


Plongée dans tdp-lib, le SDK en charge de la gestion de clusters TDP

24 janv. 2023
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Tous les déploiements TDP sont automatisés. Ansible y joue un rôle central. Avec la complexité grandissante de notre base logicielle, un nouveau système était nécessaire afin de s’affranchir des limitations d’Ansible, nous permettant de s’attaquer à de nouveaux challenges.
TDP est une plateforme big data 100% open source basée sur l’écosystème Hadoop. Alliage offre du support et de l’expertise sur TDP.
Limitations d’Ansible
L’orchestration n’est pas native à Ansible. Les primitives proposées par Ansible, telles que les handlers ou la sélection de tâches via les tags ne permettent pas une mise à l’échelle satisfaisante pour ordonnancer l’installation de services interdépendants.
Dans TDP, la principale manière de contrôler le déploiement est au travers de variables. Définir et versionner des variables dans Ansible est ardu. Il existe 22 endroits différents où définir des variables, et, au fur et à mesure que le projet grandit en complexité, il est difficile de suivre à quels endroits une variable peut-être définie ou redéfinie. De plus, cela peut mener à définir des valeurs par défaut en dehors de notre contrôle. Nous avons décidé d’ajouter un 23ème endroit pour permettre de les versionner facilement, ainsi qu’y ajouter des comportements personnalisés. Par dessus, nous avons développé des outils pour faciliter leur gestion.
TDP Lib
La réponse à ces besoins est tdp-lib. Ce SDK permet à des collections compatibles de définir un DAG (graphe orienté acyclique) contenant toutes les relations entre composants et services, détaillant l’ordre d’exécution des différentes tâches. De plus, tdp-lib permet de définir des variables par service ou par composant dans des fichiers yaml.
En se basant sur ces deux fonctionnalités, tdp-lib peut redémarrer le nombre de composants TDP minimaux nécessaires afin d’appliquer les changements de configuration.
N.B : tdp-lib ne remplace pas Ansible, il l’utilise en interne pour déployer TDP.
Roadmap TDP
L’écosystème TDP va de l’avant, et développe un ensemble d’outils afin d’aider à la gestion de cluster.
tdp-lib: SDK permettant d’implémenter les fonctionnalités cœures telles que le versionnement des variables ainsi que le déploiement à travers Ansible.
Status : Fonctionnalités cœures implémentéestdp-server: API REST qui utilisetdp-libpour déployer le cluster.
Status : Fonctionnalités cœures implémentéestdp-ui: Interface web fournissant une expérience utilisateur à l’état de l’art.
Status : En développement actiftdp-cli: Client en ligne de commande s’interfaçant avec letdp-server.
Status : Chantier non démarré
TDP : Définitions
Opérations
Une terminologie a été mise en place afin de définir précisément ce que TDP pouvait faire. Le concept à la base de TDP est une opération. Il y a deux types d’opérations, l’opération de service, ainsi que l’opération de composant. L’opération de service est composée de deux parties : le nom de service, ainsi que l’action (’service_action). Les opérations de services sont, en règle générale, des méta opérations (se traduisant en noop), utilisées à des fins de contraintes du DAG. Ensuite, les opérations de composant sont constituées de trois parties : le nom du service (ex : ZooKeeper), le nom du composant (ex : Server) ainsi que l’action (ex : install). Exemple : zookeeper_server_install.
En apprendre plus sur les opérations
Définition du DAG
Le DAG est défini par l’intermédiaire de fichiers YAML situés dans le dossier tdp_lib_dag d’une collection. Chaque fichier contient une liste de dictionnaires contenant les clés : name, noop (optionnel) et depends_on. Il est possible de n’utiliser qu’un seul fichier pour définir le DAG complètement, mais par convention, nous avons choisi de les séparer.
État actuel :
tdp_lib_dag/
├── exporter.yml
├── hadoop.yml
├── hbase.yml
├── hdfs.yml
├── hive.yml
├── knox.yml
├── ranger.yml
├── spark3.yml
├── spark.yml
├── yarn.yml
└── zookeeper.ymlÉchantillon d’une définition de DAG :
---
- name: zookeeper_server_install
depends_on: []
- name: zookeeper_install
noop: yes
depends_on:
- zookeeper_server_install
- zookeeper_client_install
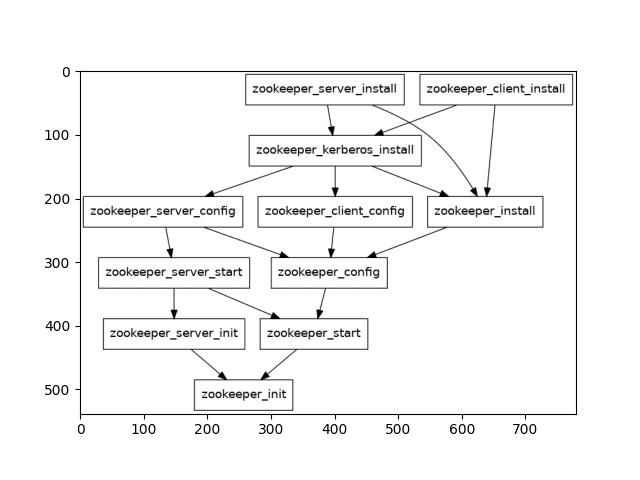
- zookeeper_kerberos_installVoici une représentation du DAG ne contenant que les noeuds ZooKeeper :
TDP vars
Comme décrit précédemment, utiliser des variables dans Ansible peut s’avérer facétieux. Dans les premières versions de TDP, nous utilisions des variables defaults définie à l’intérieur des rôles de la collection qui devaient êtres surchargés par des variables de groupe Ansible. Utiliser cette approche voulait dire que nous ne pouvions gérer toutes les variables depuis l’extérieur de la collection, ce qui veut dire une gestion plus ardue du versionnement, ainsi qu’une difficulté à offrir du contrôle à des outils externes. C’est là qu’entrent en jeu les TDP vars. Nous avons décidé de créer un endroit spécial où nous pouvions définir et gérer des variables. Cet endroit n’existe pas par défaut au clonage du dépôt Git à partir de GitHub. C’est une étape à effectuer à l’installation. La façon la plus commune d’initialiser ces variables sans utiliser la bibliothèque logicielle est de copier les fichiers depuis {collection_path}/tdp_vars_defaults vers l’inventaire (inventory/tdp_vars). La bibliothèque logicielle offre des fonctions d’initialisation effectuant toutes les étapes nécessaires.
Dans le dossier tdp_vars, les noms de dossiers ne comptent pas, seuls ceux des fichiers comptent. Le chargement des variables dans Ansible est effectué en deux étapes. Premièrement, à l’initialisation d’Ansible, les variables sont chargées par un plugin d’inventaire : tosit.tdp.inventory. Ce plugin charge tous les fichiers YAML présent dans l’arbre inventory/tdp_vars et les assignent au groupe all avec un préfix. Important, les variables ne sont pas résolues à cette étape : si l’on affiche leur contenu, on verra des templates Jinja. Par exemple, le fichier inventory/tdp_vars/hadoop/hadoop.yml sera chargé en tant que "TDP_AUTO_hadoop": {...valeurs}. Puis, au moment de l’exécution, les playbooks utilisent le plugin resolve afin de fusionner et résoudre les variables. Le plugin resolve prend en argument un nom de nœud composé du nom du service, ainsi que du nom du composant, à partir de cela, nous créons de l’héritage de variables.
Exemple : En définissant les fichiers de variables hdfs ainsi que hdfs_namenode chargera en premier lieu hdfs, puis surchargera ses valeurs par celles d’hdfs_namenode. Notez bien que cela ne s’applique que lorsque l’argument du plugin resolve est hdfs_namenode. Utiliser l’argument hdfs_datanode surchargera les variables hdfs par celles d’hdfs_datanode.
Les règles de priorités définies dans cet article s’appliquent toujours. Les TDP vars peuvent être considérées au niveau des défauts de rôle. Et donc, peuvent être surchargées par les variables de groupes et d’hôtes.
N.B : Un plugin d’inventaire est utilisé à la place d’un plugin de variables parce qu’il est impossible de charger un plugin de collection en Ansible 2.9.
Collections
Une collection est une entité contenant les trois dossiers suivants : tdp_lib_dag, tdp_vars_defaults et playbooks. Le dossier playbooks contient toutes les opérations disponibles dans la collection. Il n’est pas forcé qu’elles fassent partie du DAG. Les opérations en dehors du DAG sont appelées des actions spéciales (“special action” en anglais).
Plusieurs collections peuvent être utilisées en même temps, en fournissant une liste de collections à tdp-lib. Des règles spécifiques doivent être suivies :
- Des dépendances venant d’une autre collection peuvent être définies dans un DAG. L’autre collection devient alors requise.
- tdp-collection est considérée la collection principale, et ne peut donc pas dépendre d’une autre collection.
- L’ordre des collections fournies est utilisé pour surcharger les opérations ainsi que les variables. En fournissant l’ordre
[collection_a, collection_b]et que ces deux collections définissent le playbookzookeeper_init, la bibliothèque logicielle utilisera le playbook decollection_b. Pour les variables, la bibliothèque logicielle fusionnera (à l’initialisation seulement) les variables decollection_aetcollection_b, utilisantcollection_ben tant que surcharge. Utile, par exemple, pour définir des règlesauth_to_localglobalement.
Remarques finales
tdp-lib est une étape importante vers la gestion d’un cluster TDP, elle n’est pas destinée à être utilisée directement par les utilisateurs finaux, mais contient les fonctionnalités cœures nécessaires pour gérer un cluster TDP.
L’écosystème TDP avance rapidement, et beaucoup de fonctionnalités sont implémentées sur une base journalière, n’hésitez pas à participateer, les contributions sont les bienvenues !
