


Bridging the DBnomics Swagger/OpenAPI schema with GraphQL

By David WORMS
Apr 8, 2021
- Categories
- DevOps & SRE
- Front End
- Tags
- Data Engineering
- JAMstack
- GraphQL
- JavaScript
- Node.js
- REST
- Schema [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
While redacting a long and fastidious document today, I came across DBnomics, an open platform federating economic datasets. Browsing its website and APIs, I found their OpenAPI schema (aka Swagger). While browsing the schema, I kept a second tab open to download the datasets and preview the associated content. The process is not user-friendly nor developer-friendly. Discovering the schema on one side and looking at its associated content on the other side. Reading pretty-printed JSON on one side and downloading/extracting files on the other side. What if I could conveniently browse a schema and query its content. For a few years, there is a solution to this problem in the name of GraphQL. All I need is to convert the published OpenAPI schema into a GraphQL one. It shouldn’t take too long. More importantly, it provided me the distraction I was expected to find an excuse and to escape from my current task.
You can visit dbnomics.adaltas.com if your main interest is to browse the DBnomics data sources with GraphQL. You can start building your own queries or uncomment and tweak the available example queries.
Also, just directly to the last section Browsing the DBnomics API with GraphQL if you want to learn how the GraphQL queries are composed.
We invite you to read the rest of this article to gain insights into how we did it, how to integrate the source code yourself, and how to navigate the DBnomics API with some example queries. Here is the scope:
- Expose any OpenAPI schema with GraphiQL.
- Give DBnomics the UI it deserves to navigate its schema and datasets.
- Run a GraphQL query against an in-memory Graphql schema, no service side code involved.
- Create a React Component which does not depend on a local server nor a GraphQL endpoint, just the URL pointing to an OpenAPI schema.
- Learn how to browse, build and run GraphQL queries against the DBnomics database.
About GraphQL
GraphQL is great, I wrote about its main advantages over REST in the past and we use it on all our websites now with Gatsby.js and Next.js. I teach it to my students in Web Technologies courses. With it, I can plug a GraphQL web-based tool to browse the API and build queries interactively. GraphiQL is such a tool (note the i between Graph and QL). Gatsby.js websites ship natively with the /___graphql endpoint in development mode. In the UI of GraphiQL, the schema is browsable as a tree and all you need to do to build queries is to select the fields to return and the query filters. It is easy, it is quick, it requires no computing skills nor prior knowledge of the data model. Here is how it look for the Adaltas website schema:
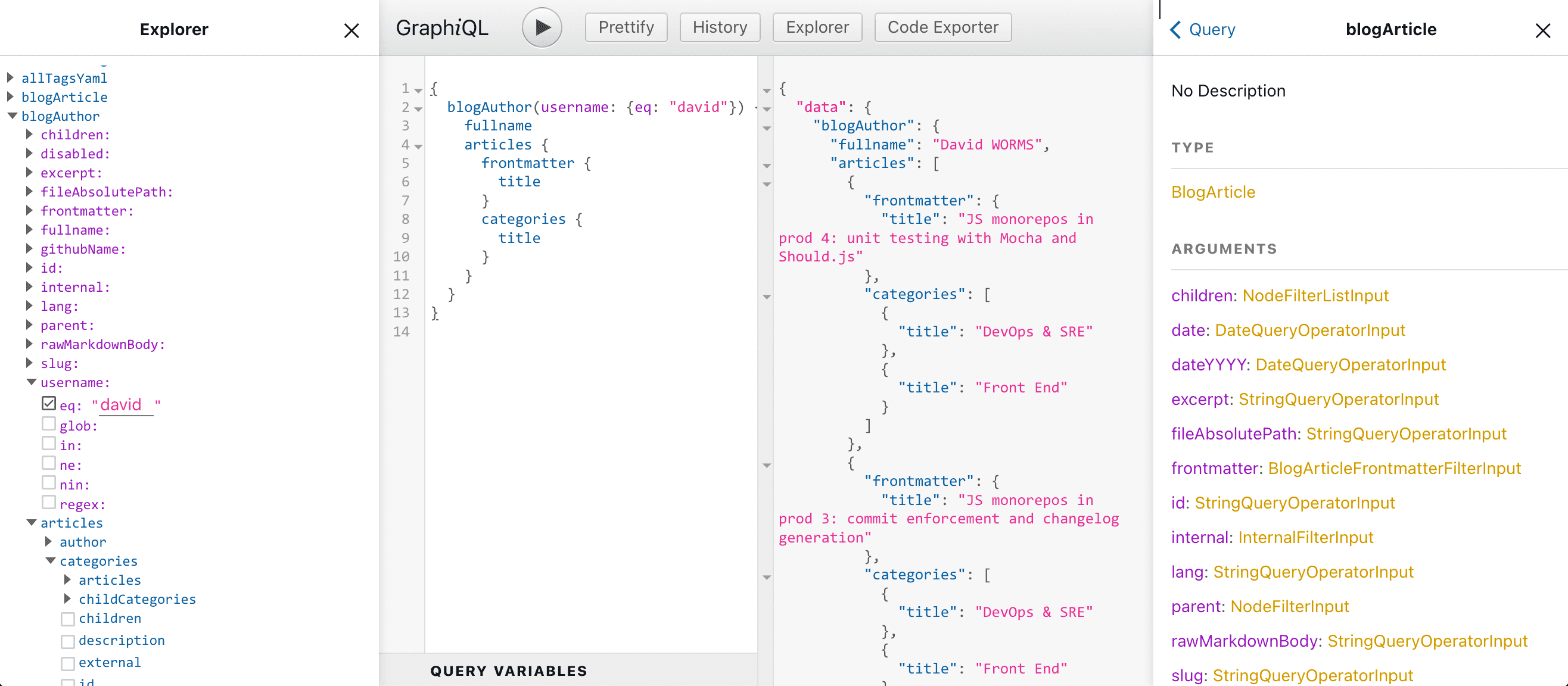
Let’s imagine I want to query articles and their categories for a particular author. I can browse the API in the documentation pane present on the right side. More conveniently, I leverage the explorer panel present on the left side. Using the Adaltas API, here is how to build a query. It starts by selecting the blogAuthor GraphQL type. On selection, the field expands with its associated filters (purple color) and fields (blue color). Fields describe an author or they resolve to another type of records. For example, the articles field map to another type named blogArticle with it own fields. An article is itself related to categories, another type called blogCategory in our case. Thus, records are connected between each other. This is where the term graph of GraphQL comes from. As more fields are selected in the explorer pane, the query is automatically built. It ends up looking like this:
{
blogAuthor(username: {eq: "david"}) {
fullname
articles {
frontmatter {
title
}
categories {
title
}
}
}
}Server-side bridge between GraphQL and OpenAPI
The DBnomics API is well documented and indicates the location of its OpenAPI schema. OpenAPI used to be called Swagger. Today, Open API is the specification while Swagger represents popular tools for implementing the OpenAPI specification. The package swagger-to-graphql is suited to convert it into a GraphQL schema. At first, I followed the instructions on their README file. It starts a Node.js HTTP server with Express.js and exposes the GraphiQL UI under the /graphql endpoint. It seems like it was all I needed. All I had to do was to implement the callBackend function which takes a few arguments and proxy them into the DBnomics REST API. In the end, I spent more time working around TypeScript than integrating the library. The final code is available on GitHub in the adaltas/demo-dbnomics-graphql project. A simplified version of it looks like this:
const app = express();
async function callBackend({
requestOptions: {path, query, headers, body, method},
}: CallBackendArguments<Request>) {
const baseUrl = "https://api.db.nomics.world/v22";
const url = `${baseUrl}${path}?${new URLSearchParams(query as Record<
string,
string
>)}`;
const response = await fetch(url, {
method,
headers: {
'Content-Type': 'application/json',
...headers,
},
body: body && JSON.stringify(body),
});
return JSON.parse(await response.text());
}
createSchema({
swaggerSchema: `https://api.db.nomics.world/v22/apispec_1.json`,
callBackend,
})
.then(schema => {
app.use(
'/graphql',
graphqlHTTP(() => {
return {
schema,
graphiql: true,
};
}),
);
app.listen(3009);
});And it worked. The server start and I can browse the UI from http://localhost:3009/graphql. However, I soon realized that I was missing a key component. The explorer pane which I cherish was gone. After some Googling, I realized that it is not part of GraphiQL but an external plugin named graphiql-explorer. After some research, my initial expectation to simply passing as a plugin argument of some sort was douched. This is when things got a bit harder.
Client-side bridge between GraphQL and OpenAPI
graphiql-explorer could not be registered as a plugin of GraphiQL. Instead, it must be plugged on the client-side. I had to manually wire them up, just like in the graphiql-explorer-example or in the Gatsby source code. I could no longer use my earliest code. In case you need it, it is available in the server branch of the adaltas/demo-dbnomics-graphql repository. Without going too much into the details, I ditched my current implementation, started a new React.js application with react-create-app, and imported the code from the GraphiQL sample application. It is the code present in the master branch of the adaltas/demo-dbnomics-graphql repository.
From my previous experience, I know how to convert the Swagger schema to a GraphQL schema and I converted the componentDidMount React function of graphiql-explorer-example to:
async componentDidMount() {
const schema = await createSchema({
swaggerSchema: `https://api.db.nomics.world/v22/apispec_1.json`,
callBackend,
})
this.setState({schema: schema})
}The last thing to do was to re-implement the fetcher function. The original code, like every documentation and sample I found on the Internet, is fetching the data from the GraphQL endpoint. In my case, there is no GraphQL endpoint. Instead, it must run the GraphQL query against the GraphQL schema loaded in memory. Everything happens in the client. I don’t need a server and I didn’t want to start one. Since it was not required, I choose to stick to the Jamstack architecture and I keep everything on the client. The data source server with the knowledge of the schema and the data it supports already exists, it is the DBnomics REST API. The final website available at dbnomics.adaltas.com is hosted on a serverless platform by Netlify.
It took some time to find how to do implement the fetcher function. In the end, I reversed engineered the Express.js Graphql middleware since that what it was doing, getting a query from the HTTP request and returning the data in the HTTP response.
The code looks like:
const fetcher = async ({query}, schema) => {
const documentAST = parse(new Source(query, 'GraphQL request'));
const result = await execute({
schema: schema,
document: documentAST,
});
return result;
}And it worked, the DBnomics API is now exposed with GraphQL. Anyone can interactively browse and discover the content it stores. The code is a React.js component that can be reused in your web applications.
Limitations of the OpenAPI DBnomics schema
There is however a limitation in the OpenAPI to GraphQL schema conversion. The DBnomics OpenAPI schema defines only a subset of the fields returned in the datasets. The issue includes all the endpoints starting with /series. The concerned path is .get.responses[200].schema.properties.series.properties.docs.items.properties. Only the dataset_code, provider_code and series_code are listed. Because GraphQL requires the return fields to be explicitly declared, there is no solution to access their associated data. This limitation proves to be problematic because it is precisely those fields that contain the data.
The solution I took is to patch the OpenAPI schema before converting it. The concerned property is declared as an object type, without declaring the properties it contains. Thus, all its properties are returned and not a subset of it. We loose the granularity of selecting which fields are returned but we at least get a hold of the content in the dataset. The rewritten componentDidMount function is now:
async componentDidMount() {
const swaggerSchemaReq = await fetch(`https://api.db.nomics.world/v22/apispec_1.json`)
const swaggerSchemaText = await swaggerSchemaReq.text();
const swaggerSchema = JSON.parse(swaggerSchemaText);
swaggerSchema.paths
["/series"]
.get.responses[200].schema.properties.series.properties.docs.items = {
type: 'object'
}
swaggerSchema.paths
["/series/{provider_code}/{dataset_code}"]
.get.responses[200].schema.properties.series.properties.docs.items = {
type: 'object'
}
swaggerSchema.paths
["/series/{provider_code}/{dataset_code}/{series_code}"]
.get.responses[200].schema.properties.series.properties.docs.items = {
type: 'object'
}
const schema = await createSchema({
swaggerSchema: swaggerSchema,
callBackend,
})
this.setState({schema: schema})
}Browsing the DBnomics API with GraphQL
The various REST endpoints are converted to GraphQL fields. Their name is accessible in the documentation and explorer panes:
get_datasets_provider_code
OpenAPI REST endpoint:/datasets/{provider_code}
Respond one or several datasets of a provider.get_datasets_provider_code_dataset_code
OpenAPI REST endpoint:/datasets/{provider_code}/{dataset_code}
Respond one or several datasets of a provider.get_last_updates
OpenAPI REST endpoint:/last-updates
Respond a list of providers and a list of datasets sorted by creation/conversion date, most recent first.get_providers
OpenAPI REST endpoint:/providers
Respond a list of providers.get_providers_provider_code
OpenAPI REST endpoint:/providers/{provider_code}
Respond a provider with its category tree.get_search
OpenAPI REST endpoint:/search
Respond a list of datasets from a full-text search.get_series
OpenAPI REST endpoint:/series
Respond a list of series found by IDs, belonging potentially to different providers and datasets.get_series_provider_code_dataset_code
OpenAPI REST endpoint:/series/{provider_code}/{dataset_code}
Respond a list of series belonging to the same dataset.get_series_provider_code_dataset_code_series_code
OpenAPI REST endpoint:/series/{provider_code}/{dataset_code}/{series_code}
Respond a list of series belonging to the same dataset.
We are going to gain access to one of the published datasets. Remember, you do not need to write the query. All the fields are available in the explorer panel and it is just a matter of selecting them.
It is appropriate to start by listing the DBnomics providers and to obtain their code:
query dbnomics {
get_providers {
nb_datasets
nb_series
providers {
docs {
code
name
}
}
}
}The result is:
{
"data": {
"get_providers": {
"nb_datasets": 22731,
"nb_series": 773075805,
"providers": {
"docs": [
...
{
"code": "OECD",
"name": "Organisation for Economic Co-operation and Development"
},
...
]
}
}
}
}We now have the provider code at our disposal. We will work with the OECD organization (Organisation for Economic Co-operation and Development). The list of its datasets is obtained with the get_providers_provider_code field. We fill the provider_code filter (purple color) with the provider code:
query dbnomics {
get_providers_provider_code(provider_code: "OECD") {
provider {
code
}
category_tree {
code
name
}
}
}The result is:
{
"data": {
"get_providers_provider_code": {
"provider": {
"code": "OECD"
},
"category_tree": [
...
{
"code": "MEI",
"name": "Main Economic Indicators Publication"
},
...
]
}
}
}Interestingly, the DBnomics database allows to search by keywords. For example, searching the “OECD” keywords:
query dbnomics {
get_search(q: "OECD", limit: 100) {
results {
docs {
provider_name
provider_code
code
nb_series
name
}
}
}
}Leads to:
{
"data": {
"get_search": {
"results": {
"docs": [
...
{
"provider_name": "Organisation for Economic Co-operation and Development",
"provider_code": "OECD",
"code": "MEI",
"nb_series": 102351,
"name": "Main Economic Indicators Publication"
},
...
]
}
}
}
}We choose to work with the MEI dataset which stands for Main Economic Indicators Publication. The names of the series it contains is obtained with the get_series_provider_code_dataset_code field:
query dbnomics {
get_series_provider_code_dataset_code(
dataset_code: "MEI"
provider_code: "OECD"
) {
series {
docs
}
}
}In our case:
{
"data": {
"get_series_provider_code_dataset_code": {
"series": {
"docs": [
...
{
"dataset_code": "MEI",
"dataset_name": "Main Economic Indicators Publication",
"dimensions": {
"FREQUENCY": "M",
"LOCATION": "A5M",
"MEASURE": "IXNSA",
"SUBJECT": "CSCICP03"
},
"indexed_at": "2021-03-21T10:05:12.520Z",
"provider_code": "OECD",
"series_code": "A5M.CSCICP03.IXNSA.M",
"series_name": "Major Five Asia – Consumer opinion surveys > Confidence indicators > Composite indicators > OECD Indicator – Normalised, seasonally adjusted (normal = 100) – Monthly"
},
...
]
}
}
}
}To obtain the final dataset, we could re-use the get_series_provider_code_dataset_code field and add the observations with the value 1. However, the result is only filtered by provider and dataset. It is not filtered to a particular series. This is a limitation of how the DBnomics OpenSchema endpoints are defined and translated. Instead, we use the get_series_provider_code_dataset_code_series_code field. To obtains the data of the A5M.CSCICP03.IXNSA.M series, the query is:
query dbnomics {
get_series_provider_code_dataset_code_series_code(
dataset_code: "MEI"
provider_code: "OECD"
series_code: "A5M.CSCICP03.IXNSA.M"
observations: "1"
) {
series {
docs
}
}
}And the final dataset looks like:
{
"data": {
"get_series_provider_code_dataset_code_series_code": {
"series": {
"docs": [
{
"@frequency": "monthly",
"dataset_code": "MEI",
"dataset_name": "Main Economic Indicators Publication",
"dimensions": {
"FREQUENCY": "M",
"LOCATION": "A5M",
"MEASURE": "IXNSA",
"SUBJECT": "CSCICP03"
},
"indexed_at": "2021-03-21T10:05:12.520Z",
"period": [
...
"1990-02",
"1990-03",
"1990-04",
...
],
"period_start_day": [
...
"1990-02-01",
"1990-03-01",
"1990-04-01",
...
],
"provider_code": "OECD",
"series_code": "A5M.CSCICP03.IXNSA.M",
"series_name": "Major Five Asia – Consumer opinion surveys > Confidence indicators > Composite indicators > OECD Indicator – Normalised, seasonally adjusted (normal = 100) – Monthly",
"value": [
...
101.099027674524,
101.113378181641,
101.128369151665,
...
]
}
]
}
}
}
}Conclusion
The DBnomics database is now browsable with GraphQL. For this, we leveraged its existing OpenAPI schema built with Swagger. If you have existing schemas in your organization, you now have a good idea of how to quickly expose it with GraphQL. With Apollo federation, it is possible to mix both Rest API endpoints with GraphQL endpoints using a tool like graphql-transform-federation. As illustrated with this real-life use case, it is not perfect but with a few quirks and compromise, it can become handy.
