


Importing data to Databricks: external tables and Delta Lake

May 21, 2020
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
During a Machine Learning project we need to keep track of the training data we are using. This is important for audit purposes and for assessing the performance of the models, developed at a later time. Depending on the properties of a dataset, notably its size or its expected evolution with time, we need to choose an appropriate format to import it to a data analytics platform. If we have a small and rather simple table that will not change, we can usually import it as-is. But if the dataset is big and it is expected to be further modified (eg. in a case of streaming applications), a more sophisticated solution with Delta Lake, supporting data versioning, might be more appropriate. Databricks offers both options and we will discover them through the upcoming tutorial.
Introduction to Databricks and Delta Lake
Databricks is a unified data analytics platform, bringing together Data Scientists, Data Engineers and Business Analysts. User-friendly notebook-based development environment supports Scala, Python, SQL and R. The different available runtime environments are all based on Apache Spark, a distributed in-memory computing engine. They were designed and optimized for faster Big Data processing. Databricks is integrated with Amazon AWS and Microsoft Azure and it can connect with one of the third-party tools, like Tableau for visualization.
We can choose between two ways to gain trial access to Databricks. Community Edition (CE), hosted on AWS, is mostly dedicated to learning and will be used for this tutorial. In terms of compute, it offers 1 Driver with 15.3 GB Memory, 2 Cores, 1 DBU (Databrics Unit = unit of processing capability per hour) and no worker nodes. The time of utilization is not limited, but after 2 hours of idle period, the cluster will automatically terminate. Another possibility is a 14-days free trial, where you get access to all features (you will still be charged for the use of the cloud provider services).
Delta Lake is a storage layer on top of an existing Data Lake (based for example on Amazon S3 or Azure ADLS, where it helps to manage data quality. It supports ACID transactions, scalable metadata handling on data versioning. Its native format is Parquet, hence it supports parallel operations and it is fully compatible with Spark. One table in a Delta Lake is called a Delta Table. In contrast to Parquet tables, Delta Tables can be directly modified through inserts, updates, deletes, and merges (CRUD operations). Moreover, they can be used as a batch tables, as well as streaming source and sink. Delta Lake enables exactly-once processing during multiple streaming or concurrent batch jobs. It is available as an open-source project and as an enhanced managed version on Databricks.
Create a Community Edition account if you don’t have one yet. The files we will be using can be downloaded online:
- The notebook
data_import.ipynbto import the wine dataset to Databricks and create a Delta Table - The dataset
winequality-red.csv
I was using Databricks Runtime 6.4 (Apache Spark 2.4.5, Scala 2.11). Delta Lake is already integrated in the runtime.
Create an external table
The exact version of the training data should be saved for reproducing the experiments if needed, for example for audit purposes. We will look at two ways to achieve this: first we will load a dataset to Databricks File System (DBFS) and create an external table. Afterward, we will also learn how to create a Delta Table and what are its benefits. The code for this chapter is in data_import.ipynb notebook.
To create a table, we first need to import a source file into the Databricks File System. This is a distributed file system mounted into a Databricks workspace and available on Databricks clusters. It is important to know that all users have read and write access to the data. You can access it in many different ways: with DBFS CLI, DBFS API, DBFS utilities, Spark API and local file API. We will be using DBFS utilities. For example, we can examine the DBFS root.
display(dbutils.fs.ls('dbfs:/'))| path | name | size |
|---|---|---|
| dbfs:/FileStore/ | FileStore/ | 0 |
| dbfs:/databricks/ | databricks/ | 0 |
| dbfs:/databricks-datasets/ | databricks-datasets/ | 0 |
| dbfs:/databricks-results/ | databricks-results/ | 0 |
| dbfs:/mnt/ | mnt/ | 0 |
| dbfs:/tmp/ | tmp/ | 0 |
| dbfs:/user/ | user/ | 0 |
Files imported via UI will get stored to /FileStore/tables. If you delete a file from this folder, the table you created from it might no longer be accessible. Artifacts from MLflow runs can be found in /databricks/mlflow/. In /databricks-datasets/ you can access numerous public datasets, which you can use for learning.
Wine dataset is a single small and clean table and we can directly import it using sidebar icon Data and follow the instructions. This will copy the CSV file to DBFS and create a table. We can use Spark APIs or Spark SQL to query it or perform operations on it. A new table can be saved in a default or user-created database, which we will do next.
%sql
CREATE DATABASE IF NOT EXISTS wine_dbImport winequality-red.csv file as shown below. Change the name of the table and place it into an appropriate database. Pay attention to tick the boxes to read the first line as a header and to infer the schema of the table. Neither one of them is done by default in Spark.
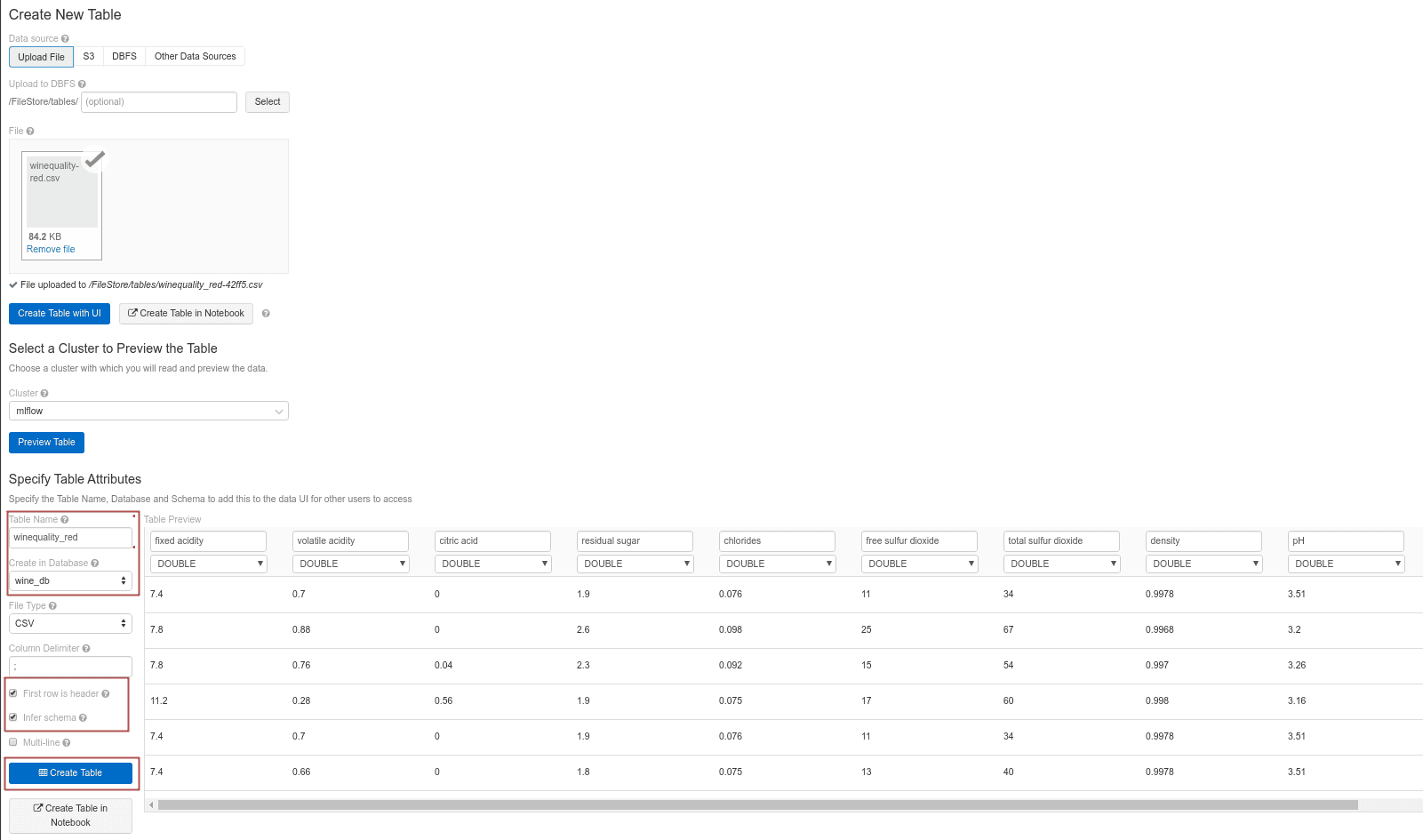
Once the table is created, we cannot easily modify it. The only way to do it is by modifying and reloading the source file and refresh the table. We can access the data programmatically in several ways. Here is an example with Spark API:
query = "select * from winequality_red"
wine = spark.sql(query)
display(wine)And the same example in Spark SQL:
%sql
SELECT * FROM winequality_redCreate a Delta Table
Now, let’s repeat the table creation with the same parameters as we did before, name the table wine_quality_delta and click Create Table with a notebook at the end. This will generate a code, which should clarify the Delta Table creation. We can divide it into four steps:
-
Import file to DBFS
-
Create a DataFrame
file_location = "/FileStore/tables/wine_quality-42ff5.csv"
file_type = "csv"
infer_schema = "true"
first_row_is_header = "true"
delimiter = ";"
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
display(df)- From the DataFrame, create a temporary view. When you don’t want to register a table, you can use a temporary view to work with, but it is accessible only from the notebook where it was created. If you don’t need it, you can skip this step.
#temp_table_name = "winequality_red-42ff5_csv"
temp_table_name = "winequality_red_view"
df.createOrReplaceTempView(temp_table_name)NOTE: If the file name includes -, then generated temp_table_name will include - (eg. -42ff5). This causes an error when running the code. Delete or replace -.
- Save DataFrame as a Delta Table. This data can be accessed from all the notebooks in your workspace.
permanent_table_name = "wine_quality_delta"
df.write.format("delta").saveAsTable(permanent_table_name)NOTE: If the names of columns include whitespaces or special characters, you will encounter an error. The solution is to rename the columns with the use of alias before saving:
from pyspark.sql.functions import col
df_corr = df.select(col('fixed acidity').alias('fixed_acidity'), col('volatile acidity').alias('volatile_acidity'), \
col('citric acid').alias('citric_acid'), col('residual sugar').alias('residual_sugar'), col('chlorides'), \
col('free sulfur dioxide').alias('free_sulfur_dioxide'), col('total sulfur dioxide').alias('total_sulfur_dioxide'), \
col('density'), col('pH'), col('sulphates'), col('alcohol'), col('quality'))
display(df_corr)
df_corr.write.format("delta").saveAsTable(permanent_table_name)This Delta Table was saved to Hive store:
display(dbutils.fs.ls('user/hive/warehouse'))Note that even though we specified a database, this option is ignored. In contrast to the previously created table, Delta Tables are mutable, so they can be used to store changing datasets or populate tables from streaming applications. They also support data versioning, where we can see the history of changes. We can easily access or even roll back to any historical version of the table.
To illustrate this functionality, let’s imagine that we are thee chemist who analyzed the wine samples and compiled the dataset. Suppose we discovered that analytical procedure to determine the quantity of citric acid is less sensitive than we thought. We decided not to delete the samples from the dataset, but to change all values of citric_acid less than 0.1 to 0. Let’s update the table.
%sql
UPDATE wine_quality_delta SET citric_acid = 0 WHERE citric_acid < 0.1However, by playing around too much, we accidentally deleted a part of the table.
%sql
DELETE FROM wine_quality_delta WHERE citric_acid = 0After all these modifications, we can check the history.
%sql
DESCRIBE HISTORY wine_quality_delta

We see all the changes listed in the table with many additional details. If we want to recover a specific version of the table, we can query it by version number or by timestamp. To recover a version before deletion, we select VERSION AS OF 1.
%sql
SELECT * FROM wine_quality_delta VERSION AS OF 1
-- or
SELECT * FROM wine_quality_delta TIMESTAMP AS OF '2020-04-09T15:20:11.000+0000'Conclusion
In this tutorial we explored two different methods of importing a dataset to Databricks. The external table is more suitable for immutable data or data that doesn’t change frequently, since we can modify it only by recreating and overwriting it. It also doesn’t offer any version control. On the contrary, a Delta table can easily be modified through inserts, deletes, and merges. In addition, all these modifications can be rolled back to obtain an older version of the Delta Table. That way Delta Lake offers us flexible storage and helps us to keep control over the changes in the data.
