


Experiment tracking with MLflow on Databricks Community Edition

Sep 10, 2020
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Introduction to Databricks Community Edition and MLflow
Every day the number of tools helping Data Scientists to build models faster increases. Consequently, the need to manage the results and the models themselves is becoming evident. MLflow is a response to this need with its capabilities of experiment tracking, the support of packaging and its model registry. We already described open-source MLflow, which we can set up and run on a local machine. In this tutorial we will try out its managed version on the Databricks Community Edition (CE) platform. CE is a free edition with limited computing power, mostly dedicated to learning. Functionalities of hosted MLflow are restricted. We can use it for experiment tracking, but we cannot serve or deploy the model, nor save it to the registry. Also, we cannot run MLflow Projects on CE. However, this will suffice to show the benefits of experiment tracking and the user experience offered by the Databricks environment.
Databricks Community Edition (CE) was described before in more detail and we also showed how to import a dataset in the environment. If you need a refresher, you can start with this article first.
Create a Databricks Community Edition account
First, create a Community Edition account if you don’t have it, yet. The files we will be using, can be downloaded from my GitHub repository:
- notebooks:
train_initial.ipynbwith the base code for the model we are going to modifytrain_final.ipynbwith all the modifications
- data:
winequality-red.csv
We will use the standard Databricks Runtime. It includes Apache Spark and a number of components and updates that improve the usability, performance, and security of Big Data analytics. I was using Databricks Runtime 6.4 (Apache Spark 2.4.5, Scala 2.11) and MLflow 1.7.2.
Experiment tracking with managed MLflow on Databricks Community Edition
Before the start: Community Edition cluster becomes deactivates after 120 min of non-activity and you cannot restart it. You will need to delete it and create a new one.
First, let’s create a new cluster by clicking the icon Clusters in the side bar and then Create cluster. Name it mlflow and keep a default runtime version and availability zone. When the cluster is up and running, we need to install the mlflow library.
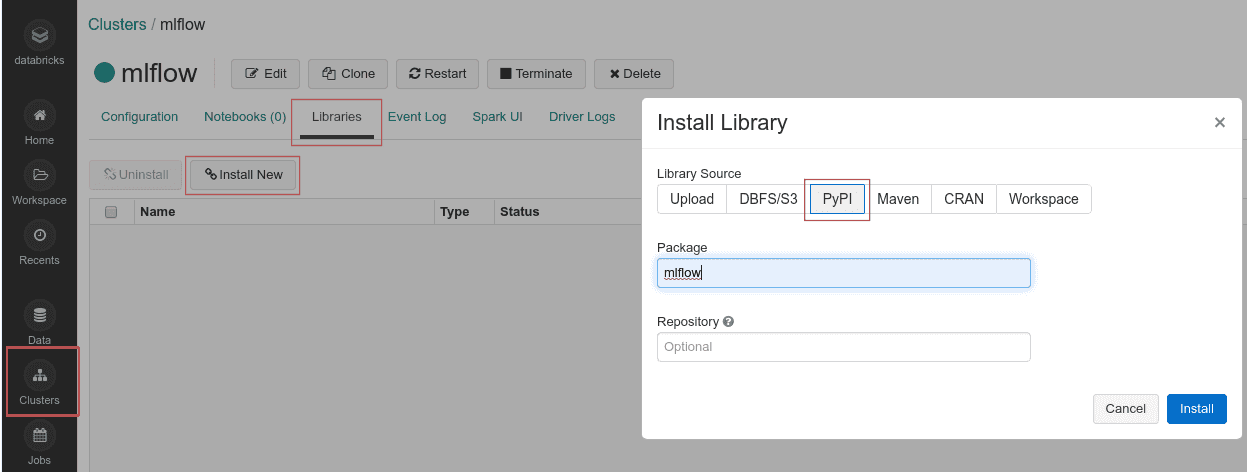
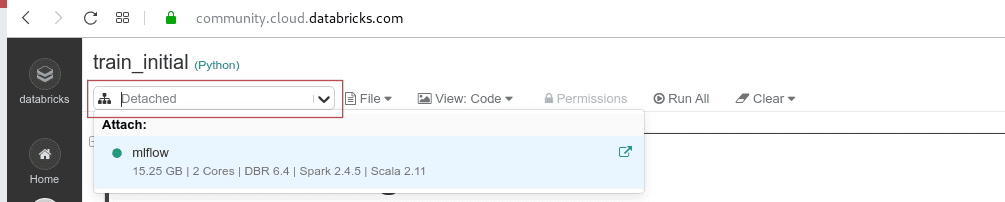
Go to Workspace and create a new folder mlflow_test to save the runs afterward. By right-clicking on the name, import train_initial.ipynb. After the notebook is imported, click on its name to open it. Currently it is not attached to any cluster, so you cannot run it. You can attach it to your mlflow cluster by clicking on the drop-down menu in the upper left corner of the notebook, below the title. The cluster will appear on the list and you attach it.
Add the experiment name at the beginning of train function. Experiment denotes a named group of runs.
def train(in_alpha, in_l1_ratio): # This line already exists
mlflow.set_experiment('/mlflow_test/elasticnet_wine')At the end of the function add instructions to save the data we are using for training.
mlflow.sklearn.log_model(lr, "model") # This line already exists
data.to_csv('winequality_red.txt', encoding = 'utf-8', index=False)
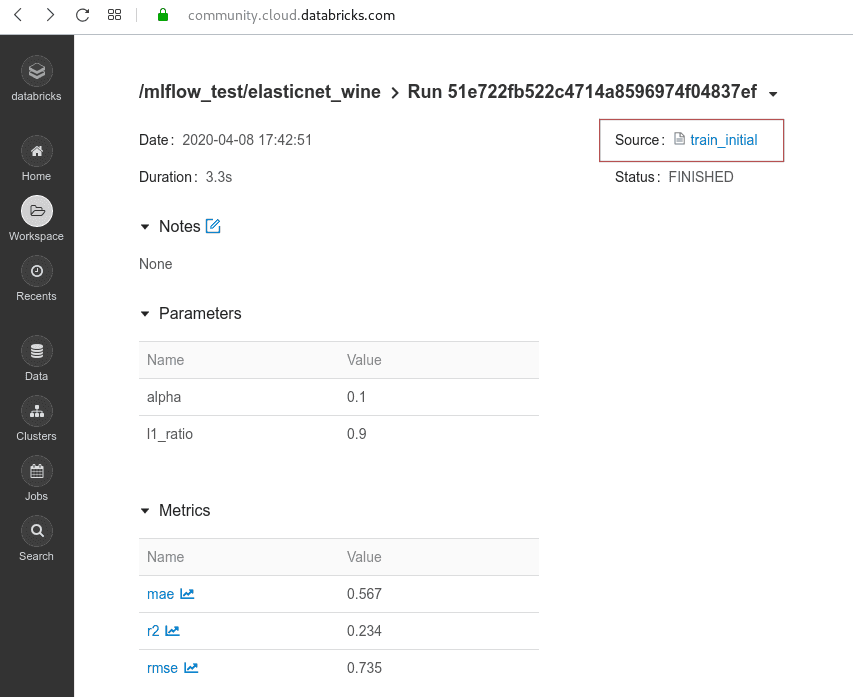
mlflow.log_artifact('winequality_red.txt')Next, we will test several different combinations of model parameters, namely alpha and l1_ratio. After all the runs are finished, we can find results in /mlflow_test/elasticnet_wine. With the click on the name of a run, we see the details, including the artifacts that we saved. All the artifacts can be downloaded. In addition, we have access to the notebook with the source code that produced this model.
If we click on it, we will open the notebook and on the right, we have a history of changes. If you would like to restore some older versions of the code, you can easily do it by clicking Restore this revision.

We can enrich our example with a reproducible data source. The exact version of the training data should be saved for reproducing the experiments if needed and for audit purposes. In our case, we download the wine quality data from a given URL each time we run the code. It is easy to imagine that authors of the dataset update it or even remove it. Consequently, our model will start producing different results or completely failing, without understanding why. Therefore, we will load a winequality-red.csv dataset to Databricks File System (DBFS) and create a table. If you don’t know how to do it, look it up here. I named my table wine_quality and stored it in wine_db database.
Since we are using Scikit-learn, we need input data as pandas DataFrame. We will obtain it by creating a Spark DataFrame from the table and convert it to pandas. It is important to understand that this will collect the data partitions from all worker nodes and create one large table in the driver’s memory, where it will be processed in a single-node mode. To recall, in Databricks CE we don’t have any worker nodes. This works well if a dataset is small enough. In a case of big datasets, we would need to use Apache Spark MLlib, which works on distributed data.
data = spark.table("wine_db.wine_quality").toPandas()You can use this option to replace the whole download block (Cmd 6 20-27) in the notebook. Now you are ready to track your experiments with the full control over your dataset.
Conclusion
In this tutorial, we discovered a user-friendly environment, which can be readily used for experiment tracking. We can save artifacts and metrics for later usage, including the models and list of dependencies. This setup might suffice for a school or a hobby project, but for professional usage, one would need to turn to either open-source version or Enterprise Edition.
