


Auto-scaling de Druid avec Kubernetes

16 juil. 2019
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Apache Druid est un système de stockage de données open-source destiné à l’analytics qui peut profiter des capacités d’auto-scaling de Kubernetes de par son architecture distribuée. Cet article est inspiré de la présentation “Apache Druid Auto Scale-out/in for Streaming Data Ingestion on Kubernetes” donnée par Jinchul Kim lors du DataWorks Summit 2019 Europe à Barcelone.
Druid
Druid est un système de stockage de données orienté colonne, distributé et open source qui est fréquemment utilisé dans le cadre d’application BI/OLAP pour effectuer des requêtes analytiques sur de larges quantités de données chaudes ou froides. Druid peut être considéré comme un mélange entre un moteur d’indexation comme Apache Solr ou Elasticsearch, une base de données timeseries comme Prometheus ou OpenTSDB et une base de données OLAP. Druid est actuellement sous incubation dans la fondation logicielle Apache. Un cluster Druid est composé de plusieurs rôles/services qui sont conçus pour être scalable facilement. De part des choix d’architectures particulier, Druid est “très” rapide pour certains cas d’usages.
Le processus de “roll-up”
Druid embarque une fonctionnalité de pré-aggrégation appellée le “roll-up”. Lors de l’ingestion des données, le logiciel ne va pas enregistrer les entrées une à une mais des aggrégations de ces dernières basées sur les différents champs de la donnée comme nous pouvons le voir dans l’exemple suivant :

Ces enregistrements sont stockés en tant que “segments” de sous forme de colonnes. Ces deux fonctionnalités font que Druid est très rapide pour répondre à des requêtes de types GROUP BY ou COUNT car les résultats ont déjà été calculées à l’ingestion. L’orientation colonne des données sert à lire uniquement les fichiers concernés par la requête.
Roles
Un cluster Druid est composé de plusieurs services conçus pour tourner sur des architectures cloud et distribuées :
- MiddleManager : Responsable de l’ingestion des données, il lis les entrées depuis des sources exterieures pour les transformer en segments. Il s’agit du service que nous allons essayer de scaler automatiquement avec Kubernetes.
- Historical : Gère le stockage et réponds aux requêtes sur les données déjà ingérées (données “historiques”).
- Broker : Reçoit les requêtes d’ingestion et de lecture des données et les réoriente vers le bon service (Historical ou Middlemanager).
- Overlord : Gère l’assignation des tâches d’ingestions aux noeuds Middlemanager.
- Coordinator : Gère la répartition des segments à traver les noeuds Historical du cluster.
Cela peut sembler compliqué au premier abord, mais avec un peu de pratique les rôles de Druid n’auront plus de secrets pour vous.
Auto-scaling
Druid dispose d’une fonctionnalité d’auto-scaling embarqué mais malheuresement elle est conçue pour ne fonctionner qu’avec Amazon EC2. Il y a donc un réel besoin pour les clusters Druid de pouvoir auto-scaler dans des environnements différents et sur du Kubernetes natif.
Kubernetes
Kubernetes (K8s) est un orchestrateur de containers. Si vous n’êtes pas très à l’aise avec le sujet ou que je vous souhaitez un cours de rattrapage, je vous invite à lire l’excellent article d’Arthur Busser à ce sujet “Installing Kubernetes on CentOS 7”. Un des aspects de Kubernetes qui n’est pas détaillé dans son article est sa faculté à auto-scaler les services qui tournent dessus. Voyons voir comment cela fonctionne.
Horizontal Pod Autoscaler
L’Horizontal Pod Autoscaler (HPA) est une fonctionnalité de Kubernetes qui donne aux utilisateurs la possibilité d’augmenter ou diminuer dynamiquement le nombre de pods d’un Replication Controller, d’un Deployment ou d’un ReplicaSet de manière automatique. Par défaut, cette fonctionnalité se base sur l’usage du CPU en utilisant l’API metrics.k8s.io du metrics-server (depuis que Heapster a été déprécié) et peut être étendue à des metrics personalisées avec l’API custom.metrics.k8s.io.
L’algorithme de décision du nombre de replicas est le suivant par défaut :
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]Voici maintenant un exemple dans le contexte de Druid :
Les Middlemanagers sont responsables de l’ingestions sous la forme de tâches (“tasks”). Ces tasks sont réalisées par un Middlemanager une par une. On peut donc décider qu’un cluster Druid avec beaucoup de tâches en attente (tâches attendant un Middlemanager disponible) est un cluster mal dimensionné.
Avec :
- currentReplicas : nombre de Middle managers, 3 pour commencer.
- desiredMetricValue : nombre de tâches en attente souhaité, décidons que 5 est acceptable.
- currentMetricValue : nombre de tâches en attente en ce moment, 10 pour l’exemple.
desiredReplicas = ceil[3 * (10 / 5)] = 6Dans ce cas là, Kubernetes va scaler le nombre de Middlemanagers en allouant 3 pods supplémentaires. Il y aura donc 6 Middlemanagers prêts à se répartir la charge.
Avec cette formule, on obtiendrait un nombre de Middlemanagers égal à zéro si aucune tâche n’est en attente. Ce n’est évident pas souhaitable et Kubernetes nous propose pour cela de définir une valeur minimum comme nous allons le voir après lors de la démo.
Custom Metrics API
Kubernetes fournit une API pour les metrics définies par l’utilisateur. Cette API peut être implémentée pour pourvoir utiliser des metrics customs dans les fonctionnalités natives de Kubernetes, ici c’est l’autoscaling avec HPA qui nous intéresse.
Il y a quelques implémentations disponibles plus communément appelées des “adapters”. Nous allons utiliser l’adapter Prometheus conçu par DirectXMan12. Prometheus est un projet de la CNCF qui est devenu le nouveau standard dans la récolte, le parsing et le stockage de metrics.
Il est également possible d’implémenter son propre Custom Metrics API à l’aide du boilerplate fourni.
Démo
Pour cette démo, j’ai déployé un cluster Kubernetes de 3 workers à l’aide du tutoriel d’Arthur. J’ai également installé un cluster Druid sur ce Kubernetes à l’aide de Helm et d’une chart associée. Helm est le package manager de Kubernetes qui simplifie énormément de choses. Il est très utile pour déployer des applications standards sur Kubernetes sans avoir à réinventer la roue.
Voici à quoi ressemble notre cluster Druid :
kubectl get pods -n druid -o wide
NAME READY STATUS RESTARTS AGE IP NOMINATED NODE READINESS GATES
druid-broker-5c6b4dd495-ppmvx 1/1 Running 2 65m 10.244.3.141 <none> <none>
druid-coordinator-748f4fd656-vkvjq 1/1 Running 1 65m 10.244.2.133 <none> <none>
druid-historical-0 1/1 Running 0 65m 10.244.3.143 <none> <none>
druid-middle-manager-0 1/1 Running 0 65m 10.244.3.144 <none> <none>
druid-middle-manager-1 1/1 Running 0 66m 10.244.3.146 <none> <none>
druid-middle-manager-2 1/1 Running 0 67m 10.244.3.147 <none> <none>
druid-mysql-6764889c67-f7l5r 1/1 Running 0 65m 10.244.2.131 <none> <none>
druid-overlord-5fcd7c49cd-nh764 1/1 Running 1 65m 10.244.3.142 <none> <none>
druid-zookeeper-0 1/1 Running 0 65m 10.244.2.132 <none> <none>
druid-zookeeper-1 1/1 Running 0 47h 10.244.3.145 <none> <none>
druid-zookeeper-2 1/1 Running 0 65m 10.244.1.147 <none> <none>Comme nous pouvons le voir, nous avons 3 Middlemanagers. Nous sommes donc dans une situation nominale par rapport à notre calcul ci-dessus.
La Web UI du Coordinator peut nous le confirmer :

Pour nous lancer, nous allons utiliser le projet GitHub k8s-prom-hpa de stefanprodan parce qu’il s’agit d’un excellent point de départ pour utiliser le HPA avec des metrics de Prometheus. Il contient toutes les ressources dont nous allons avoir besoin pour ce cas d’usage.
Déployons maintenant Prometheus dans notre cluster Kubernetes :
kubectl create -f prometheus/
configmap/prometheus-config created
deployment.apps/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus created
serviceaccount/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
service/prometheus createdNotre Prometheus est accessible au port que nous avons défini dans ./prometheus/prometheus-svc.yaml (31990) :
Nous pouvons constater dans l’onglet “Graph” que nous avons un paquet de metrics venant de Kubernetes comme l’utilisation CPU, RAM et disques par exemple. C’est parce que les scrapers Prometheus sont configurés pour lire directement depuis l’API REST de Kubernetes avec la configuration ./prometheus/prometheus-cfg.yaml.
Il y a également des configurations pour modifier les labels et noms des metrics.
Ces metrics sont intéressantes mais pour l’instant rien ne nous permets de d’auto scaler Druid selon nos critères définis précédemment.
Nous allons donc devoir récolter des metrics depuis Druid et laisser Prometheus les scraper.
Pour ce besoin et comme il s’agit uniquement d’un POC et pas de la production, j’ai écrit un un exporter Prometheus “très” basique pour exposer une seule metric, voici le code :
http = require('http')
axios = require('axios')
get_num_pending_tasks = () ->
axios.get "http://#{env.HOST}:#{env.PORT}/druid/indexer/v1/pendingTasks"
.then (response) ->
return response.data.length
server = http.createServer (req, res) ->
res.writeHead 200
res.end """
container_druid_num_pending_tasks #{await get_num_pending_tasks()}
"""
return
server.listen 8080On peut ensuite configurer un scraper Prometheus pour récupérer ces metrics, cela se passe dans le fichier ./prometheus/prometheus-cfg.yml qui défini le ConfigMap qui servira a générer le vrai fichier de configuration dans le container (/etc/prometheus/prometheus.yml) :
...
- job_name: 'druid_prometheus_exporter'
metrics_path: /
scheme: http
static_configs:
- targets:
- edge01.metal.ryba:49160
labels:
container_name: 'druid'
pod_name: 'druid-middle-manager-0'
namespace: 'druid'
...Notons que nous demandons à Prometheus d’ajouter des labels à ces metrics.
Après avoir redémarré Prometheus on peut voir notre metric apparaître :
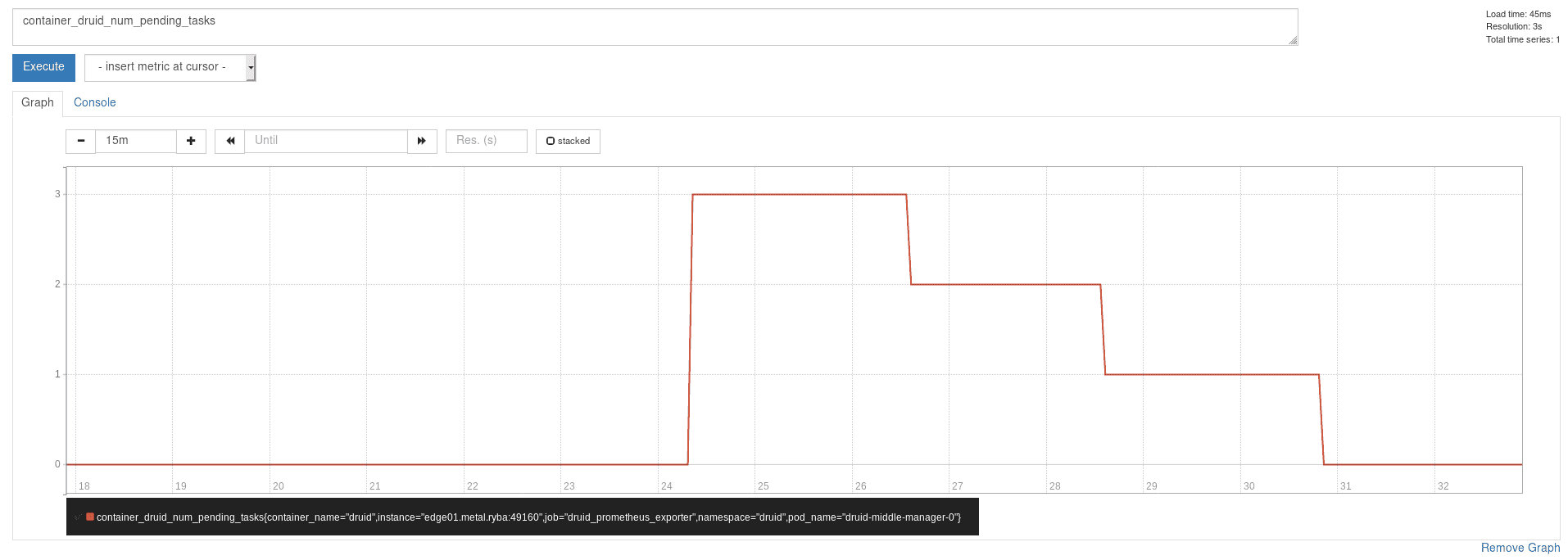
Nous sommes désormais prêts à deployer l’adapter Prometheus :
kubectl create -f custom-metrics-api/
secret/cm-adapter-serving-certs created
clusterrolebinding.rbac.authorization.k8s.io/custom-metrics:system:auth-delegator create
rolebinding.rbac.authorization.k8s.io/custom-metrics-auth-reader created
deployment.extensions/custom-metrics-apiserver create
clusterrolebinding.rbac.authorization.k8s.io/custom-metrics-resource-reader created
serviceaccount/custom-metrics-apiserver created
service/custom-metrics-apiserver created
apiservice.apiregistration.k8s.io/v1beta1.custom.metrics.k8s.io created
clusterrole.rbac.authorization.k8s.io/custom-metrics-server-resources created
clusterrole.rbac.authorization.k8s.io/custom-metrics-resource-reader created
clusterrolebinding.rbac.authorization.k8s.io/hpa-controller-custom-metrics createdL’adapter requête Prometheus pour récuperer les metrics, les parses et les expose sur la Custom Metrics API. Voyons voir si l’on peut trouver notre metric
kubectl get --raw "/api/custom.metrics.k8s.io/v1beta1/namespaces/druid/pods/*/druid_num_pending_tasks"
{"kind": "MetricValueList","apiVersion":"custom.metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/custom.metrics.k8s.io/v1beta1/namespaces/druid/pods/%2A/druid_num_pending_tasks"},"items":[{"describedObject":{"kind":"Pod","namespace":"druid","name":"druid-middle-manager-0","apiVersion":"/__internal"},"metricName":"druid_num_pending_tasks","timestamp":"2019-04-17T13:08:45Z","value":"3"}]}Cela fonctionne, nous pouvons voir qu’actuellement 3 tâches sont en pending et il s’agit d’une metric Kubernetes.
Nous pouvons désormais créer l’Horizontal Pod AutoScaler, voici la manière dont il est défini :
---
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
namespace: druid
name: druid-mm
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: StatefulSet
name: druid-middle-manager
minReplicas: 3
maxReplicas: 16
metrics:
- type: Pods
pods:
metricName: druid_num_pending_tasks
targetAverageValue: 5C’est plutôt facile à comprendre, il faut simplement définir :
- Un nom pour le HPA ;
- Une cible sur laquelle le HPA s’appliquera : ici notre StatefulSet “druid-middle-manager” ;
- Un minimum et maximum acceptables de replicas : c’est grâce à cela que l’on peut éviter de scaler n’importe comment en cas de fort ou faible nombre de requêtes ;
- Une metric avec sa valeur que nous souhaitons obtenir. C’est à partir de celle-ci que le HPA calcule le nombre de replicas.
Après avoir créer le HPA, on peut décrire cette ressource Kubernetes pour voir comment elle agit :
Nous avons actuellement 4 tâches en attente, le HPA nous indique donc que c’est un nombre acceptable comparé à l’objectif (targetAverageValue) que nous avons fixé :
kubectl describe -f druid/middlemanager-hpa.yaml
Name: druid-mm
Namespace: druid
Labels: <none>
Annotations: <none>
CreationTimestamp: Wed, 17 Apr 2019 13:41:50 +0000
Reference: StatefulSet/druid-middle-manager
Metrics: ( current / target )
"druid_num_pending_tasks" on pods: 4 / 5
Min replicas: 1
Max replicas: 16
StatefulSet pods: 3 current / 3 desired
Conditions:
Type Status Reason Message
---- ------ ------ --------
AbleToScale True ReadyForNewScale recommended size matches current size
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric druid_num_pending_tasks
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events: <none>Maintenant, nous allons soumettre notre cluster Druid à une grosse charge en déclanchant beaucoup de tâches d’ingestion en simultanément. Après quelques secondes, voici à quoi ressemble le HPA :
kubectl describe hpa druid-mm -n druid
Name: druid-mm
Namespace: druid
Labels: <none>
Annotations: <none>
CreationTimestamp: Wed, 17 Apr 2019 13:59:33 +0000
Reference: StatefulSet/druid-middle-manager
Metrics: ( current / target )
"druid_num_pending_tasks" on pods: 25 / 5
Min replicas: 1
Max replicas: 16
StatefulSet pods: 3 current / 6 desired
Conditions:
Type Status Reason Message
---- ------ ------ --------
AbleToScale True SucceededRescale the HPA controller was able to update the target scale to 6
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric druid_num_pending_tasks
ScalingLimited True ScaleUpLimit the desired replica count is increasing faster than the maximum scale rate
Events: <none>Et finalement, nous obtenons :
kubectl get pods -n druid -o wide
NAME READY STATUS RESTARTS AGE IP NOMINATED NODE READINESS GATES
druid-broker-5c6b4dd495-ppmvx 1/1 Running 66 47h 10.244.3.141 <none> <none>
druid-coordinator-748f4fd656-vkvjq 1/1 Running 1 47h 10.244.2.133 <none> <none>
druid-historical-0 1/1 Running 40 47h 10.244.3.143 <none> <none>
druid-middle-manager-0 1/1 Running 3 47h 10.244.3.144 <none> <none>
druid-middle-manager-1 1/1 Running 0 5h38m 10.244.3.148 <none> <none>
druid-middle-manager-2 1/1 Running 0 30m 10.244.3.150 <none> <none>
druid-middle-manager-3 1/1 Running 0 5m 10.244.3.150 <none> <none>
druid-middle-manager-4 1/1 Running 0 4m 10.244.3.150 <none> <none>
druid-middle-manager-5 1/1 Running 0 3m 10.244.3.150 <none> <none>
druid-mysql-6764889c67-f7l5r 1/1 Running 0 47h 10.244.2.131 <none> <none>
druid-overlord-5fcd7c49cd-nh764 1/1 Running 0 47h 10.244.3.142 <none> <none>
druid-zookeeper-0 1/1 Running 0 47h 10.244.2.132 <none> <none>
druid-zookeeper-1 1/1 Running 0 47h 10.244.3.145 <none> <none>
druid-zookeeper-2 1/1 Running 0 47h 10.244.1.147 <none> <none>Ça fonctionne ! Le StatefulSet a été scalé et nous avons maintenant 6 Middlemanager qui tournent et sont prêts à se répartir la charge.
Autre chose ?
Comme nous l’avons prouvé avec cette démo, l’auto-scaling de Druid avec Kubernetes est possible mais nous aurions pu mieux réaliser certaines choses. Pour commencer, nous aurions besoin d’un vrai exporter Prometheus pour les metrics de Druid. En effet celui que nous avons utilisé est très limité. Ce projet de Wikimedia a l’air très intéressant, il s’agit d’un endpoint qui utilise le http-emiter-module de Druid pour recevoir les metrics directement et les exposer au format compatible Prometheus. Cette application Python devrait être Dockerisée pour pouvoir tourner dans notre cluster Kubernetes. Le paquet Helm que nous avons utilisé pour déployer Druid aurait également besoin d’un certain nombre de modifications pour être compatible.
Le HPA que nous avons configuré a permis de scaler les Middlemanagers pour l’ingestion des données. Nous pouvons également imaginer un procédé similaire pour le requêtage de ces données. En surveillant les metrics de lecture du cluster, nous pourrions augmenter ou diminuer dynamiquement le nombre de noeud “Historical” pour pouvoir répondre à plus de reqûetes en parallèle.
Le HPA est une bonne solution pour faire de l’auto-sclaing avec Druid mais n’est pas vraiment viable dans le cadre d’un cluster Druid bare metal (non dockerisé dans Kubernetes). Espérons maitnenant que l’équipe qui maintient Druid pourra concevoir une implémentation plus flexible que celle qui existe actuellement avec EC2.
