


Hadoop Ozone part 1: an introduction of the new filesystem

Dec 3, 2019
- Categories
- Infrastructure
- Tags
- HDFS
- Ozone
- Cluster
- Kubernetes [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Hadoop Ozone is an object store for Hadoop. It is designed to scale to billions of objects of varying sizes. It is currently in development. The roadmap is available on the project wiki.
This article is the first part of a three-part series presenting Ozone, demonstrating its usage and proposing an advanced replication strategy using Copyset.
Ozone supports (or aims to support) multiple protocols such as Hadoop FS, S3-compatible REST and the Container Storage Interface (CSI) from Kubernetes.
It aims to be an improvement of HDFS: it will scale better, supports more use-cases with the help of the object store and is ready for containerized environments (YARN and Kubernetes).
HDFS limitation
HDFS was designed and optimised to store large objects and has proved to be very reliable for this use-case. But it comes with scaling issues.
The NameNode is the component in charge of the HDFS namespace and the block management. It holds its metadata in memory. The amount of memory being required is proportional to the amount of blocks being managed and creates scalability issues when too many files are created. Thus, a bad workload creating millions of small files endanger the stability of the whole cluster.
Ozone is designed to alleviate this issues by separating Namespace and block management.
Ozone and HDDS
Ozone is an object store that exposes an S3 API, an Hadoop RPC interface (OzoneFS) and an Container Storage Interface (CSI). OzoneFS is meant to be used as a replacement for HadoopFS and will work on any Hive, Spark or MapReduce job without any code changes.
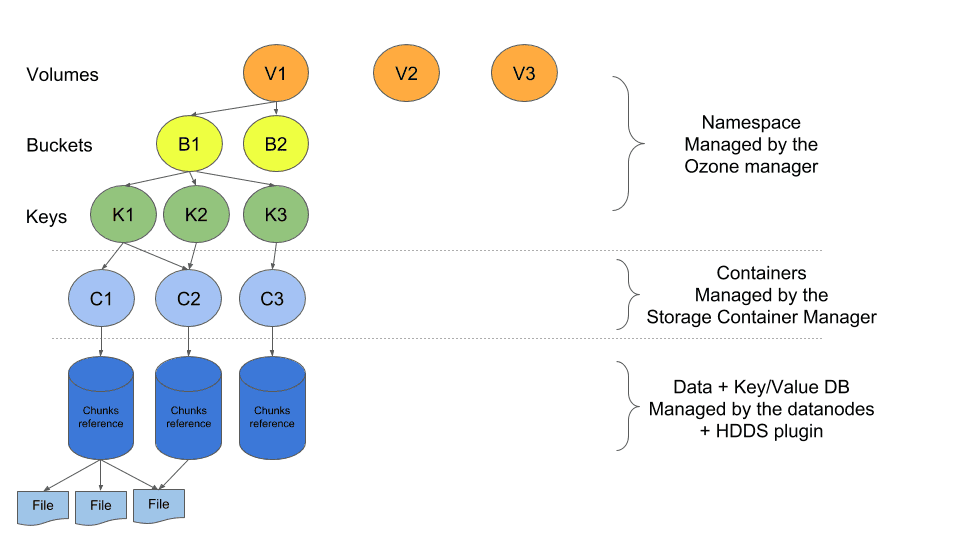
HDDS is a distributed highly available block storage framework. The two components of HDDS are the Storage Container Manager (SCM) and the data nodes.
In the Ozone world, data is stored inside containers which have a fixed size. A container maintains its own metadata in a key-value database. This database contains the list of files chunks (filename, offset and length). The containers are replicated across the cluster to maintain availability. Once a container is full, it automatically closes and becomes immutable.
With this approach, SCM scales with containers and not with files. This architecture allows to have as many files as we want, whether they are big or small in size. Containers can easily be stored in an HDFS cluster since they are simply big files (2-12GB). A plugin is required to “run” the container which means running the database of the container.
The Ozone Manager (OM) maintains the file-to-container mapping in memory. It does not need to know about all the files managed by the SCM. In fact, more than one Ozone Manager can contact the SCM. Each Ozone Manager maintains its own list of files. The Ozone Manager can also contact multiple SCM without issues.
Ozone keeps its namespace very simple. The hierarchy is:
- Volumes: A volume is owned by a user and has a size quota. The user can then create buckets and keys.
- Buckets: A bucket contains multiple objects (similar to a S3 bucket).
- Key: A key is unique and addresses an object which holds data.
Writing files workflow is very similar to HDFS. Clients asks the OM which then requests the Storage Container Manager for a pipeline. Client then uses this pipeline to write directly to the Datanodes through the containers.
Conclusion
To summarise:
- The Ozone Manager takes care of its namespace, namely volumes, buckets and keys.
- Ozone manager knows in which containers are data stored.
- The storage container manager maintains the container states. It can be connected to an existing HDFS Cluster as a storage manager.
- The container stores data as well as information about the files stored inside.
In the next part of this post we will play with a demo Ozone cluster: how we can interact with it through multiple access points.
