


Jumbo, the Hadoop cluster bootstrapper

Nov 29, 2018
- Categories
- Infrastructure
- Tags
- Ambari
- Automation
- Ansible
- Cluster
- Vagrant
- HDP
- REST [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Introducing Jumbo, a Hadoop cluster bootstrapper for developers.
Jumbo helps you deploy development environments for Big Data technologies. It takes a few minutes to get a custom virtualized Hadoop cluster up and running, with all the technologies you need to install.
Let’s go through the motivation that led us to develop Jumbo, how it works and why you might be interested in using it.
How is Jumbo born?
At Adaltas, we work with Big Data technologies. To provide the best service to our customers, we need to test new tools and new architectures every day. For that, we need to be able to create virtual environments and to provision them rapidly.
We already use a very nice tool written in Node.js called Ryba to manage big multi-tenant clusters, with a fine-grained tuning of every installed service. But while it is perfect for production environments, Ryba was not built to quickly bootstrap clusters on virtual machines. This requires a knowledge of both Node.js and Ryba, so it takes time to configure each new cluster.
That’s why we decided to start a new project from scratch, with the idea of simplicity in mind: an easy to use maintainable tool that allows creating basic clusters quickly.
Virtual machines
First, we needed a way to manage the virtual machines that would act as the cluster’s nodes. We chose to use Vagrant for its easy way to configure VMs with a single Ruby file. You will soon be able to use remote virtual clusters, and plug in Jumbo to them.
VMs configuration and provisioning
We also needed to automate the configuration and the deployment of Big Data services on the VMs. To achieve this, Ansible was picked, because its playbooks written in YAML offer a great readability and are therefore handy to maintain. To handle the Hadoop ecosystem services installation, we selected Apache Ambari and Hortonworks Data Platform (HDP). Ambari offers a way to precisely describe the topology of the Hadoop cluster either with its API or with its web UI, and handles all the installations for us.
Python tool
Finally, to glue all these tools together, we developed a Python software that exposes a simple interface to the user (a CLI) and generates all the configurations files needed for the tools mentioned above. We named this project Jumbo, after Dumbo’s mother (your Hadoop cluster is a little elephant needing help to start its life).
How does it work?
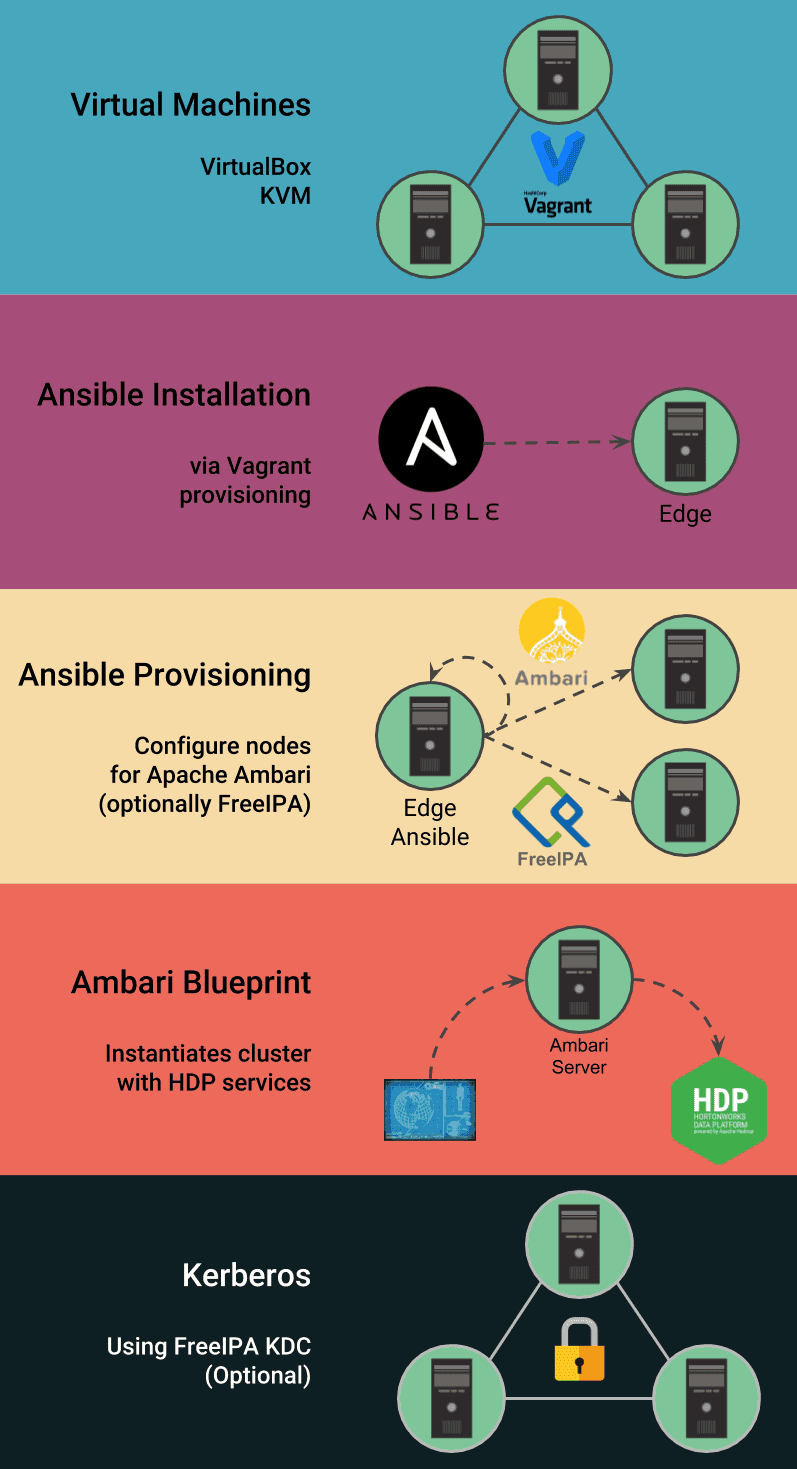
Jumbo generates all the configuration files to leverage the following technologies:
- Vagrant: to instantiate virtual machines and provisions Ansible on one of them;
- Ansible: to provision Ambari and its requirements, as well as FreeIPA/Kerberos (optional). It uses Ambari API for blueprints and services control;
- Ambari Blueprints: to describe the cluster’s topology and launch the HDP services installation through Apache Ambari API;
- FreeIPA (optional): to secure the cluster (LDAP and Kerberos);
What does Jumbo look like?
Jumbo is an Open Source software written in Python. It comes with a CLI and offers an abstraction layer. It allows any user, experienced or not in Big Data technologies, to describe the cluster to be provisioned. During configuration, Jumbo helps you out: it prevents you from making architectural mistakes, provides clusters templates and automatically installs dependencies you didn’t know about.
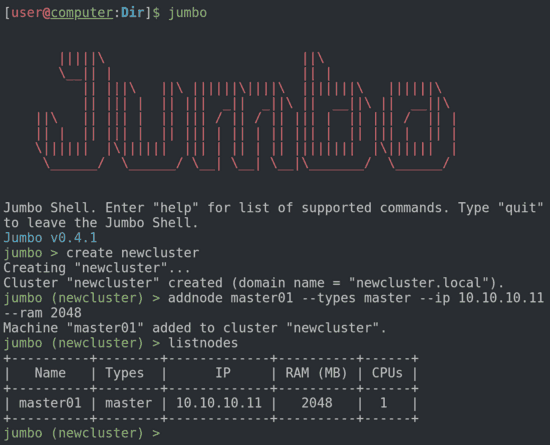
Jumbo bootstraps everything so that you only have to be in charge of 2 things: what services to install, what machine configurations to use; and press the start button (well, you have to write it, we did not actually make a shell button). Now grab a coffee, relax, and use your fully functional cluster once it is ready.
Similar projects
- Hortonworks Sandbox: single node cluster with HDP services;
- MapR Sandbox: single node with Hadoop and MapR technologies;
- Cloudera QuickStart VM: single node with Cloudera distribution of Hadoop.
Each of these projects aims at discovering Hadoop and vendor-specific technologies. They include some tutorials to learn the basics of the provided technologies.
For more advanced users, there is the hortonworks/ansible-hortonworks repository on Github, but this project requires a good understanding of both Ansible and Ambari Blueprints.
Why use Jumbo?
Jumbo’s clusters come closer to real environments because they are multi-node and can be configured with Kerberos. If you want to develop an application locally, it is a nice addition to have a cluster that resembles your production environment.
Being multi-node, you also have access to a wider range of settings. It can be useful to learn more about optimizations, services’ High Availability and so on.
Get started now!
The entire Jumbo documentation is available on the website jumbo.adaltas.com. It is an early stage project and we would love to have some of your feedback about it! Don’t hesitate to post issues on the project’s Github page.
What’s next for Jumbo
In its latest version, Jumbo is able to create and provision virtual clusters with the HDP (Hortonworks Data Platform) stack and to Kerberize them, using Vagrant (with VirtualBox or KVM as a back-end hypervisors), Ansible and Ambari.
In the coming months, we will focus on the following features:
- Complete HDP support (for now only the main Hadoop components are supported by Jumbo, though you can install others after the cluster’s provisioning with Ambari);
- Smart cluster topology - provide the best possible cluster topology based on the user available resources (VMs sizes and number, services configurations);
- Provisioning using existing VMs;
- Support for other Big Data stacks like HDF (Hortonworks DataFlow) or CDH (Cloudera Distribution for Hadoop).
Special thanks to Xavier Hermand who helped to write this article.
