forme suivante :
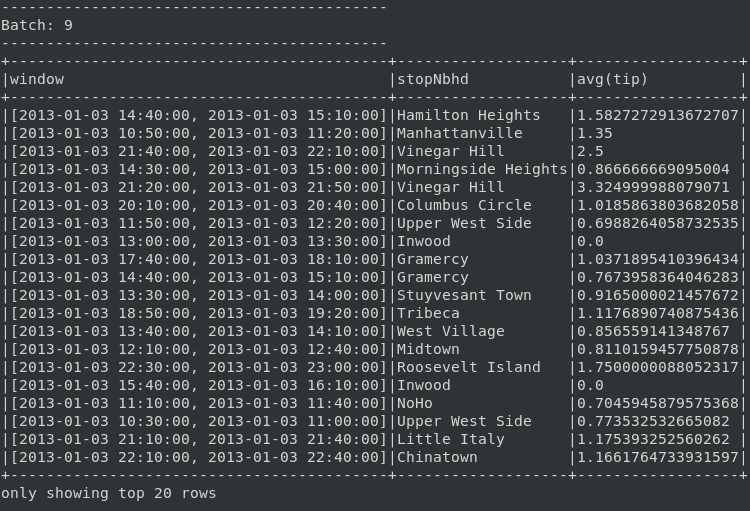
Un chauffeur libre à 21h50 peut espérer maximiser ses gains s’il se rend à Vinegar Hill pour effectuer sa prochaine course (la conclusion basé sur les 20 premières lignes)
Quelques batch vides sont acceptables en début de traitement de requête, c’est l’une des caractéristiques du mode “append”, défini plus haut. En effet, les résultats sortent une fois que l’outil va au-dela du watermark initial. Trier en fonction du timestamp ou du montant des pourboires améliorerait la lisibilité de nos résultats. Malheureusement, les opérations de type “sort” ne sont pas encore supportées sur les données streaming en mode “append”. C’est l’une des limitations concernant Spark Structured Streaming.
Résumé
Spark Structured Streaming a été utilisé pour développer un pipeline de données en streaming. Après ingestion des données de Kafka, les trajets de taxis jaunes dans Manhattan ont été traitées en temps quasi réel avec Spark. Libre à vous d’en élargir le spectre géographique et de définir d’éfficientes frontières en utilisant par exemple des algorithmes de clustering en Machine Learning. Les concepts de jointure stream-stream, les opérations d’aggrégations ainsi qu’une démarche de feature engineering ont été évoquées. Dans cette partie, la démarche a été traitée dans un environnement locale. Le traitement sur un cluster Hadoop de ce même cas sera exposée dans l’article suivant. Nous parlerons du mode YARN et de sa faculté de distribution des tâches, ainsi que les problématiques liées à l’environnement distribué et la production.
