


Deploying a secured Flink cluster on Kubernetes

By David WORMS
Oct 8, 2018
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
When deploying secured Flink applications inside Kubernetes, you are faced with two choices. Assuming your Kubernetes is secure, you may rely on the underlying platform or rely on Flink native solutions to secure your application from the inside. Note, those two solutions are not mutually exclusive.
Relying on Kubernetes native security
Kubernetes definition templates for Flink are available online and provide a reliable starting point. The JobManager deployment maintains 1 replica. Kubernetes is in charge of redeployment in case of failure.
Network isolation
By default, all Pods in a cluster may communicate freely with each other. Said differently, when a Pod is started, it is assigned a unique IP which is accessible from by the other Pods. By using Network Policies, you can isolate the services running in Pods from each other. A network policy is a set of network traffic rules applied to a given group of Pods in a Kubernetes cluster. You can restrict the access within a namespace or for the Pods which constitute an application. With Network Policies enforced, your application will be isolated from the outside world.
Encryption and authentication
However, the communications internal to the cluster will be sent as is, the same applies to the outside world, and you are left with no authentication. To encrypt all communications with SSL, you may then introduce a service mesh like Istio which will deploy quite transparently while providing additional benefits you may, or may not need including load balancing, monitoring or resiliency features (retry, timeout, deadlines, …). The usage of a service mesh is particularly attractive when your application runs on a zero-trust network.
Also, access to the application from the outside provides no authentication and you are left with the requirement to provide a service to authenticate accesses, which may also be implemented with a service mesh solution, or deny all external and direct access your application and deploy a trusted Pod in charge of proxying the communications.
The latest is similar to the approach described by Marc Rooding and Niels Dennissen from ING in their talk Automating Flink Deployments to Kubernetes where the CD/CI chain pushed deployment instructions and resources to a trusted Pod deployed along their Flink application.
Relying on Flink native security features
In the second approach, Edward Alexander Rojas Clavijo presented in hist talk Deploying a secured Flink cluster on Kubernetes how to integrated with Flink native solutions. While fairly straightforward in a Hadoop YARN environment, both SSL and Kerberos present some challenges due to the dynamic nature of the IP and DNS assignment inside a Kubernetes cluster.
Architecture
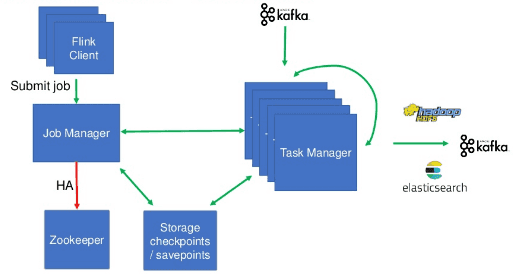
The architecture described below involves Kafka as a source and a sink as well as HDFS and Elasticsearch as sinks.
The JobManager service uses a dedicated hostname which can be referenced by the TaskManagers instances as well as the job submissions scripts. To each individual TaskManager is assigned a Pod. The number of containers is aligned with the number of jobs which are endless and stateful. On update, the TaskManager deploy a checkpoint.
ConfigMap are used to generate the Flink configuration including memory and checkpoints managements.
Guaranty secured communication with SSL
By default, every communication in Flink between the JobManager and the TaskManagers is performing hostname validation. The traditional approach to generating public and private certificates for each component is hard to integrate with dynamic IP and hostnames. It implies contacting a PKI server to generate the certificate on the container startup before the Flink component has started.
In their first iteration, the team used wildcard certificates.
It starts with the registration of a service resource for the JobManager. Kubertenetes service gets a fixed hostname and communications are routed to the Pod by Kubernetes.
The taskManagers rely on stateful set definitions. Stateful Set provides a predicated hostname. For example, the FQDN flink-tm-0.flink-tm-svc.namesapce.cluster.local defines the TaskManager instance flink-tm-0 inside the service flink-tm-svc inside the namespace namespace. Isolating all the TaskManagers inside a single domain name makes it possible to generate a wildcard certificate available to the TaskManager.
In the Pods performing job submissions, the CLI is not configured to perform hostname validation. The certificate authority must be trusted by the JobManager.
The limitation of using wildcard certificates is that it restrains the deployment of the Flink application to a single namespace. Deployment to a new namespace means generating a new certificate.
The final solution which was selected consists of generating one single purpose certificate pushed to the Truststores and Keystores with certificates and hostname validation being deactivated.
Starting with version 1.6, Flink can perform mutual validation which respects the recommended approach for Kubernetes. The content and password of the Truststores and Keystores are exposed as a Kubernetes secret, which is base64 encoded and mounted into the Pods.
Communication with sources and sinks
In the presented architecture, the Flink application is communicating with Kafka, HDFS, and Elasticsearch.
To enable Kerberos authentication between to Flink components, it is required to provide access to the Keytab files from every component. A secret contains the file encoded as base64 which is exposed to every Pod. The ConfigMap is used to send the Kerberos properties such as the service principals.
The Kafka security protocol is SASL_PLAINTEXT and it requires the Kerberos service name provided by the ConfigMap.
The various SSL certificates of the source and sink services are exposed as secrets which are mounted on Pods. The DockerFile definition mounts and ensures access right to $JAVA_HOME/lib/security/cacerts which contains the required Certificate Authorities.
The Elasticsearch endpoint is accessed through REST requests. They created a custom sink because Flink prior to version 1.6 is incompatible with Elasticsearch in version 6. In their custom HTTP client, the SSL hostname verifier was invalidated.
Communication between the Flink TaskManager and the Kubernetes Physical Volume
The Flink state is persisted using a Physical Volume exposing an NFS server. Because the NFS is not capable of encrypting the data, encryption is handled at the application level. This answer the requirement of in-flight and at-rest (not supported natively by NFS) encryption.
What’s next
The talk ended on the future actions to improve the security of the system:
They include enforcing Kubernetes security config:
– use RBAC
– Restrict access to kubectl
– Use Network Policy
– Pod security Policy
As well as using the Job Cluster Container Entrypoint present in Flink 1.6 which embed both the Flink runtime and the user application inside a container.
