


Hadoop Ozone partie 1: introduction du nouveau système de fichiers

3 déc. 2019
- Catégories
- Infrastructure
- Tags
- HDFS
- Ozone
- Cluster
- Kubernetes [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Hadoop Ozone est système de stockage d’objet pour Hadooop. Il est conçu pour supporter des milliards d’objets de tailles diverses. Il est actuellement en développement. La feuille de route est disponible sur le wiki du project.
Cette article est la première partie d’une série de trois articles présentant Ozone, démontrant son usage et proposant une stratégie de réplication avancée basée sur les Copyset.
Ozone supporte (ou cherche à supporter) plusieurs protocoles tels qu’Hadoop FS, REST (compatible S3) ainsi que la Container Storage Interface (CSI) de Kubernetes.
Ozone se veut être une amélioration d’HDFS : il passera mieux le passage à l’échelle, supportera des cas d’usages plus nombreux grâce au stockage d’objet et sera prêt pour les environnements conteneurisés (YARN et Kubernetes).
Les limitations d’HDFS
HDFS est conçu et optimisé pour le stockage de gros fichiers et s’est montré très fiable pour ce cas d’usage. Néanmoins il présente des difficultés de mise à l’échelle.
Le service NameNode est le composant responsable du namespace d’HDFS ainsi que de la gestion des blocs. Il conserve ses metadonnées en mémoire. La quantité de mémoire nécessaire est proportionnelle à la quantité de blocs et les difficultés commencent quand trop de fichiers sont créés. C’est pourquoi un traitement produisant des millions de petits fichiers met en danger la stabilité de tout un cluster.
Ozone est conçu pour répondre à ces difficultés en séparant la gestion du namespace et des blocs.
Ozone et HDDS
Ozone est un système de stockage objet exposant une API S3, une interface Hadoop RPC (OzoneFS) ainsi qu’une Container Storage Interface (CSI). OzoneFS est destiné à remplacer HadoopFS and fonctionnera dans n’importe quel traitement Hive, Spark ou MapReduce sans nécessiter de changement de code.
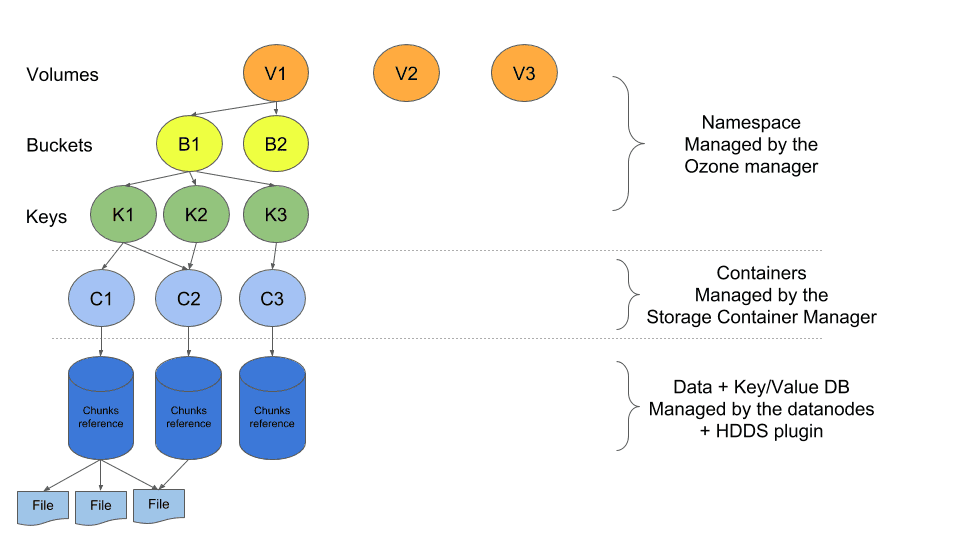
HDDS (Hadoop Distributed Data Store) est un framework de stockage de blocs distribué en haute disponibilité. Les deux composants d’HDDS sont le Storage Container Manager (SCM) et les noeuds stockant la donnée.
Dans l’architecture d’Ozone, les données sont stockées dans des conteneurs qui possèdent une taille fixée. Un conteneur maintient ses propres métadonnées dans une base de données clefs-valeurs. Cette base de données contient la liste des morceaux de données (nom du fichier, offset et taille). Ces conteneurs sont répliqués à travers le cluster afin de maintenir la disponibilité. Une fois le conteneur plein, il est automatiquement fermé et devient immuable.
Dans cet approche le SCM croît en fonction du nombre de conteneurs et pas avec le nombre de fichiers. Cet architecture permet de stocker autant de petits fichiers que désiré, qu’il soit de petite ou de grande taille.
Les conteneurs peuvent facilement être stockés dans un cluster HDFS puisqu’il s’agit simplement de gros fichiers (2-12Gio). Un plugin est nécessaire pour exécuter la base de données des conteneurs. HDFS n’est pas obligatoire pour le système de stockage d’Ozone : des DataNodes Ozone autonomes sont également disponibles.
Le namespace est géré par l’Ozone Manager (OM) qui maintient la cartographie clef-conteneur en mémoire. Il n’a pas besoin de connaître tout les fichiers gérés par le SCM. En réalité plus d’un Ozone Manager peut être connecté au SCM. Chaque Ozone manager maintenant sa propre liste de fichiers. Un Ozone Manager peut également contacter plusieurs SCM sans difficultés.
Ozone possède un namespace très simple, la hiérarchie se présente ainsi :
- Volumes : Un volume est possédé par un utilisateur et a une limite de taille. Un utilisateur peut créer des buckets et des clef dans son volume.
- Buckets : Un bucket contient de multiples objets (similaire à un bucket S3)
- Clefs : Une clef est unique et référence un object qui contient les données.
Le flux pour écrire un fichier est très similaire à HDFS. Les clients demandent à l’Ozone Manger, qui requête une pipeline au Storage Container Manager. Le client utilise cette pipeline pour écrire directement sur les datanodes au travers des conteneurs.
Conclusion
En résumé :
- L’Ozone Manager prend en charge son namespace : ses volumes, buckets et clefs.
- L’Ozone Manager sait dans quel conteneur sont stockées les données.
- Le Storage Container Manager maintient l’état des conteneurs. Il peut ête connecté à cluster HDFS pour la gestion du stockage.
- Le conteneur stocke les données ainsi que les informations à propos des fichiers qu’il contient.
Dans la prochaine partie de ce poste nous effectuerons une démo d’un Cluster Ozone : comment interagir avec au travers de ses différents points d’accès.
