


Dive into tdp-lib, the SDK in charge of TDP cluster management

Jan 24, 2023
- Categories
- Big Data
- Infrastructure
- Tags
- Programming
- Ansible
- Hadoop
- Python
- TDP
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
All the deployments are automated and Ansible plays a central role. With the growing complexity of the code base, a new system was needed to overcome the Ansible limitations which will enable us to tackle new challenges.
TDP is an 100% open source big data platform based on the Hadoop ecosystem. Alliage offers support and professional services on TDP.
Ansible limitations
Scheduling in Ansible is not easy. Having a task triggered at the end of another (thanks to handlers) or selecting the different tasks to be executed according to the need (thanks to tags) does not scale.
In TDP, the main way to control the deployment is through variables. Defining and versioning variables in Ansible is an easy way to complicate your life, there’s currently 22 different locations where you can define variables and as the project grows in complexity, it is difficult to keep track of where each variable is defined or re-defined. Moreover it can sometimes lead to defining defaults outside our control. We decided to add a 23rd way to easily version, and add custom behavior. We had to develop the necessary tools to correctly version these variables.
TDP Lib
The answer to these two requirements is tdp-lib. This SDK allows compatible collections to define a DAG (directed acyclic graph) containing all the relationships between components and services, detailing the execution order of the tasks. Moreover, it allows the definition of variables per service and per component in yaml files.
Based on these two features, tdp-lib is able to restart the minimal number of components of the TDP stack to apply configuration changes.
N.B: tdp-lib does not replace ansible, it uses ansible internally to deploy TDP
TDP Roadmap
The TDP ecosystem is moving forward, and developping a set of tool to help manage cluster deployment.
- tdp-lib: project which role is to implement core features such as variable versioning and deployment with ansible, status: Main features implemented
- tdp-server: REST Api using tdp-lib to deploy the managed cluster, status: Main features implemented
- tdp-ui: Web interface to provide top notch user experience to users, status: In active development
- tdp-cli: client in command line interface to interact with tdp-server, status: Not yet started
TDP Definitions
Operations
A terminology has been defined to be able to precisely define what TDP can and cannot do. The base concept of TDP is an operation. There are two types of operations, the service operation and the component operations. A service operation is made of two parts: the service name, and the action name (service_action). Service operations are often meta operations (translating into noops), meant to schedule component operation inside the service. Then, there are the component operations. They are composed of three parts: the service name (ie. ZooKeeper), the component name (ie. Server), and the action name (ie. install). Example: zookeeper_server_install.
DAG definition
The DAG is defined using YAML files located inside the folder tdp_lib_dag of a collection (defined later). Each file is a list of dict containing the keys: name, noop (optional), and depends_on. It is possible to use only one file to define every dag nodes, but as a convention, we separate them.
Current state:
tdp_lib_dag/
├── exporter.yml
├── hadoop.yml
├── hbase.yml
├── hdfs.yml
├── hive.yml
├── knox.yml
├── ranger.yml
├── spark3.yml
├── spark.yml
├── yarn.yml
└── zookeeper.ymlSample of a service definition:
---
- name: zookeeper_server_install
depends_on: []
- name: zookeeper_install
noop: yes
depends_on:
- zookeeper_server_install
- zookeeper_client_install
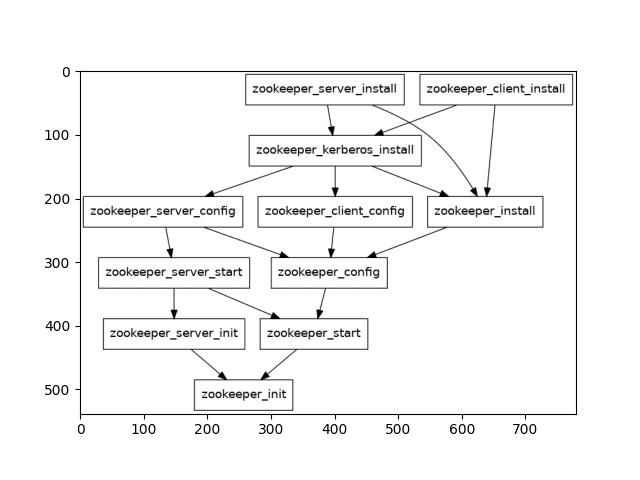
- zookeeper_kerberos_installHere’s an example of a dag containing only the zookeeper nodes:
TDP Vars
As said earlier, using variables in ansible is tricky. In the early TDP versions, we were using defaults variables inside the collections’ roles that had to be overridden using Ansible’s group variables. Using this approch meant we couldn’t possibly manage all the values from outside a collection, meaning having a hard time versioning and offer control to outside tools. This is where the TDP Vars come in. We decided to create a special place where we could define and manage variables. This location does not exist when cloning the collections from github. This is a step you need to perform at installation time. The most common way to do it when you’re not using the library is to copy the variables from {collection_path}/tdp_vars_defaults into your inventory (inventory/tdp_vars). Using the library, there are initialization functions allowing you to perform this necessary step.
In the folder tdp_vars, the folder names do not matter, only the variable files do. The variable loading in Ansible is performed in two steps. First, at Ansible initialization time, the variable are loaded by an inventory plugin: tosit.tdp.inventory. This plugin loads every YAML file in the tree inventory/tdp_vars and puts them in the group vars all as keys with a prefix. Important, variable are not resolved at this stage, if you look at their content, you will see the jinja templates. For example, the file inventory/tdp_vars/hadoop/hadoop.yml will be loaded as "TDP_AUTO_hadoop": {...values}. Then, come the running time, where playbooks need to use the plugin resolve, that will merge and then resolve the variables. The resolve plugin takes an argument which is the service + component name that’s used to create variable inheritance.
Example: Defining the variables files hdfs and hdfs_namenode will load hdfs first, and then override it with the values from hdfs_namenode. Note that this applies only when the argument to the resolve plugin is hdfs_namenode. Using the argument hdfs_datanode will override the hdfs variables with values from hdfs_datanode.
The precedence rules defined in this article still applies. The tdp vars can be considered to be at the role defaults level. And thus, can be overriden by group vars or host vars.
N.B: An inventory plugin is used instead of a vars plugin because you cannot use vars plugin from a collection in Ansible 2.9.
Collections
A collection is an entity containing three folders: tdp_lib_dag, tdp_vars_defaults, and playbooks. The playbooks folder contains all the operations available in the collection, they don’t have to be a part of the DAG. Operations outside of the dag are called special actions.
Multiple collections can be used at the same time by tdp-lib by providing a list of collections. There are specific rules and behaviors defined as follow:
- You can define dependencies in the DAG from another collection, but the other collection becomes required
- tdp-collection, is considered the main collection, and therefore, cannot depend on another collection
- The order the collection is provided is used to override operations and variables. If you give the collections in the order
[collection_a, collection_b]and they both define the playbookzookeeper_init, the library will use the playbook fromcollection_b. For variables, the library will merge (at initialization time only) the variables fromcollection_aandcollection_b, usingcollection_bas override. (Useful to addauth_to_localrules globally for example)
Closing remarks
TDP-lib is an important step towards managing a TDP cluster, it’s not meant to be used directly by users, but holds the core features of what’s needed to manage a TDP cluster.
TDP ecosystem is moving fast, and lots of features are implemented on the day-to-day, don’t hesitate to participate, contributions are welcome!
