Oracle DB synchrnozation to Hadoop with CDC

By David WORMS
Jul 13, 2017
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
This note is the result of a discussion about the synchronization of data written in a database to a warehouse stored in Hadoop. Thanks to Claude Daub from GFI who wrote it and who authorizes us to publish it.
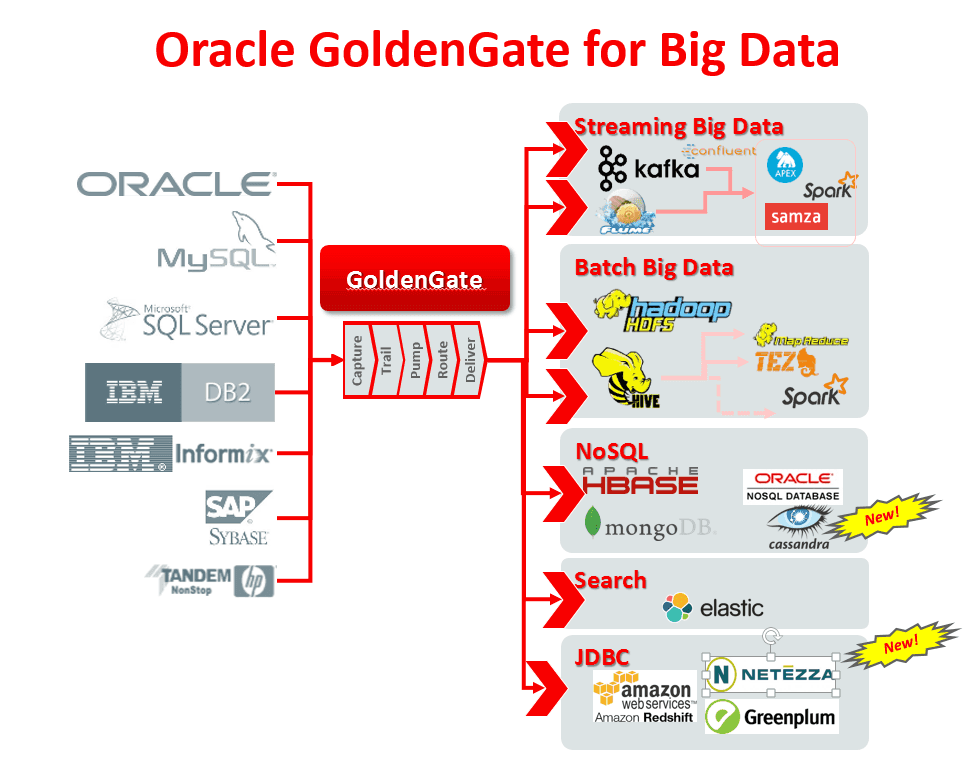
Oracle GoldenGate
- Real-time data replication tool based on internal logs
- Distributed and therefore officially supported by Oracle
- No impact on the performance of the source database
- Wide range of destinations: HDFS, Kafka, HBase, Hive, Flumes, JDBC, …
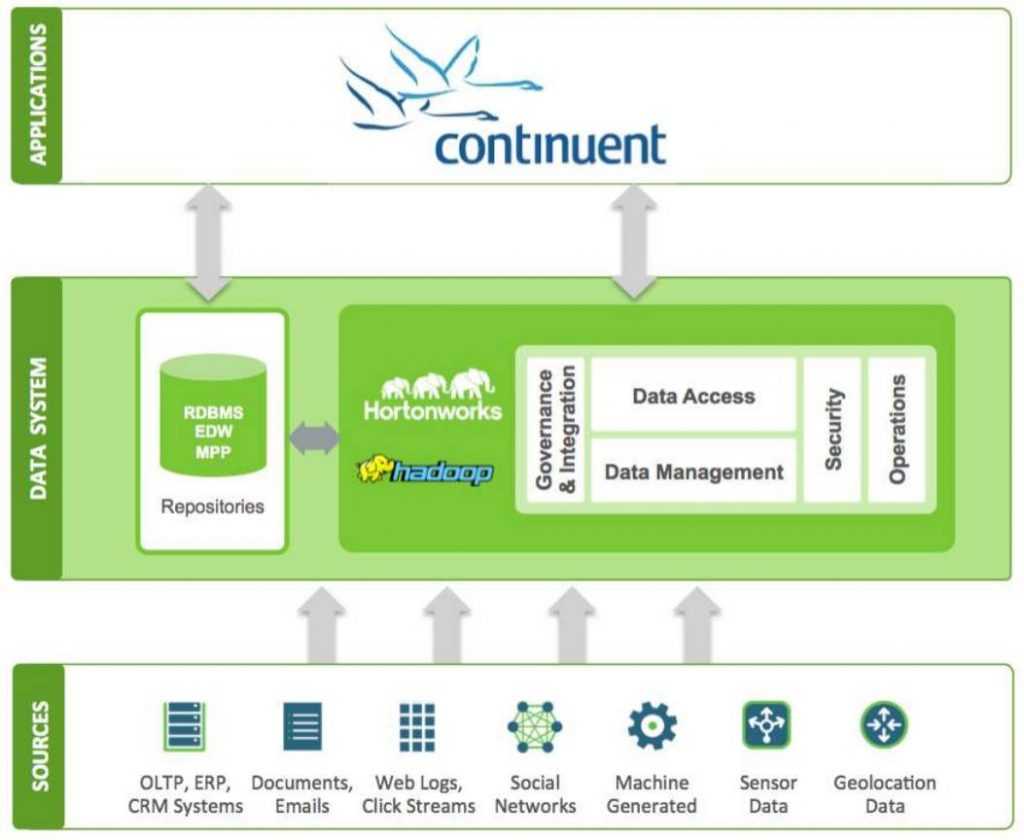
Continuent Tungsten Replicator
Tungsten connect to Oracle CDC (Change Data Capture) which retrieves the changes from the redo logs. It produces other tables with the changes.
This solution allows deferred processing, but uses, as with triggers, intermediate tables. The sync method with Hadoop is adaptable (Sqoop can suffice) or a CSV export / import via file.
It integrates a data replication service:
- Compatible with several databases (Oracle, MySQL …)
- We can have time series
- Hortonworks Certified Solution
- No information on the impact on performance on the source
DBVisit
Commercial solution with:
- Real time
- Support of several RDBMS (Oracle, MySQL)
- Bidirectional replication possible.
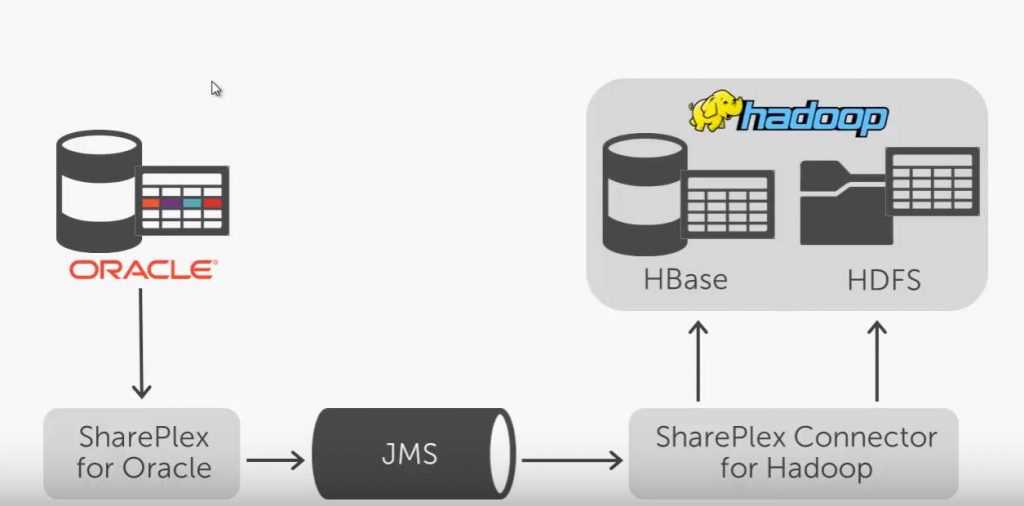
Share Plex of Quest Software
- Is based on redo logs => Concerns Oracle
- The identified changes are buffered in a JMS queue and then stored in HDFS / Hbase.
- See https://www.youtube.com/watch?v=JuWB5HfYjJ