


Suivi d'expériences avec MLflow sur Databricks Community Edition

10 sept. 2020
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Introduction au Databricks Community Edition et MLflow
Chaque jour, le nombre d’outils permettant aux Data Scientists de créer des modèles plus rapidement augmente. Par conséquent, la nécessité de gérer les résultats et les modèles eux-mêmes devient évidente. MLflow répond à ce besoin avec ses capacités de suivi d’expériences, la prise en charge du packaging et son registre de modèles. Nous avons déjà décrit la déclinaison open-source de MLflow, que nous pouvons configurer et exécuter sur une machine locale. Dans ce tutoriel, nous allons essayer sa version gérée sur la plateforme Databricks Community Edition (CE). CE est une édition gratuite avec une puissance de calcul limitée, principalement dédiée à l’apprentissage. Les fonctionnalités de MLflow en mode hébergé sur CE sont limitées. Nous pouvons l’utiliser pour le suivi des expériences, mais nous ne pouvons pas servir des accès distants ou pour déployer le modèle. Le déploiement vers le registre n’est lui non plus pas supporté. De plus, nous ne pouvons pas exécuter de projets MLflow sur CE. Cependant, cela suffira à montrer les avantages du suivi des expériences et l’expérience utilisateur offerte par l’environnement Databricks.
Databricks Community Edition (CE) a déjà été décrit plus en détail et nous avons également montré comment importer un jeu de données dans l’environnement. Si vous avez besoin d’un rappel, vous pouvez commencer par cet article.
Créer un compte Databricks Community Edition
Tout d’abord, créez un compte Community Edition si vous ne l’avez pas déjà. Les fichiers que nous allons utiliser peuvent être téléchargés depuis mon dépôt GitHub :
- notebooks :
train_initial.ipynbavec le code de base du modèle que nous allons modifiertrain_final.ipynbavec toutes les modifications
- le jeu de données :
winequality-red.csv
Nous utiliserons le runtime standard Databricks Runtime. Il comprend Apache Spark et un certain nombre de composants et de mises à jour qui améliorent l’exploitabilité, les performances et la sécurité des traitements Big Data. J’utilisais Databricks Runtime 6.4 (Apache Spark 2.4.5, Scala 2.11) et MLflow 1.7.2.
Suivi d’expériences avec MLflow géré sur Databricks Community Edition
Note avant de commencer : le cluster Community Edition se désactive après 120 minutes de non-activité et vous ne pouvez pas le redémarrer. Si ça vous arrive, vous devrez le supprimer et en créer un nouveau.
Tout d’abord, créons un nouveau cluster en cliquant sur l’icône Clusters dans la barre latérale, puis sur Créer un cluster. Nommez-le mlflow et gardez une version d’exécution et une zone de disponibilité par défaut. Lorsque le cluster sera opérationnel, nous allons installer la bibliothèque mlflow.
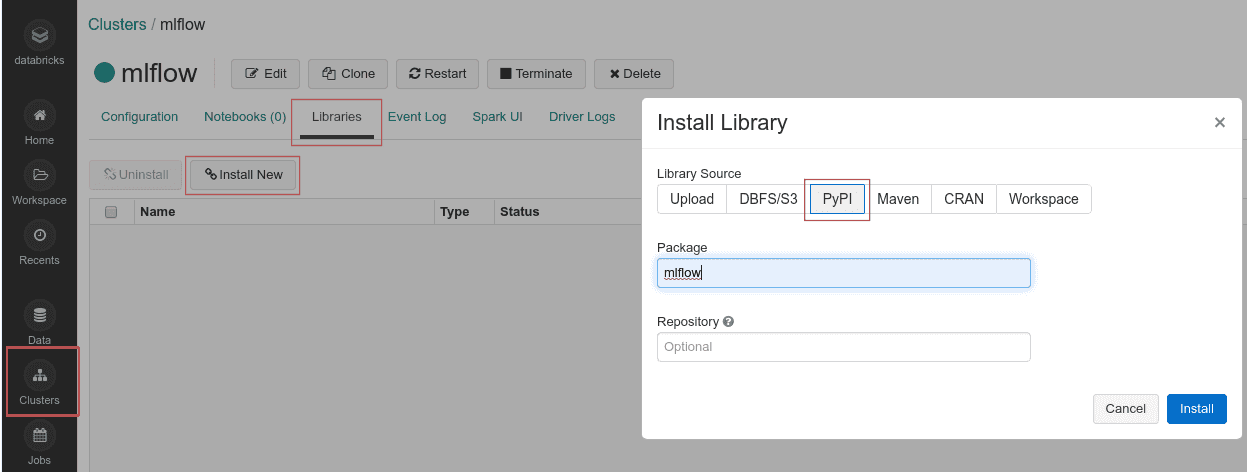
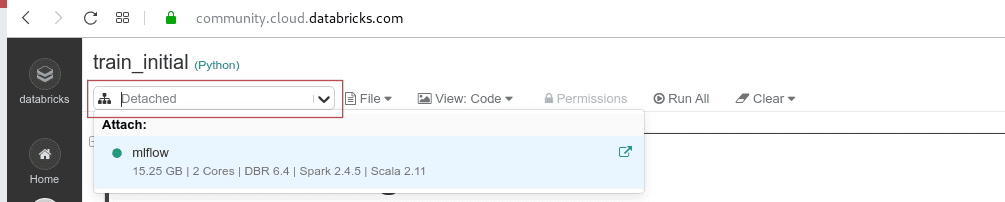
Allez dans Workspace et créez un nouveau dossier mlflow_test. Vous y sauvegarderez vos exécutions par la suite. En faisant un clic droit sur le nom, importez train_initial.ipynb. Après l’importation du notebook, cliquez sur son nom pour l’ouvrir. Actuellement, il n’est attaché à aucun cluster, donc vous ne pouvez pas l’exécuter. Vous pouvez l’attacher à votre cluster mlflow en cliquant sur le menu déroulant dans le coin supérieur gauche du notebook, sous le titre. Le cluster apparaîtra sur la liste et vous pourrez le joindre.
Ajoutez le nom de l’expérience au début de la fonction train. Une expérience désigne un groupe d’exécutions nommé.
def train(in_alpha, in_l1_ratio): # Une ligne existante
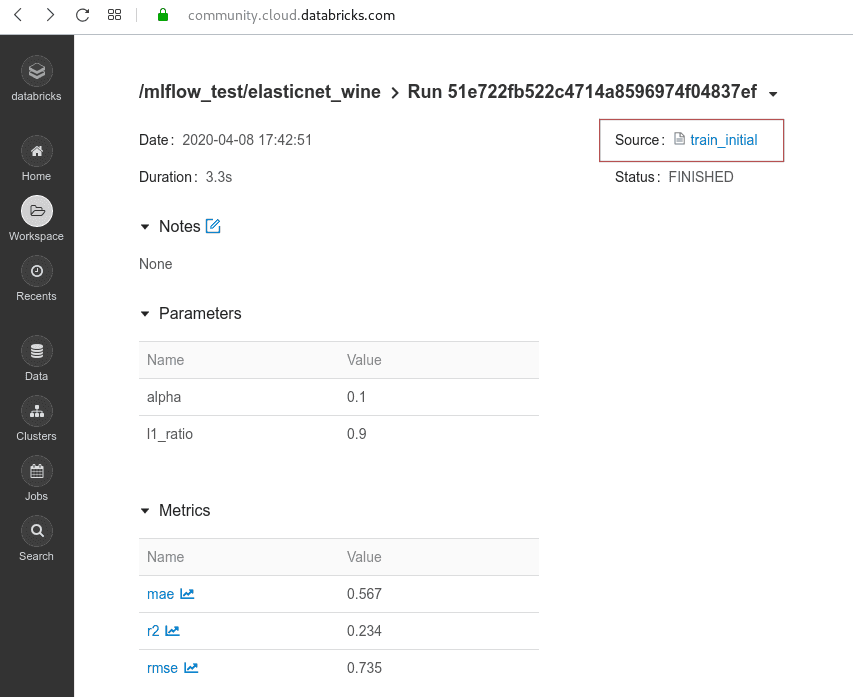
mlflow.set_experiment('/mlflow_test/elasticnet_wine')À la fin de la fonction, ajoutez les instructions pour sauvegarder les données que nous utilisons pour l’entraînement.
mlflow.sklearn.log_model(lr, "model") # Une ligne existante
data.to_csv('winequality_red.txt', encoding = 'utf-8', index=False)
mlflow.log_artifact('winequality_red.txt')Maintenant, nous allons tester différentes combinaisons des paramètres alpha et rations l1 dans notre modèle. Une fois tous les tests terminés, nous pouvons trouver les résultats dans /mlflow_test/elasticnet_wine. En cliquant sur le nom d’un test, nous voyons les détails, y compris les artefacts que nous avons sauvegardés. Tous les artefacts peuvent être téléchargés. De plus, nous avons accès au notebook avec le code source qui a produit ce modèle.
En cliquant dessus, nous ouvrons le notebook et à droite, nous avons un historique des changements. Si vous souhaitez restaurer d’anciennes versions du code, vous pouvez facilement le faire en cliquant sur Restore this revision.

Nous pouvons enrichir notre exemple avec une source de données reproductible. La version exacte des données de test doit être sauvegardée pour reproduire les expériences si nécessaire et à des fins d’audit. Dans notre cas, nous téléchargeons les données sur la qualité du vin à partir d’une URL chaque fois que nous exécutons le code. Il est facile d’imaginer que les auteurs de ce jeu de données le mettent à jour ou même le suppriment. Par conséquent, notre modèle commencera à produire des résultats différents ou échouera complètement, sans comprendre pourquoi. Nous allons examiner deux façons d’y remédier : tout d’abord, nous chargerons un ensemble de données dans le système de fichiers Databricks (DBFS) et créerons une table. Si vous ne savez pas comment faire, consultez cet article. J’ai nommé ma table wine_quality et elle est stockée dans la base de données wine_db.
Puisqu’on utilise Scikit-learn, il nous faut de données d’entrée en pandas DataFrame. Pour l’obtenir, on peut créer des Spark DataFrames à partir d’une table puis les convertir en pandas DataFrames. Il est important de comprendre que cela va collecter les partitions de données de tous les workers et créer une grande table dans la mémoire du driver, où elle sera traitée en mode nœud unique. Pour rappel, dans Databricks CE, nous n’avons pas de workers. Cela fonctionne bien si le jeu de données est suffisamment petit. Dans le cas de gros jeu de données, nous devrions utiliser Apache Spark MLlib, qui fonctionne sur des données distribuées.
data = spark.table("wine_db.wine_quality").toPandas()Vous pouvez utiliser cette options ci-dessus pour remplacer l’ensemble du bloc de téléchargement (Cmd 6 20-27). Vous êtes maintenant prêts à suivre vos expériences en ayant le contrôle de vos jeux de données.
Conclusion
Dans ce tutorial, nous avons découvert un environnement convivial, qui peut être facilement utilisé pour le suivi des expériences. Nous pouvons enregistrer des artefacts et des métriques pour une utilisation ultérieure, y compris les modèles et la liste des dépendances. La plateforme utilisée peut suffire pour une école ou un projet de loisirs, mais pour un usage professionnel, il faudrait se tourner vers la version open source ou Enterprise Edition.
