


Parcourir DBnomics avec GraphQL et connecter son schéma OpenAPI

By WORMS David
8 avr. 2021
- Catégories
- DevOps & SRE
- Front End
- Tags
- Data Engineering
- JAMstack
- GraphQL
- JavaScript
- Node.js
- REST
- Schéma [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Aujourd’hui, dans le cadre de la rédaction d’un long et fastidieux document, il était mentionné DBnomics, une plateforme ouverte fédérant des ensembles de données économiques. En parcourant son site Web et ses APIs, j’ai trouvé son schéma OpenAPI (aussi connu sous le nom de Swagger). J’ai parcouru le schéma tout en gardant un deuxième onglet ouvert afin de télécharger les ensembles de données et de prévisualiser leur contenu associé. Le processus est chronophage et peu productif. Découvrir le schéma d’un côté et regarder son contenu associé de l’autre côté avec la lecture de JSON joliment imprimé d’un côté et le téléchargement/extraction de fichiers de l’autre côté. Et si je pouvais, à la place, parcourir un schéma et directement interroger son contenu. Depuis quelques années, il existe une technologies qui permet de faire exactement cela : GraphQL. Tout ce dont j’ai besoin est de convertir le schéma OpenAPI publié en un schéma GraphQL. Cela ne devrait pas prendre trop de temps. Plus important encore, cela m’a permis de trouver une distraction et un prétexte pour m’évader quelques heures de ma tâche en cours.
Le résultat final est consultable sur dbnomics.adaltas.com. Je vous invite à vous y rendre dès à présent si votre intérêt principal est de parcourir les sources de données DBnomics avec GraphQL. Vous pouvez commencer à créer vos propres requêtes ou modifier les exemples de requêtes disponibles en commentaires.
Aussi, vous pouvez vous rendre directement à la section Parcourir l’API DBnomics avec GraphQL pour mieux comprendre comment les requêtes GraphQL se composent.
Nous vous invitons à lire la suite de cet article pour découvrir comment nous avons réalisé cela, comment intégrer vous-même le code source et comment naviguer dans l’API DBnomics avec des exemples de requêtes. Voici ce que nous allons accomplir :
- Exposez tout schéma OpenAPI avec GraphiQL.
- Donnez à DBnomics l’interface utilisateur qu’il mérite pour naviguer dans son schéma et ses ensembles de données.
- Exécutez une requête GraphQL sur un schéma Graphql en mémoire, aucun code côté service n’est impliqué.
- Créez un composant React qui ne dépend pas d’un serveur local ni d’une URL d’entrée GraphQL, juste l’URL pointant vers le schéma OpenAPI.
- Apprenez à parcourir, créer et exécuter des requêtes GraphQL sur la source de données DBnomics.
A propos de GraphQL
GraphQL est une merveilleuse technologie, j’ai écrit sur ses principaux avantages par rapport à REST dans le passé et nous l’utilisons sur tous nos sites Web maintenant avec Gatsby.js et Next.js. Je l’enseigne à mes étudiants dans les cours de technologies Web. Il est aussi possible de brancher une interface Web pour parcourir l’API et créer des requêtes de manière interactive. GraphiQL permet précisément ceci (notez le i entre Graph et QL). Les sites Web Gatsby.js sont livrés nativement avec l’URL d’entrée /___ graphql en mode développement. Dans l’interface utilisateur de GraphiQL, le schéma est consultable sous forme d’arborescence et tout ce que vous avez à faire pour créer des requêtes est de sélectionner les champs à renvoyer et les filtres de requête. C’est facile, c’est rapide, cela ne nécessite pas de compétence en programmation ni de connaissance préalable du modèle de données. Voici à quoi ressemble le schéma du site Web Adaltas :
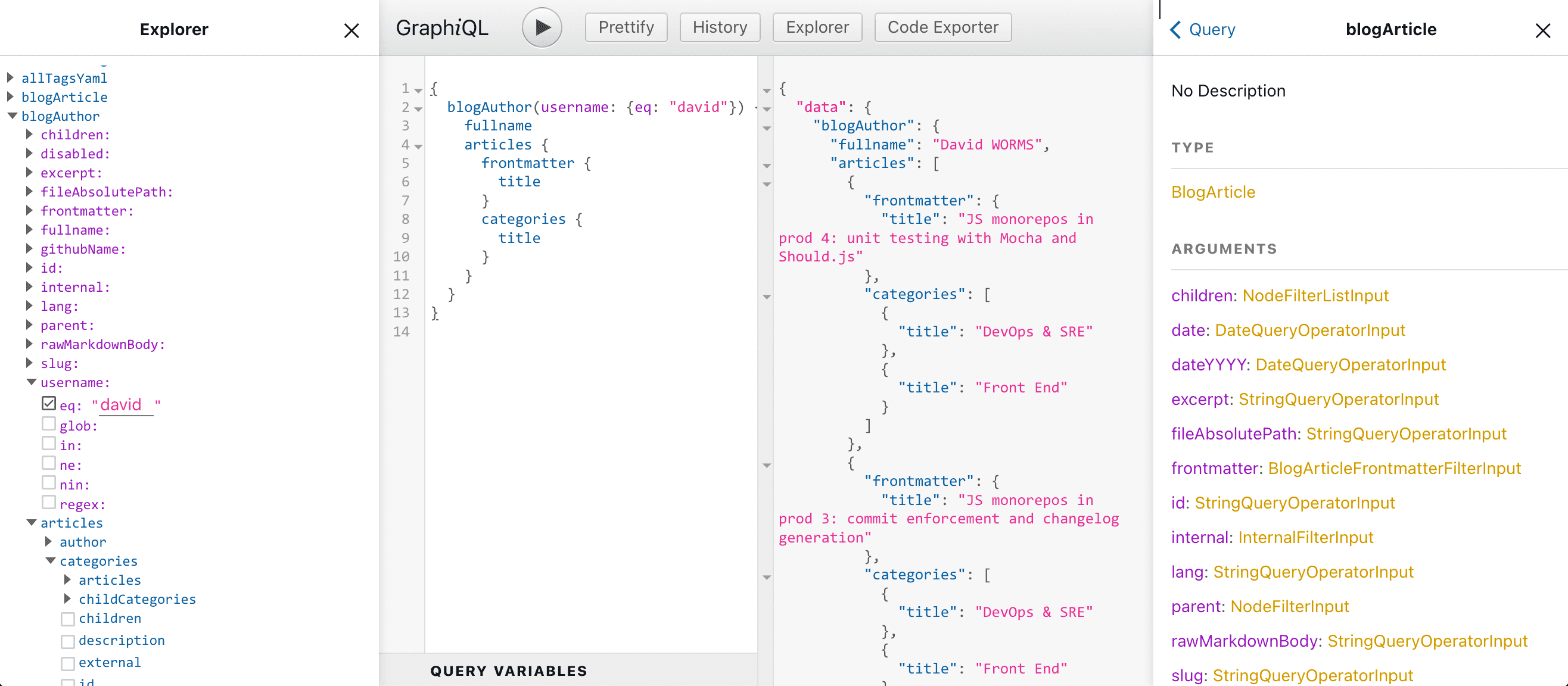
Imaginons que je souhaite obtenir une liste des articles et leurs catégories pour un auteur particulier. Je peux parcourir l’API dans le volet de documentation présent sur le côté droit. Plus commodément, j’utilise le panneau de l’explorateur présent sur le côté gauche. À l’aide de l’API Adaltas, voici comment créer une requête. Commençons par sélectionner le type GraphQL blogAuthor. Lors de la sélection, le champ se développe avec ses filtres associés (couleur violette) et ses champs (couleur bleue). Les champs décrivent un auteur ou d’autres type de données. Par exemple, le champ articles correspond à un autre type nommé blogArticle avec ses propres champs. Un article est lui-même lié à des catégories, un autre type appelé blogCategory dans notre cas. Ainsi, les enregistrements sont connectés entre eux. C’est de là que vient le terme graph de GraphQL. La requête se construit automatiquement et progressivement en fonction des champs sélectionnés dans le volet de l’explorateur. Voici un exemple de requête :
{
blogAuthor(username: {eq: "david"}) {
fullname
articles {
frontmatter {
title
}
categories {
title
}
}
}
}Connexion entre GraphQL et OpenAPI côté serveur
L’API DBnomics est bien documentée et indique l’emplacement de son schéma OpenAPI. OpenAPI s’appelait autrefois Swagger. Aujourd’hui, OpenAPI est la spécification tandis que Swagger comprent une suite d’outils populaires pour la mise en œuvre de la spécification OpenAPI. Le paquet swagger-to-graphql est adapté pour convertir un schéma OpenAPI en un schéma GraphQL. Au début, j’ai suivi les instructions du fichier README. Celles-ci préconisent notamment de démarrer un serveur HTTP Node.js avec Express.js et d’exposer l’interface utilisateur GraphiQL sous l’URL d’entrée /graphql. Il semble que c’était tout ce dont j’avais besoin. Par conséquent j’avais simplement besoin d’implémenter la fonction callBackend qui accepte des arguments que l’API REST de DBnomics se procurera. Au final, j’ai passé plus de temps à travailler autour de TypeScript qu’à intégrer la bibliothèque. Le code final est disponible sur GitHub dans le projet adaltas/demo-dbnomics-graphql. Une version simplifiée de ce code ressemble à ceci :
const app = express();
async function callBackend({
requestOptions: {path, query, headers, body, method},
}: CallBackendArguments<Request>) {
const baseUrl = "https://api.db.nomics.world/v22";
const url = `${baseUrl}${path}?${new URLSearchParams(query as Record<
string,
string
>)}`;
const response = await fetch(url, {
method,
headers: {
'Content-Type': 'application/json',
...headers,
},
body: body && JSON.stringify(body),
});
return JSON.parse(await response.text());
}
createSchema({
swaggerSchema: `https://api.db.nomics.world/v22/apispec_1.json`,
callBackend,
})
.then(schema => {
app.use(
'/graphql',
graphqlHTTP(() => {
return {
schema,
graphiql: true,
};
}),
);
app.listen(3009);
});Et ça marche ! Le serveur démarre et l’interface utilisateur est exposée sur http://localhost:3009/graphql. Cependant, je me suis vite rendu compte qu’il me manquait un élément clé. En effet Le volet de l’explorateur que je chérissait tant a disparu. Après quelques recherches sur Google, j’ai réalisé qu’il ne faisait pas partie de GraphiQL mais d’un plugin externe nommé graphiql-explorer. En cherchant plus, j’ai compris que mon espoir initiale, de simplement enregistrer le composant dans une propriété acceptant une liste de plugins, serait remis en question. C’est à ce moment précis que les choses sont devenues un peu plus compliquées.
Connexion entre GraphQL et OpenAPI côté client
graphiql-explorer ne s’enregistre pas comme plugin de GraphiQL. Au lieu de cela, les différents composants React.js doivent être branché les uns avec les autres et cela ne peux se faire que du côté client. J’ai dû les connecter manuellement, comme décrit dans l’exemple graphiql-explorer-example ou dans le code source de Gatsby. Hélas, je ne pouvais plus utiliser le code développé précédemment. Au cas où vous en auriez besoin, il est archivé sur la branche server du dépôt adaltas/demo-dbnomics-graphql. Ainsi, j’ai abandonné mon implémentation initiale, démarré une nouvelle application React.js avec react-create-app et importé le code de l’application GraphiQL sample application. Vous trouverez ce code dans la branche master du dépôt adaltas/demo-dbnomics-graphql.
Grâce à mes précédentes expériences sur le sujet, je sais comment convertir le schéma Swagger en schéma GraphQL. Pour cela j’ai converti la fonction React componentDidMount de graphiql-explorer-example en :
async componentDidMount() {
const schema = await createSchema({
swaggerSchema: `https://api.db.nomics.world/v22/apispec_1.json`,
callBackend,
})
this.setState({schema: schema})
}La dernière chose à faire était de réimplémenter la fonction fetcher. Le code d’origine, comme décrit dans chaque documentation et échantillon que j’ai trouvés sur Internet, permet de récupérer les données de l’URL d’entrée GraphQL. Dans mon cas, il n’y a pas d’URL d’entrée GraphQL. Au lieu de cela, le code exécute la requête GraphQL sur le schéma GraphQL déjà chargé en mémoire. Ici tout se passe dans le client. Je n’ai donc pas besoin d’un serveur et ça tombe très bien puisque je ne voulais pas en démarrer un. Par conséquent, j’ai choisi de m’en tenir à l’architecture Jamstack en gardant tout sur le client, le serveur qui contient le schéma et les données qu’il prend en charge existant déjà puisqu’il s’agit de l’API REST DBnomics. Le site final consultable sur dbnomics.adaltas.com est hébergé sur la plateforme serverless de Netlify.
Il m’a fallu du temps pour trouver comment implémenter la fonction fetcher. Par ingénierie inverse, j’ai disséquer le fonctionnement du middleware Express.js Graphql qui consiste à obtenir une requête à partir de la requête HTTP et d’en renvoyer les données dans la réponse HTTP.
Le code ressemble à :
const fetcher = async ({query}, schema) => {
const documentAST = parse(new Source(query, 'GraphQL request'));
const result = await execute({
schema: schema,
document: documentAST,
});
return result;
}Cette approche a fonctionné, l ’API DBnomics est maintenant exposée avec GraphQL. Tout le monde peut parcourir et découvrir de manière interactive le contenu qu’elle stocke. Le code est un composant React.js qui peut être réutilisé dans vos applications Web.
Limitation du schéma OpenAPI DBnomics
Il existe cependant une limitation dans la conversion de schéma OpenAPI vers GraphQL. Le schéma DBnomics OpenAPI définit uniquement un sous-ensemble des champs disponibles dans les résultat de données. Le problème inclut tous les points de terminaison commençant par /series. Le chemin concerné est .get.responses [200] .schema.properties.series.properties.docs.items.properties. Seuls les dataset_code, provider_code et series_code sont listés. Étant donné que GraphQL nécessite que les champs de retour soient explicitement déclarés, il n’y a pas de solution pour accéder aux autres champs associés. Cette limitation s’avère problématique car ce sont précisément ces champs qui contiennent les données du jeu de données. Les autres champs étant des méta-données.
La solution que j’ai prise est de patcher le schéma OpenAPI avant de le convertir. La propriété concernée est déclarée comme un type objet, mais sans déclarer les propriétés qu’elle contient. Ainsi toutes ses propriétés sont renvoyées, et non un sous-ensemble de celles-ci. Nous perdons la granularité de la sélection des champs renvoyés, mais nous obtenons au moins le contenu de l’ensemble des données. La fonction réécrite componentDidMount est maintenant :
async componentDidMount() {
const swaggerSchemaReq = await fetch(`https://api.db.nomics.world/v22/apispec_1.json`)
const swaggerSchemaText = await swaggerSchemaReq.text();
const swaggerSchema = JSON.parse(swaggerSchemaText);
swaggerSchema.paths
["/series"]
.get.responses[200].schema.properties.series.properties.docs.items = {
type: 'object'
}
swaggerSchema.paths
["/series/{provider_code}/{dataset_code}"]
.get.responses[200].schema.properties.series.properties.docs.items = {
type: 'object'
}
swaggerSchema.paths
["/series/{provider_code}/{dataset_code}/{series_code}"]
.get.responses[200].schema.properties.series.properties.docs.items = {
type: 'object'
}
const schema = await createSchema({
swaggerSchema: swaggerSchema,
callBackend,
})
this.setState({schema: schema})
}Parcourir l’API DBnomics avec GraphQL
Les différents points de terminaison REST sont convertis en champs GraphQL. Leur nom est accessible dans les volets de la documentation et de l’explorateur :
get_datasets_provider_code
URL d’entrée REST OpenAPI :/datasets/{code_fournisseur}
Répondre à un ou plusieurs jeux de données d’un fournisseur.get_datasets_provider_code_dataset_code
URL d’entrée REST OpenAPI :/datasets/{provider_code}/{dataset_code}
Répondre à un ou plusieurs jeux de données d’un fournisseur.get_last_updates
URL d’entrée REST OpenAPI :/last-updates
Répond à une liste de fournisseurs et à une liste de jeux de données triés par date de création/conversion, les plus récents en premier.get_providers
URL d’entrée REST OpenAPI :/providers
Répond à une liste de fournisseurs.get_providers_code_provider
URL d’entrée REST OpenAPI :/providers/{provider_code}
Répondre à un fournisseur avec son arbre des catégories.get_search
URL d’entrée REST OpenAPI :/search
Répond à une liste de jeux de données à partir d’une recherche en texte intégral.get_series
URL d’entrée REST OpenAPI :/series
Réponse à une liste de séries trouvées par des ID, appartenant potentiellement à différents fournisseurs et jeux de données.get_series_provider_code_dataset_code
URL d’entrée REST OpenAPI :/series/{provider_code}/{dataset_code}
Répondre à une liste de séries appartenant au même jeu de données.get_series_provider_code_dataset_code_series_code
URL d’entrée REST OpenAPI :/series/{code_provider}/{code_dataset}/{code_series}
Répondre à une liste de séries appartenant au même jeu de données.
Nous allons accéder à l’un des ensembles de données publiés. Rappelez-vous que vous n’avez pas besoin d’écrire la requête. Tous les champs sont disponibles dans le panneau de l’explorateur et il suffit de les sélectionner.
Il convient de commencer par lister les fournisseurs de DBnomics et d’obtenir leur code :
query dbnomics {
get_providers {
nb_datasets
nb_series
providers {
docs {
code
name
}
}
}
}Le résultat est :
{
"data": {
"get_providers": {
"nb_datasets": 22731,
"nb_series": 773075805,
"providers": {
"docs": [
...
{
"code": "OECD",
"name": "Organisation for Economic Co-operation and Development"
},
...
]
}
}
}
}Nous avons maintenant à notre disposition le code du fournisseur. Nous allons travailler avec l’organisation OCDE (Organisation de coopération et de développement économiques). La liste de ses jeux de données est obtenue avec le champ get_providers_provider_code. Nous remplissons le filtre provider_code (couleur violette) avec le code du fournisseur :
query dbnomics {
get_providers_provider_code(provider_code: "OECD") {
provider {
code
}
category_tree {
code
name
}
}Le résultat est :
{
"data": {
"get_providers_provider_code": {
"provider": {
"code": "OECD"
},
"category_tree": [
...
{
"code": "MEI",
"name": "Main Economic Indicators Publication"
},
...
]
}
}
}Il est intéressant de noter que la base de données DBnomics permet d’effectuer des recherches par mots-clés. Par exemple, en recherchant les mots-clés “OECD” (nom anglais de l’OCDE) :
query dbnomics {
get_search(q: "OECD", limit: 100) {
results {
docs {
provider_name
provider_code
code
nb_series
name
}
}
}
}Cela nous retourne :
{
"data": {
"get_search": {
"results": {
"docs": [
...
{
"provider_name": "Organisation for Economic Co-operation and Development",
"provider_code": "OECD",
"code": "MEI",
"nb_series": 102351,
"name": "Main Economic Indicators Publication"
},
...
]
}
}
}
}Nous choisissons de travailler avec l’ensemble de données MEI (Main Economic Indicators). Les noms des séries qu’il contient sont obtenus avec le champ get_series_provider_code_dataset_code :
query dbnomics {
get_series_provider_code_dataset_code(
dataset_code: "MEI"
provider_code: "OECD"
) {
series {
docs
}
}
}Dans notre cas :
{
"data": {
"get_series_provider_code_dataset_code": {
"series": {
"docs": [
...
{
"dataset_code": "MEI",
"dataset_name": "Main Economic Indicators Publication",
"dimensions": {
"FREQUENCY": "M",
"LOCATION": "A5M",
"MEASURE": "IXNSA",
"SUBJECT": "CSCICP03"
},
"indexed_at": "2021-03-21T10:05:12.520Z",
"provider_code": "OECD",
"series_code": "A5M.CSCICP03.IXNSA.M",
"series_name": "Major Five Asia – Consumer opinion surveys > Confidence indicators > Composite indicators > OECD Indicator – Normalised, seasonally adjusted (normal = 100) – Monthly"
},
...
]
}
}
}
}Pour obtenir l’ensemble des données finales, nous pourrions réutiliser le champ get_series_provider_code_dataset_code et ajouter les observations avec la valeur 1. Cependant, le résultat n’est filtré que par fournisseur et ensemble de données. Il n’est pas filtré sur une série particulière. Il s’agit d’une limitation liée à la manière dont les points de terminaison DBnomics OpenSchema sont définis et traduits. À la place, utilisons le champ get_series_provider_code_dataset_code_series_code. Ainsi pour obtenir les données de la série A5M.CSCICP03.IXNSA.M, la requête est :
query dbnomics {
get_series_provider_code_dataset_code_series_code(
dataset_code: "MEI"
provider_code: "OECD"
series_code: "A5M.CSCICP03.IXNSA.M"
observations: "1"
) {
series {
docs
}
}
}Et le résultat final devrait ressembler à :
{
"data": {
"get_series_provider_code_dataset_code_series_code": {
"series": {
"docs": [
{
"@frequency": "monthly",
"dataset_code": "MEI",
"dataset_name": "Main Economic Indicators Publication",
"dimensions": {
"FREQUENCY": "M",
"LOCATION": "A5M",
"MEASURE": "IXNSA",
"SUBJECT": "CSCICP03"
},
"indexed_at": "2021-03-21T10:05:12.520Z",
"period": [
...
"1990-02",
"1990-03",
"1990-04",
...
],
"period_start_day": [
...
"1990-02-01",
"1990-03-01",
"1990-04-01",
...
],
"provider_code": "OECD",
"series_code": "A5M.CSCICP03.IXNSA.M",
"series_name": "Major Five Asia – Consumer opinion surveys > Confidence indicators > Composite indicators > OECD Indicator – Normalised, seasonally adjusted (normal = 100) – Monthly",
"value": [
...
101.099027674524,
101.113378181641,
101.128369151665,
...
]
}
]
}
}
}
}Conclusion
La base de données DBnomics est désormais consultable avec GraphQL. Pour cela, nous avons exploité le schéma OpenAPI déjà existant et construit avec Swagger. Si vous avez des schémas existants dans votre organisation, vous savez maintenant comment les exposer rapidement avec GraphQL. Avec Apollo federation, il est possible de mélanger les deux points de terminaison de l’API Rest avec des points de terminaison GraphQL à l’aide d’un outil comme graphql-transform-federation. Comme illustré dans ce cas d’utilisation réel, il n’est pas parfait mais avec quelques modifications et compromis, il peut devenir très pratique.
