

 : les composants et leurs fonctionnalités")
TensorFlow Extended (TFX) : les composants et leurs fonctionnalités

5 mars 2021
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
La mise en production des modèles de Machine Learning (ML) et de Deep Learning (DL) est une tâche difficile. Il est reconnu qu’elle est plus sujette à l’échec et plus longue que la modélisation elle-même, mais c’est pourtant elle qui maximise la valeur ajoutée pour une entreprise. De plus, une fois qu’un modèle a été déployé, il est nécessaire de le maintenir. Nous devons évaluer ses performances, la qualité des données nouvellement générées et l’adéquation de l’infrastructure sous-jacente. Le cas échéant, le modèle doit être réentraîné. L’ensemble du processus doit être automatisé, avec une intervention humaine aussi limitée que possible, pour le rendre durable à long terme. En outre, il est nécessaire de s’assurer que le modèle est fiable, cohérent, sécurisé, potentiellement évolutif, etc. Pour aider les organisations à mettre en œuvre un système de production de bout en bout de qualité industrielle, Google a rendu publique, début 2019, sa plateforme interne TensorFlow Extended (TFX).
TensorFlow Extended est la plateforme de Google pour la production et le déploiement de modèles ML. Elle est conçue pour être une plateforme de ML de bout en bout, flexible et robuste. Elle est basée sur les bibliothèques TensorFlow (TF), qui sont utilisées pour écrire des fonctions en Python, définies par l’utilisateur. Par exemple, pour entraîner un modèle (qui peut être ML ou DL), vous devez concevoir un TensorFlow Estimator ou un modèle Keras. La connaissance de ces technologies est une condition préalable pour bénéficier de TFX. La valeur ajoutée de TFX est l’intégration des fonctionnalités des bibliothèques TF dans des composants réutilisables, appelés composants standards. Ils peuvent être facilement connectés pour créer des pipelines avec un minimum de code supplémentaire. L’illustration ci-dessous montre la connexion entre les bibliothèques et les composants dérivés.
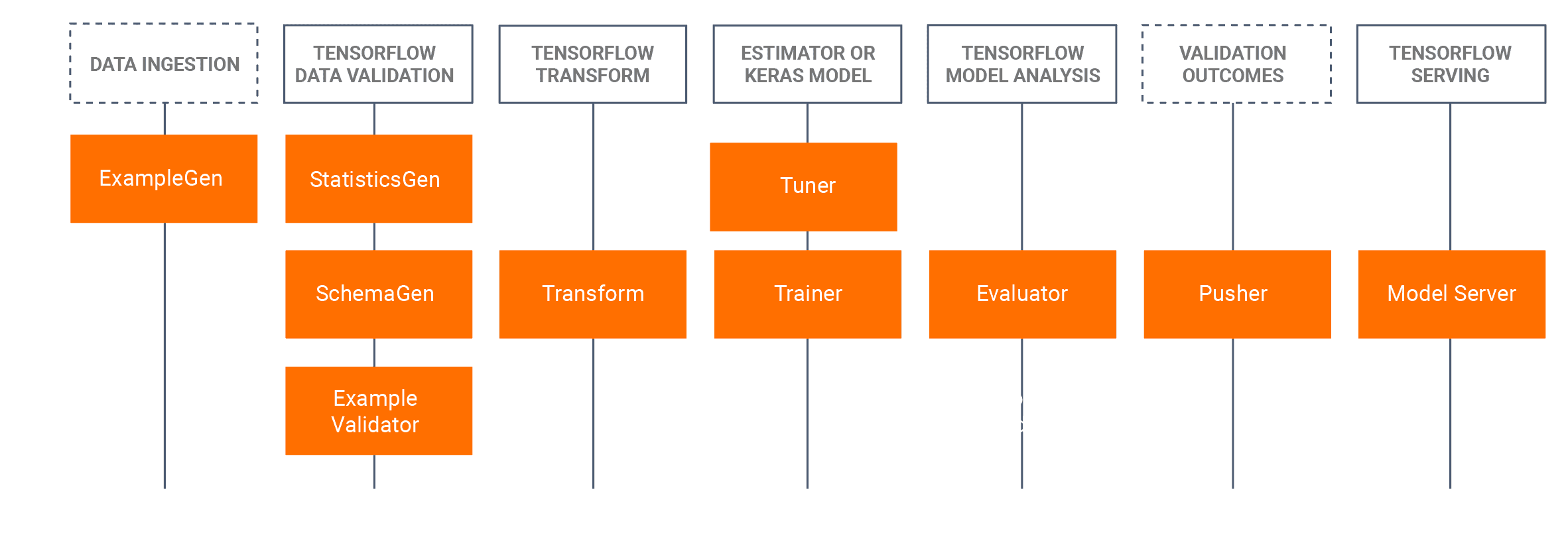
Les composants standards sont connectés de manière séquentielle pour former un pipeline. La sortie d’un composant est l’entrée d’un autre. Ils transmettent également les informations sur l’état actuel. Chaque exécution génère des métadonnées, qui sont conservées dans ce que l’on appelle le magasin de métadonnées (metadata store). Certains composants sont essentiels, d’autres non. Par exemple, nous pouvons omettre la validation des données (bloc StatisticsGen/SchemaGen/ExampleValidator) et passer directement de la génération de l’exemple (composant ExampleGen) au feature engineering (composant Transform). Plus loin, nous examinerons chaque composant et sa fonctionnalité individuellement, mais continuons maintenant avec d’autres concepts importants sur lesquels TFX s’appuie.
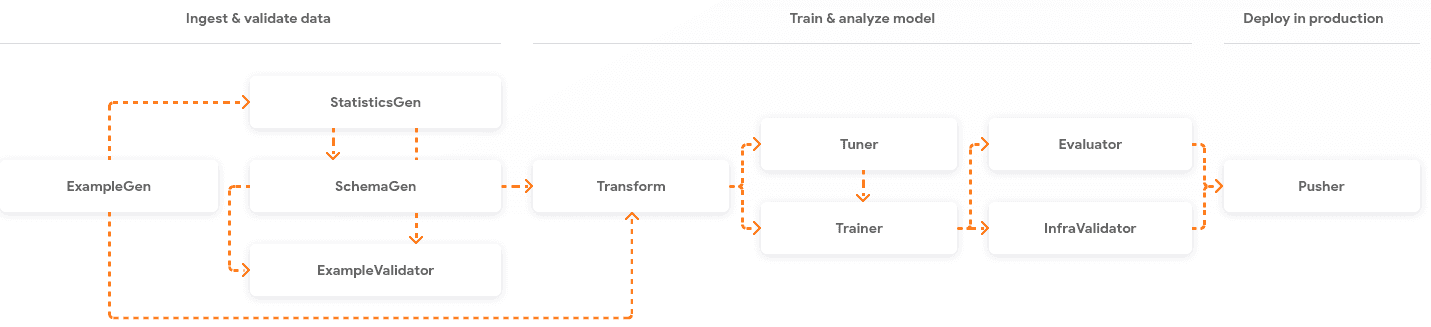
Tout d’abord, décrivons comment un composant est construit. Chaque composant comporte trois parties principales :
- driver (conducteur) : décide de ce qui doit être fait sur la base des métadonnées et coordonne l’exécution du travail
- executor (exécuteur) : code fourni par l’utilisateur pour résoudre la tâche à accomplir
- publisher (éditeur) : prend les résultats de l’executor et met à jour le metadata store.
Le driver et le publisher sont principalement le code que nous n’avons pas besoin de changer si la fonctionnalité standard suffit. Si nous voulons personnaliser l’executor, mais que nous gardons les entrées, les sorties et les propriétés d’exécution identiques, il est seulement nécessaire d’étendre l’executor. Pour une fonctionnalité complètement différente, il est possible d’écrire un executor entièrement personnalisé.
La plupart des composants fonctionnent sur Apache Beam, qui fournit un framework pour exécuter des calculs sur différents moteurs d’exécution. Il peut être utilisé pour le traitement des données par lots et en continu. Il assure la portabilité et l’évolutivité.
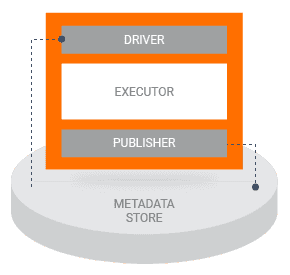
Le prochain concept important est le metadata store (magasin de métadonnées) déjà mentionné. Lors de l’exécution du pipeline, les composants estiment l’état du système en lisant les informations du metadata store, qui ont été produites par les composants précédents. Une fois qu’un composant est exécuté, il écrit sa propre sortie dans le metadata store. Cette information est appelée artefact et peut être stockée dans n’importe quelle base de données compatible SQL. Quelques exemples d’artefacts :
- informations sur les modèles, les données pour leurs entrainement et les métriques d’évaluation
- des registres d’exécution pour chaque composante
- le lignage des objets de données au fur et à mesure de leur passage dans le pipeline.
Ces informations nous permettent d’observer comment la modification des données affecte la modification des métriques. Nous en tirons parti pour l’entrainement warm-start et, en général, pour une architecture de pipeline consciente des tâches et des données.
Plongeons plus profondément dans les différents composants standards et illustrons leur utilisation. Comme TFX ne fait qu’étendre l’écosystème TF existant, vous pouvez également intégrer TensorBoard pour des visualisations supplémentaires telles que différents KPI si nécessaire.
Configuration
L’environnement
J’exécute le projet sur Arch Linux, où je gère mes environnements virtuels avec Miniconda.
Avant d’installer les bibliothèques, vérifiez la compatibilité des composants ici. Créez un environnement virtuel avec Python 3.7 et installez TensorFlow, TensorFlow Extended, Jupyter notebook, et éventuellement toute autre dépendance manquante ou incompatible.
$ conda --version
conda 4.9.1
$ conda create --name env_tfx python=3.7
$ conda activate env_tfx
(env_tfx)$ pip install tensorflow==2.3.0
(env_tfx)$ pip install tfx==0.24.1
(env_tfx)$ pip install notebookLe code
Vous pouvez exécuter le code à partir de ce notebook. Téléchargez-le dans le répertoire de votre projet. Dans mon cas, il s’agit de ./tfx. Dans le même répertoire, créez de nouveaux dossiers : data, artifacts, et serving_model.
tfx
├── artifacts
├── data
└── serving_modelL’ensemble de donnée
Nous utiliserons l’ensemble de données wine-quality.csv provenant du dépôt MLflow git. Le même ensemble de données a été utilisé dans mon article Expérience de suivi avec MLflow sur Databricks Community Edition.
Pour simplifier l’exemple, j’ai supprimé les guillemets autour des noms de colonnes et remplacé les espaces entre les mots par le tiret du bas. Vous pouvez le télécharger ici. Enregistrez-le dans votre dossier data.
Vue d’ensemble des composantes avec exemples
Définissons les chemins vers la racine, les données d’entrée, le stockage des artefacts et le stockage de la version finale (bénie) du modèle. Adaptez-les en conséquence à votre système. Pour faire fonctionner les composants de manière interactive, nous devons créer un contexte interactif.
import os
_data_root = './data'
_data_filepath = os.path.join(_data_root, "wine-quality.csv")
_pipeline_root = './artifacts'
_serving_model_dir = './serving_model'
from tfx.orchestration.experimental.interactive.interactive_context import InteractiveContext
context = InteractiveContext(pipeline_root=_pipeline_root)ExampleGen
Le composant ExempleGen crée une séparation train/test et ingère les données dans le pipeline. Au moment de la rédaction du présent document (février 2021), les sources et formats de données entièrement pris en charge sont CSV, tf.Record et BigQuery. Par ailleurs, des exécuteurs personnalisés sont disponibles pour Avro et Parquet et un composant personnalisé pour Presto. Avant la division, il réorganise l’ensemble des données pour éliminer le biais basé sur la commande.
from tfx.components.example_gen.csv_example_gen.component import CsvExampleGen
example_gen = CsvExampleGen(input_base=_data_root)
context.run(example_gen)Après l’exécution (non seulement pour ce composant mais aussi pour d’autres), un rapport avec quelques détails d’exécution est affiché. Cela vous montre quel type de résultats ont été générés.
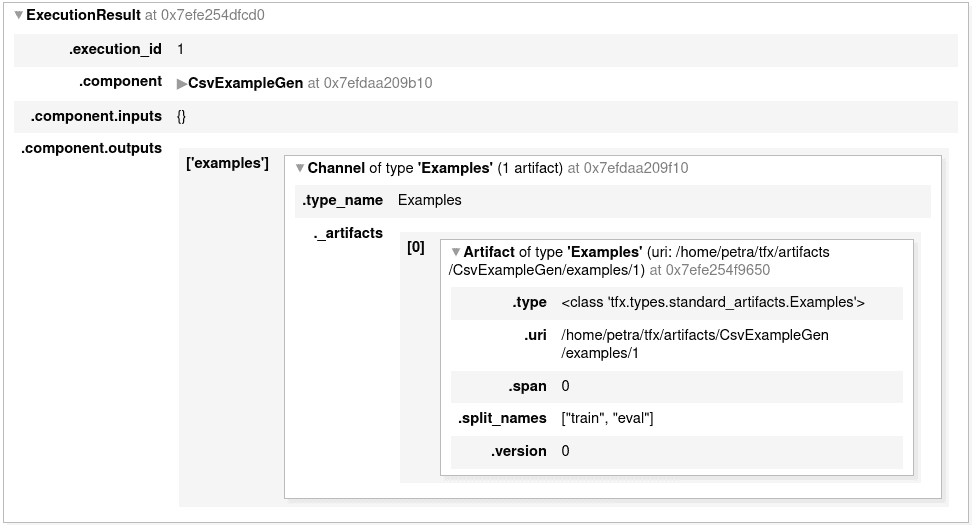
Vous pouvez explorer les informations les concernant en les imprimant.
example_gen.outputs['examples'].get()Vous pouvez également vous rendre à l’URI des artefacts et voir les objets créés.
(env_tfx) ➜ ~$ tree /home/petra/tfx/artifacts/CsvExampleGen/examples/1
/home/petra/tfx/artifacts/CsvExampleGen/examples/1
├── eval
│ └── data_tfrecord-00000-of-00001.gz
└── train
└── data_tfrecord-00000-of-00001.gzStatisticsGen
Le composant StatisticsGen génère des statistiques sur les données d’entraînement et de test, provenant de ExampleGen. Nous pouvons visualiser et comparer les propriétés de la répartion des données d’entraînement et de test et évaluer, par exemple, si les distributions des variables sont les mêmes. Il est basé sur la bibliothèque de validation des données TensorFlow, qui peut être utilisée indépendamment ou en conjonction avec des data frames pandas.
from tfx.components.statistics_gen.component import StatisticsGen
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'])
context.run(statistics_gen)
# Visualize the results
context.show(statistics_gen.outputs['statistics'])Vous trouverez ci-dessous un exemple de sortie de StatisticsGen sur les données test, affichant les distributions des variables.
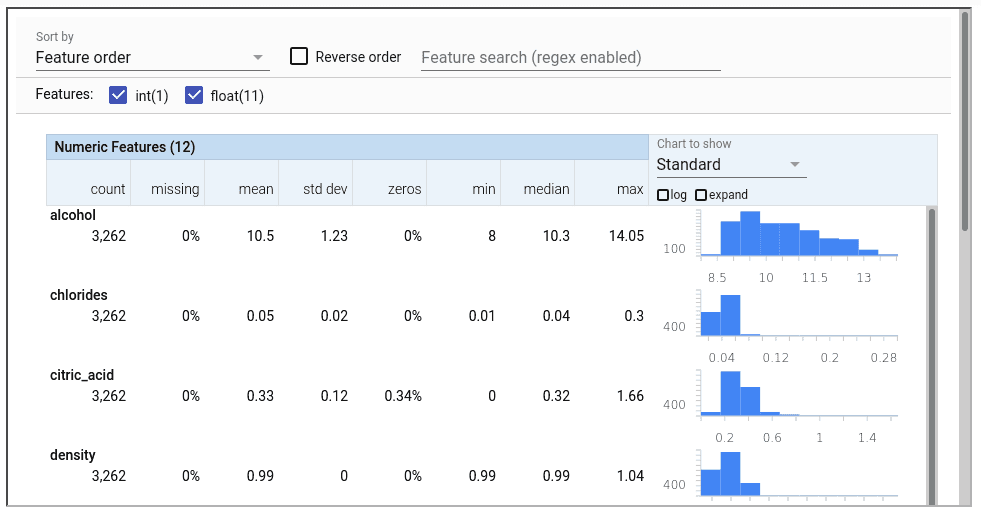
SchemaGen
Le composant SchemaGen effectue un passage sur les données train et test pour en déduire les types, les catégories et les intervalles.
from tfx.components.schema_gen.component import SchemaGen
infer_schema = SchemaGen(statistics=statistics_gen.outputs['statistics'])
context.run(infer_schema)
# Display schema
context.show(infer_schema.outputs['schema'])
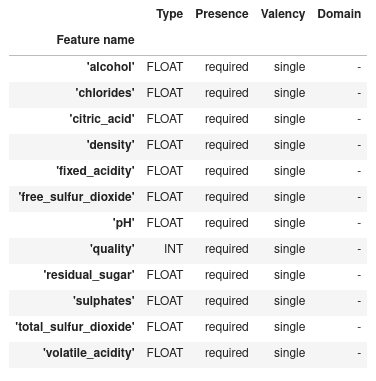
ExampleValidator
Le composant ExempleValidator utilise comme entrées des statistiques et des schémas générés précédemment. Il compare les propriétés des données train et test, et évalue s’il y a des différences (anomalies). Les catégories rares, qui ne sont présentes que dans un seul des ensembles de données après la divison, sont un exemple de ce type d’anomalie. Il vérifie également l’asymétrie entraînement/service (training-serving skew) et la dérive des données.
from tfx.components.example_validator.component import ExampleValidator
validate_stats = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=infer_schema.outputs['schema'])
context.run(validate_stats)
# Display differences between the train/test split
context.show(validate_stats.outputs['anomalies'])

Dans notre cas, le Validator ne détecte aucune différence entre les divisions. Lorsqu’il le fait, nous pouvons le répertorier et l’inspecter.
Transform
Le composant Transform effectue feature engineering. Par exemple, il génère des vocabulaires, enrichit des caractéristiques de texte, normalise ou standardise des valeurs, ou convertit des caractéristiques continues en catégories. Un des arguments est le module_file. Il s’agit du fichier contenant les fonctions définies par l’utilisateur pour les transformations de données. Tous les composants complexes utilisent cette logique pour séparer la configuration du composant lui-même de la logique de traitement.
Nous créons deux fichiers :
wine_quality_constants.pyregroupe les variables qui seront traitées de la même manière (par exemple le groupe de variables qui seront normalisées, celles qui seront codées en une fois…)- Le fichier
wine_quality_transform.pycontient les fonctions de transformation.
Cela s’avérera pratique plus tard puisque nous réutiliserons les définitions de variables pendant l’entraînement des données.
_constants_module_file = 'wine_quality_constants.py'%%writefile {_constants_module_file}
# We only have floating-point features and all will be processed the same way
DENSE_FLOAT_FEATURE_KEYS = ['alcohol', 'chlorides', 'citric_acid', 'density', 'fixed_acidity',
'free_sulfur_dioxide', 'pH', 'residual_sugar', 'sulphates', 'total_sulfur_dioxide', 'volatile_acidity']
# Label column
LABEL_KEY = 'quality'
def transformed_name(key):
"""Create new name of the variable after the transformation. """
return key + '_xf'_transform_module_file = 'wine_quality_transform.py'%%writefile {_transform_module_file}
import tensorflow as tf
import tensorflow_transform as tft
from wine_quality_constants import *
def preprocessing_fn(inputs):
"""Callback function for preprocessing inputs."""
outputs = inputs.copy()
# Transform LABEL_KEY to dense tensor
outputs[transformed_name(LABEL_KEY)] = fill_in_missing(inputs[LABEL_KEY])
# Standardize all the features (this is just to illustrate the functionality. Since we are using CART, standardization will not influence the performance of the model.)
for key in DENSE_FLOAT_FEATURE_KEYS:
outputs[transformed_name(key)] = tft.scale_to_z_score(fill_in_missing(inputs[key]))
return outputs
def fill_in_missing(x):
"""Replace missing values with 0 in a SparseTensor and convert to a dense tensor."""
default_value = 0
return tf.squeeze(
tf.sparse.to_dense(
tf.SparseTensor(x.indices, x.values, [x.dense_shape[0], 1]),
default_value),
axis=1)Exécutez Transform, en spécifiant le fichier contenant la logique de traitement avec la propriété module_file.
from tfx.components.transform.component import Transform
transform = Transform(
examples=example_gen.outputs['examples'],
schema=infer_schema.outputs['schema'],
module_file=_transform_module_file)
context.run(transform)
En plus des données transformées, le graphique de transformation est calculé et sauvegardé. Cela permet de s’assurer que les mêmes transformations sont appliquées pendant le service qu’elles l’étaient pendant l’entraînement.
Trainer
Le composant Trainer prépare les données d’entrée et entraîne le modèle. Il nécessite les exemples de ExampleGen, le schéma de SchemaGen, et le code pour l’entraînement. En option, il reçoit les hyperparamètres de Tuner (non montré dans cet article) ou un ensemble de paramètres d’un autre modèle pré-entraîné (warm-start). Le code d’entraînement peut être basé sur TensorFlow Estimators, des modèles Keras ou des boucles d’entraînement personnalisées.
Implémenter un Trainer implique davantage de code personnalisé que d’autres composants. Il doit gérer tous les pipelines d’entrée ainsi que la logique d’entraînement. La séparation de ces deux processus nous donne de la flexibilité dans la préparation des données. Nous prétraitons indépendamment les données provenant de différentes sources ou utilisées à différentes étapes (par exemple, l’entraînement et l’inférence), avant de les transmettre à l’estimateur.
_trainer_module_file = 'wine_quality_trainer.py'%%writefile {_trainer_module_file}
import tensorflow as tf
import tensorflow_model_analysis as tfma
import tensorflow_transform as tft
from tensorflow_transform.tf_metadata import schema_utils
from tfx_bsl.tfxio import dataset_options
from wine_quality_constants import *
# PREPARE FEATURES AND DEFINE THE ESTIMATOR
def _transformed_names(keys):
return [transformed_name(key) for key in keys]
# Specification of the schema to parse the data into tensors
def _get_raw_feature_spec(schema):
return schema_utils.schema_as_feature_spec(schema).feature_spec
# Define the estimator
def _build_estimator(config, n_batches_per_layer=1, n_trees=100,
max_depth=4, learning_rate=0.02):
"""Build a Boosted Trees Regressor for predicting the wine quality."""
features = [
tf.feature_column.numeric_column(key, shape=())
for key in _transformed_names(DENSE_FLOAT_FEATURE_KEYS)
]
# Regression tree with pre-defined mean squared error loss
return tf.estimator.BoostedTreesRegressor(
config=config,
feature_columns=features,
n_batches_per_layer=n_batches_per_layer,
n_trees=n_trees,
max_depth=max_depth,
learning_rate=learning_rate)
# INPUT PIPELINE
def _example_serving_receiver_fn(tf_transform_graph, schema):
"""Build the inputs for serving (inference)."""
# Get feature specifications and remove the label
raw_feature_spec = _get_raw_feature_spec(schema)
raw_feature_spec.pop(LABEL_KEY)
# Parses the tf.Example according to the provided feature_spec.
# Returns all parsed Tensors as features.
raw_input_fn = tf.estimator.export.build_parsing_serving_input_receiver_fn(
raw_feature_spec, default_batch_size=None)
serving_input_receiver = raw_input_fn()
# Transform the features according to the transform_graph.
transformed_features = tf_transform_graph.transform_raw_features(
serving_input_receiver.features)
return tf.estimator.export.ServingInputReceiver(
transformed_features, serving_input_receiver.receiver_tensors)
def _eval_input_receiver_fn(tf_transform_graph, schema):
"""Build everything needed for the tf-model-analysis to run the model."""
# Notice that the inputs are raw features, not transformed features here.
raw_feature_spec = _get_raw_feature_spec(schema)
serialized_tf_example = tf.compat.v1.placeholder(
dtype=tf.string, shape=[None], name='input_example_tensor')
# Add a parse_example operator to the tensorflow graph, which will parse
# raw, untransformed, tf examples.
features = tf.io.parse_example(serialized_tf_example, raw_feature_spec)
# Now that we have our raw examples, process them through the Transform
# function computed during the preprocessing step.
transformed_features = tf_transform_graph.transform_raw_features(
features)
# The key name MUST be 'examples'.
receiver_tensors = {'examples': serialized_tf_example}
features.update(transformed_features)
return tfma.export.EvalInputReceiver(
features=features,
receiver_tensors=receiver_tensors,
labels=transformed_features[transformed_name(LABEL_KEY)])
def _input_fn(file_pattern, data_accessor, tf_transform_output, batch_size=200):
"""Generates features and label for training and evaluation."""
return data_accessor.tf_dataset_factory(
file_pattern,
dataset_options.TensorFlowDatasetOptions(
batch_size=batch_size, label_key=transformed_name(LABEL_KEY)),
tf_transform_output.transformed_metadata.schema)
# HERE IT ALL COMES TOGETHER: TFX will call this function (it MUST be named trainer_fn)
def trainer_fn(trainer_fn_args, schema):
"""Build the estimator using the high-level API."""
# Model parameters
train_batch_size = 1000
eval_batch_size = 1000
n_trees=100
max_depth=5
learning_rate=0.05
# Input logic for each step
tf_transform_graph = tft.TFTransformOutput(trainer_fn_args.transform_output)
train_input_fn = lambda: _input_fn(
trainer_fn_args.train_files,
trainer_fn_args.data_accessor,
tf_transform_graph,
batch_size=train_batch_size)
eval_input_fn = lambda: _input_fn(
trainer_fn_args.eval_files,
trainer_fn_args.data_accessor,
tf_transform_graph,
batch_size=eval_batch_size)
# Configuration for the "train" part for the train_and_evaluate call.
train_spec = tf.estimator.TrainSpec(
train_input_fn,
max_steps=trainer_fn_args.train_steps)
serving_receiver_fn = lambda: _example_serving_receiver_fn(
tf_transform_graph, schema)
exporter = tf.estimator.FinalExporter('wine-quality', serving_receiver_fn)
# Configuration for the "eval" part for the train_and_evaluate call.
# Combines details of evaluation of the trained model as well as its export.
eval_spec = tf.estimator.EvalSpec(
eval_input_fn,
steps=trainer_fn_args.eval_steps,
exporters=[exporter],
name='wine-quaity-eval')
run_config = tf.estimator.RunConfig(
save_checkpoints_steps=999, keep_checkpoint_max=1)
run_config = run_config.replace(model_dir=trainer_fn_args.serving_model_dir)
# The model
estimator = _build_estimator(config=run_config,
n_trees=n_trees,
max_depth=max_depth,
learning_rate=learning_rate)
# Create an input receiver for TFMA (model analysis) processing
receiver_fn = lambda: _eval_input_receiver_fn(
tf_transform_graph, schema)
return {
'estimator': estimator,
'train_spec': train_spec,
'eval_spec': eval_spec,
'eval_input_receiver_fn': receiver_fn
}Nous sommes maintenant prêts à entraîner le modèle.
from tfx.components.trainer.component import Trainer
from tfx.proto import trainer_pb2
trainer = Trainer(
module_file=_trainer_module_file,
transformed_examples=transform.outputs['transformed_examples'],
schema=infer_schema.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=trainer_pb2.TrainArgs(num_steps=800),
eval_args=trainer_pb2.EvalArgs(num_steps=100))
context.run(trainer)Evaluator
Le composant Evaluator analyse le modèle et nous aide à comprendre comment le modèle a fonctionné. Au moyen de métriques statistiques (par exemple, l’AUC), il compare ses performances à celles du modèle de référence (par exemple, celui en production). Ou, comme dans cet exemple, il compare au seuil fixe d’une ou plusieurs métriques. Si le nouveau modèle satisfait la condition, il reçoit un tag ‘blessed’ (béni). Il s’agit d’un signal à Pusher indiquant qu’il est prêt à être poussé à un endroit précis.
Dans la configuration d’évaluation, nous définissons le type de modèle que nous évaluons (par exemple, service, EvalSavedModel), les métriques et les conditions, et sur quelle partie (tranche) de l’ensemble de données il sera évalué.
from tfx.types import Channel
from tfx.types.standard_artifacts import Model
from tfx.types.standard_artifacts import ModelBlessing
from tfx.components.evaluator.component import Evaluator
import tensorflow_model_analysis as tfma
eval_config = tfma.EvalConfig(
model_specs=[
# We are using estimator based EvalSavedModel: signature_name='eval'.
tfma.ModelSpec(signature_name='eval')
],
metrics_specs=[
tfma.MetricsSpec(
# The metrics added here are in addition to those saved with the model.
# The condition for a blessing is R2 > 0.3.
metrics=[
tfma.MetricConfig(
class_name='SquaredPearsonCorrelation',
threshold=tfma.MetricThreshold(
value_threshold=tfma.GenericValueThreshold(
lower_bound={'value': 0.3})
))]
)],
slicing_specs=[
# An empty slice spec means the overall slice, i.e. the whole dataset.
tfma.SlicingSpec()
])
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
eval_config=eval_config)
context.run(evaluator)Dans les sorties de evaluator.outputs, nous voyons que ce modèle a été béni, il sera donc poussé à un endroit approprié par le composant Pusher.
custom_properties {
key: "blessed"
value {
int_value: 1
}
}Pusher
Le composant Pusher vérifie la bénédiction du composant Evaluator et éventuellement du composant InfraValidator. Il évalue la compatibilité entre le modèle et le serveur binaire du modèle. Cela permet d’éviter que des modèles techniquement faibles ne soient mis en production. Si les résultats sont satisfaisants, le modèle est poussé vers un ou plusieurs objectifs de déploiement. La cible de déploiement peut être :
- TensorFlow Serving - système à haute performance pour les environnements de production
- TensorFlow Lite - pour les applications mobiles et IdO
- TensorFlow JS - déploiement des modèles dans le navigateur et sur Node.js.
Si nous ne voulons pas déployer, nous pouvons enregistrer le modèle sur TensorFlow Hub, un dépôt de modèles Machine Learning entraînés, ou simplement sur le système de fichiers local.
from tfx.components.pusher.component import Pusher
from tfx.proto import pusher_pb2
pusher = Pusher(
model=trainer.outputs['model'],
model_blessing=evaluator.outputs['blessing'],
push_destination=pusher_pb2.PushDestination(
filesystem=pusher_pb2.PushDestination.Filesystem(
base_directory=_serving_model_dir)))
context.run(pusher)Allez dans le répertoire désigné pour vérifier que le modèle s’y trouve.
(env_tfx) ➜ serving_model$ tree
.
├── 1610060570
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.indexConclusion
Dans cet article, nous avons examiné les concepts les plus importants et les fonctionnalités de base de TensorFlow Extended et nous avons créé notre premier pipeline. Mais il y a beaucoup plus à découvrir. Nous pouvons construire des composants personnalisés, programmer et faire fonctionner les pipelines avec Airflow, Kubeflow ou Beam. Comme il est construit sur TensorFlow, qui est disponible depuis 2015 et très populaire, il a une communauté d’utilisateurs avec une faible barrière d’entrée. Toutefois, lorsque TensorFlow n’est pas le framework principal, il peut présenter un intérêt limité. La courbe d’apprentissage est raide et les pipelines d’ingestion ne sont pas toujours intuitives. Cela n’est pas surprenant, car il a été conçu pour faciliter le travail de Google et en tenant compte de leurs problèmes spécifiques. TFX pourrait être considéré comme un produit spécialisé, destiné aux utilisateurs avancés de TensorFlow.
References
- TensorFlow Extended official website
- Article : TensorFlow Extended (TFX) : Real World Machine Learning in Production
- Research article : TFX : A TensorFlow-Based Production-Scale Machine Learning Platform
- Article : Towards ML Engineering : A Brief History Of TensorFlow Extended (TFX)
- Colab example : taxi pipeline
- Colab example : components
- Colab example : online news popularity pipeline
