


Apache Flink: past, present and future

Nov 5, 2018
- Categories
- Data Engineering
- Tags
- Pipeline
- Flink
- Kubernetes
- Machine Learning
- SQL
- Streaming [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Apache Flink is a little gem which deserves a lot more attention. Let’s dive into Flink’s past, its current state and the future it is heading to by following the keynotes and presentations at Flink Forward 2018.
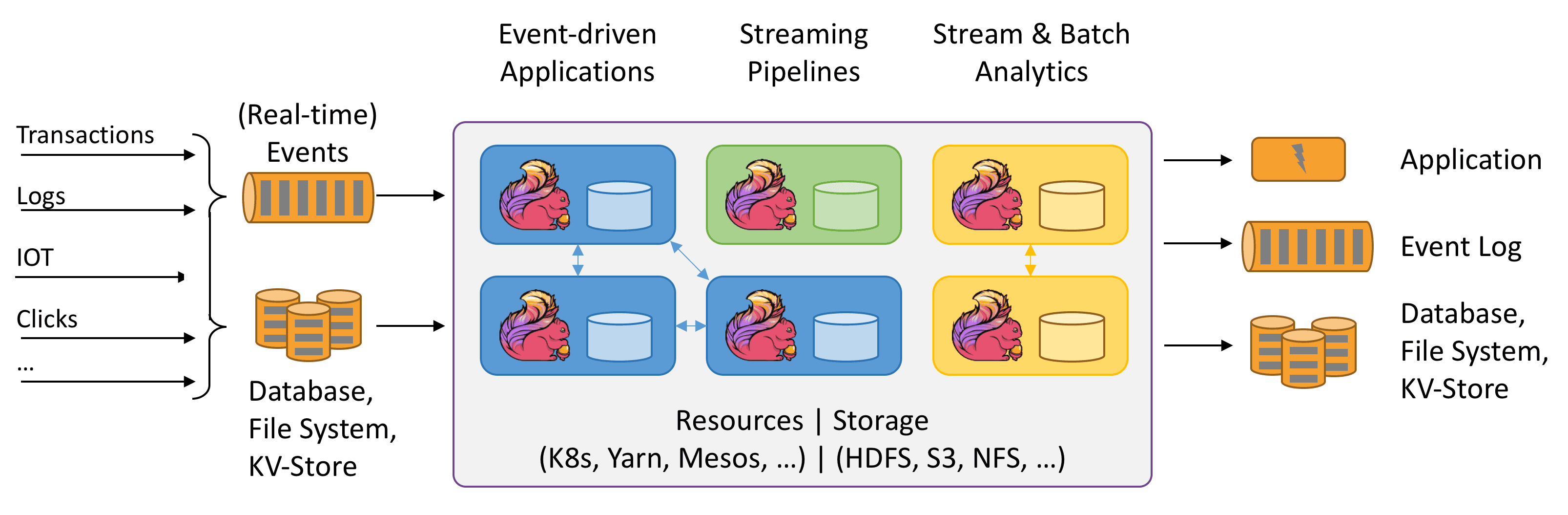
Apache Flink is an in memory streaming engine. It provides the foundation and the main building blocks to allow stateful computation over data streams between multiple sources and sinks and on various platforms:
Past
It all started in August 2014 when Flink 0.6.0 was released as a Batch Processor on top of a streaming runtime. Before that, it was named StratoSphere and started in 2009 as an academic research project in Berlin’s Technical University.
Version 0.6 exposed the DataStream (streaming) and DataSet (batch) APIs on top of a common pipelined streaming processing engine. It means that operators do not wait for their predecessors to finish in order to start processing data. It results in a very efficient engine capable of handling large data sets and with a better memory handling. Batch is thus treated as a special case of streaming where the streams are bounded (finite).
Flink then acquires over time multiple skills to enhance the streaming experience.
Exactly-once Fault Tolerance
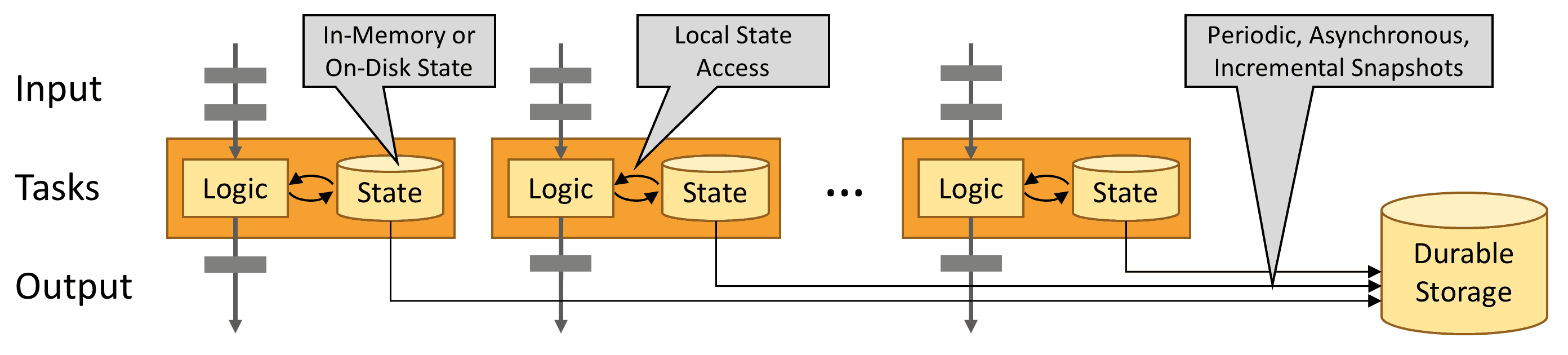
API 0.9 introduced the concept of states and allowed the creation of a new wave of applications able to remember incoming things. Indeed, for stateless jobs it was easy to handle fault: just retry on the failed data. However it gets more complicated for long running distributed stateful jobs, you have to re-initialize the state. Flink learned to remember with the introduction of continuous snapshots to recover and resume state.
However Flink does streaming, and snapshots involve taking a full picture at an instant and persisting it to storage. And snapshots usually take resources and slow down computing. To tackle this challenge, data Artisans implemented asynchronous snapshotting with stream barriers:

Barrier messages are injected into the stream, splitting it into messages batches, and once the barrier reaches an operator, a snapshot is created with the messages batch part of the checkpoint. Flink also has mechanisms to handle merged streams and states snapshotting.
Upon failure, Flink selects the latest completed checkpoint, it redeploys the entire distributed dataflow with the states that were snapshotted as part of this checkpoint and it re-starts the sources from the position of the checkpoint.
This snapshotting process allows high throughput and low latency streaming.
SQL and Machine Learning
API 0.9 also introduced three new modules:
- Flink SQL and the Table API adds a higher level of abstraction on structured data sources allowing users to execute SQL-like queries on both batch and streaming distributed datasets.
- Gelly Graph processing API contains an utility set for graph analysis that wraps datasets for vertices and edges to apply graph algorithms.
- Machine Learning library inspired from scikit-learn’s abstraction of transformers and predictors makes it easy to setup data processing pipelines for machine learning with multiple existing algorithms.
Those three modules brought Flink to the level of its competitor, Apache Spark.
Timekeeping
Event time support came with Flink 0.10. Messages could now be processed in the order they were emitted as long as they had a timestamp. Such datasets include logs, financial transaction and sensor data.
Very often, events are collected from several sources. It is usually not guaranteed that events arrive in the exact order of their timestamps into the stream processor. Consequently, stream processors must take out-of-order elements into account in order to produce results which are correct and consistent with respect to the timestamps of the events.
Flink learned to understand event-time processing as well as ingestion-time and processing-time processing. For example, taking the Star Wars movie series, Flink can process them in different orders:
- Processing-time: as they were created: first the originals (4, 5, 6), then the prequels (1, 2, 3), rogue one, and then the new trilogy (7, 8 and 9 to come)
- Event-time: defined by their numbering, prequels, rogue one, originals and finally the new trilogy
Present
This all brings us to a processing engine with the following properties:
- Continuous & real-time
- Stateful & exactly-once
- High throughput & low latency
- Event time & process functions
and multiple levels of abstraction:

It is now possible to develop data-driven applications:
- Modelize and automate all the processes, problems and opportunities
- Operate in realtime on multi-channel data sources (and sinks)
- Consume all variety of datasets, structured, semi-structured and unstructured
- Information is universally exposed within a single application
- Seamlessly combines operational / OLTP and analytic / OLAP capabilities
- Event-driven, react to environmental changes
Version 1.x iterated on top of those existing features up to the current 1.6:
- Incremental snapshotting allows to record larger states by storing only the diff. On recovery, operators start with the latest full snapshot and then re-apply the incremental snapshot updates.
- Local recovery keeps a copy of a snapshot locally on the Flink node (TaskManager) to handle node failure, instead of relying only on a slower storage backend.
- Resource elasticity makes Flink able to react to cluster resource availability by scaling accordingly.
- Flink as a library, and not just a framework, makes deploying an app as easy as starting a process with the application code and Flink sources bundled together.
- Flink SQL was drastically improved up to supporting unified sources and sink definition in YAML, which allows user to run a SQL job with just YAML configuration and a SQL query through the SQL client CLI, no coding skills required.
- Flink is Hadoop-free and supports more and more platforms and technologies including Kubernetes.
Future
Streaming and batch convergence
In Flink’s contexts, the current API expose batch and streaming as different side-by-side abstractions whereas SQL allows to have a unified semantic on stream and batch inputs.
Flink is heading on a convergence for both batch and stream processing, today through SQL apis and tomorrow hopefully with the Java and others APIs.
One very interesting project to notice on this subject is Alibaba’s Blink, a fork of Flink’s internal using Flink SQL to seamlessly process batch and stream.
SQL pattern detection
The SQL API already supports a lot of features. data Artisans is currently working on supporting pattern detection over streams with SQL using the MATCH_RECOGNIZE clause.
It allows to handle common use-cases such as stock market analysis, customer behaviour, tracking money laundering, service quality checking, network intrusion detection, …
Let’s take a practical example. We have an incoming stream of messages on taxi rides with multiple informations, including a unique ride ID and an indicator if the message is the start of a ride. We want to do some pattern matching and retrieve all the rides with mid-stops.
It would be over complicated to implement with existing SQL features, even on a fixed dataset. Here’s how we would select rides with mid-stops with MATCH_RECOGNIZE:
SELECT *
FROM TaxiRides
MATCH_RECOGNIZE (
-- specify grouping key
PARTITION BY driverId
-- specify ordering
ORDER BY rowTime
-- Extract measures from matched sequence
MEASURES S.rideId as sRideId
AFTER MATCH SKIP PAST LAST ROW
-- Construct pattern
PATTERN (S E)
DEFINE S AS S.isStart = true, E AS E.isStart = true
)And with multiple stops:
-- Set M as appearing at least twice
PATTERN (S M{2,} E)
DEFINE S AS S.isStart = true, M AS M.rideId <> S.rideId, E AS E.isStart = false AND E.rideId = S.rideId
)At the time of this writing, the feature was experimental and was hosted on a now defunct GitHub repository. You can read more about detecting patterns in tables on the Flink website.
Shared state consistency
Flink Forward was the time for data Artisans to announce a new game-changing feature for streaming application: the Streaming Ledger.
In a world where consistency is absolutely essential and you have to be able to forget what you know (RGPD!), it is impossible to maintain over stream processors. We would need to be able to:
- Access and update states with multiple keys at the same time.
- Maintain full isolation / correctness for the multi-key operations.
- Operate on multiple states at the same time.
- Share the states between multiple streams.
The Streaming Ledger system provides ACID guarantees across multiple states, rows and streams. It is an autonomous library integrating seamlessly with Flink’s DataStream API and SQL assuring Atomicity, Consistency, Isolation and Durability.
It is not an embedded relational database, as it would be a way of repackaging existing architectures and wouldn’t answer the users needs. It rather uses a more unique approach:
- Event re-ordering & out of order processing
- Iterative streaming dataflows
- Logical clocks for scheduling
which translates into re-scheduling events to avoid conflicts when persisting them.
We encourage you to read the Streaming Ledger whitepaper to understand more of the internal concepts.
In terms of performances, the given numbers from this early first version were pretty impressive (counting in multiple hundred thousands to millions of events per seconds) and will surely get better.
A short demonstration showed a distributed setup coordinating transactions between Europe, Brazil, the US, Australia and Japan at around 20K/updates per second. Of course, as distributed systems rely heavily on network latency, distance takes a toll on performance.
The only unfortunate point is that right now the ledger is only available as a library on the data Artisans platform, or under Apache 2.0 license in single-node mode for local development and testing.
A world of microservices
If we take a step back, we can look at the history of data processing as following:
- First came in offline batch processing, manually launch, usually single node
- Then he had Big Data with map/reduce distributed processing
- And finally the lambda architecture, trying to solve the latency issue of map/reduce to treat the last events
and multiple steps in services:
- Client-server
- CORBA & DCOM
- EJB & N-Tier architecture (N being 3)
- SOA & ESB
- HTTP-API & REST
Today, we are coming up to live (near real-time) stream processing and microservices architecture. We are observing a convergence of the two different subjects:
- Reactive systems need to be available (responsive) under failure (resilience) and under load (elasticity) by message-driven.
- Reactive streams provide a standard for asynchronous stream with non-blocking backpressure.
The next step would be to lift the service into a stream stage, input Events into commands and to capture responses and convert them into output events, thus deriving microservices from data streams:
- Microservices would be part of a streaming pipeline.
- A pipeline could be exposed as microservices.
- We could independently upgrade parts of the pipeline.
Flink is already able to handle this, we only need to shift our perspective.
Conclusion
We now have a good overview of Apache Flink. It’s already a fully matured platform and framework for data-driven application and is heading in to become the de facto standard of evented data-driven applications.
Further reading
Flink Forward presentations:
- “The Past, Present and Future of Apache Flink” by Aljoscha Krettek (data Artisans) and Till Rohrmann (data Artisans)
- “Unified Engine for Data Processing and AI” by Xiaowei Jiang (Alibaba)
- “Detecting Patterns in Event Streams with Flink SQL”, Dawid Wysakowicz, (data Artisans)
- “Unlocking the next wave of Streaming Applications” by Stephan Ewen (data Artisans)
- “The convergence of stream processing and microservice architecture” by Viktor Lang (Lightbend)
Links:
- Flink Forward Berlin 2018: https://berlin-2018.flink-forward.org
- Cover photo by Sven Fischer on Unsplash
- StratoSphere: http://stratosphere.eu/
- All in-text images courtesy of Flink’s website: https://flink.apache.org/
- Alibaba’s Blink: https://data-artisans.com/blog/blink-flink-alibaba-search
- Flink SQL features: https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/sql.html#supported-syntax
- Streaming ledger: https://data-artisans.com/streaming-ledger
- Streaming ledger whitepaper: https://www.ververica.com/download-the-ververica-streaming-ledger-whitepaper
- Apache 2.0 license: https://www.apache.org/licenses/LICENSE-2.0
- Reactive systems manifesto: https://www.reactivemanifesto.org/
- Reactive streams initiative: http://www.reactive-streams.org/
