


Avoid Bottlenecks in distributed Deep Learning pipelines with Horovod

By Grégor JOUET
Nov 15, 2019
- Categories
- Data Science
- Tags
- GPU
- Deep Learning
- Horovod
- Keras
- TensorFlow [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
The Deep Learning training process can be greatly speed up using a cluster of GPUs. When dealing with huge amounts of data, distributed computing quickly becomes a challenge. A common obstacle which is difficult to tackle is the apparition of bottlenecks resulting in a severe loss of efficiency when training a model.
Overview of a Deep Learning training process
What are the steps to train a Deep Learning model? Let’s say we want a model that can detect various objects in an image.
- The first step is to acquire data, gathering internally or using a public dataset, for image recognition ImageNet is commonly used. Depending on the use case the dataset size can vary from giga to terabytes. Remember that with machine learning the more data, the merrier. After the data is gathered, the next mandatory step is to clean it, a substantial amount of time should be spent on this step as a bad dataset will directly affect the model’s accuracy. Rejecting data in this step is common and training on less data is better than training on bad data. With public, curated dataset, this step should not take long but the data used should always be checked.
- The next step is to build the Deep Learning model for your task. With our exemple use case, we can reuse known architectures like VGG or ResNet. With a non-common or cutting edge use case you can find inspiration on Google research blog, keep up to date with the Facebook research blog. The important thing to remember here is that the bigger your model, the more data you will need.
When all of the above is done, we can go on and train our model. Training a model is a 5 steps process:
- Read the dataset from the source (disk, object store, database…)
- Associate the input data (an image) to its output labels (list of objects)
- Shuffle your dataset
- Enrich your dataset, for example, with images, we could do rotations, distortions, cropping etc…
- Send the data in batches to the GPUs
When the whole dataset has gone through the GPUs, you have made en ‘epoch’ and you will need many epochs to have a satisfactory model. The Deep Learning framework you chose will do the rest of the work, that is the forward pass, gradients computation, back-propagation etc…
An interesting way to benchmark this process, or at least have a reference, is to use synthetic data. Instead of reading a dataset, use random noise as the input. Of course the model will be unusable but the performance you measure will give you an idea of the cost of the four first part of our process. The goal is then to match the ‘synthetic performance’ with real data from the dataset.
The bottleneck
When running this process on a single GPU, the difference between synthetic and real speed is around 5%. But when using 32 of them the difference becomes 42%. This means our 32 GPUs are inactive for a significant amount of time. There are some classic ways of improving performance: pre-fetching or caching data from the dataset, limit the amount of threads to not over-subscribe the CPU, but the gap remains large. Even if some overhead is unavoidable when doing parallel computing, reducing it is important to make an investment in GPUs worth its cost.
After investigation the data pipeline, it appears that the dataset augmentation is taking a lot of time. But why don’t we augment it before training and feed that directly to the GPU, shouldn’t this be faster? Theoretically yes, but these distortions, rotations are done at random and done multiple times, once each epoch for each element of the dataset. The data augmentation has to be done just before the model trains on it. Moreover, the augmented dataset would be orders of magnitude larger than the original dataset, introducing new storage problems.
Solving the bottleneck problem
First, we want to keep our GPUs fed with data to keep the usage to a maximum so preloading is an absolute must. There are software being built to tackle the bottleneck problem. Horovod is a good example. Horovod is a distributed training framework thas’s easy to interface with Tensorflow, Keras, PyTorch or other Deep Learning frameworks.
The first goal of Horovod is to enable a multi GPU distributed training as seamlessly as possible, and with minimum code modification. Basically if you have a model training on a single GPU, it should be easy to scale it with Horovod. The second goal of Horovod is to be fast. That seems obvious but if Horovod falls behind the default Tensorflow Distributed Server it won’t serve any purpose. It can be used with TCP or RDMA (Remote Direct Memory Access). Of course you will always have some overhead but technologies like RDMA can help to keep it to a minimum. The Horovod repository contains some examples of training processes. Let’s see what should be added in a Keras training for instance: First, we import the Horovod library for Keras:
import horovod.keras as hvdThen we select the GPU we will be using. If you use multiple Horovod instances on a same machine, this will allow Horovod to share the GPUs among the processes (one GPU per process typically). The hvd.local_rank function identifies the local Horovod process. You can of course use multiple processes on a machine for a single training session, but each one will be managed by a different Horovod process and should use a single GPU. This configuration is done with the following code snippet:
import horovod as hvd
import tensorflow as tf
from keras import backend as K
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(hvd.local_rank())
K.set_session(tf.Session(config=config))Next, we want to tune the optimizer’s learning rate with regards to the cluster size. Then we build the distributed optimizer on top of the chosen optimizer. In this example the optimizer is Adadelta.
import horovod as hvd
import keras
opt = keras.optimizers.Adadelta(1.0 * hvd.size())
opt = hvd.DistributedOptimizer(opt)Finally, before running the session, it is crucial that all the sessions are in the same state before training. We can’t randomly initialize the weights on all the nodes, the gradients would make no sense. The session that launches the training (the one of rank 0) broadcasts the initial state of the model. This is implemented via a callback:
hvd.callbacks.BroadcastGlobalVariablesCallback(0)The horovodrun command provides a simple entry point. The program will open a ssh connection to the provided hosts and start the training session. The dependencies (Drivers, OpenMPI, Keras or Tensorflow etc…) have to be installed beforehand and a password-less ssh connection is required.
The Concepts behind Horovod
Unlike the default Tensorflow distributed training server, Horovod sits on the top of OpenMPI. The MPI project is a mature solution for distributed computing: its initial release was in 1994. It implements a distributed reduce function: allreduce. This function is used by Horovod distributed optimizer to aggregate dense tensors and distribute them back to all the processes.
The difference between Horovod and the default Tensorflow distributed training server is in their respective architectures: Tensorflow has a Master-Slave authoritative architecture. This means that all workers will receive a batch of data, compute the gradients, send it to the master, the master receives all the gradients from the workers, average them and send back the average gradient to the workers. The architecture is the same for Gradient and updated weights. Horovod, thanks to OpenMPI, uses the ring-allreduce algorithm, which optimizes the network usage and does not need a master server on which the training process will depend. Each instance sends the vectors to reduce over the network to only one peer in a ‘merry-go-round’ fashion (hence the name ring), until all the vectors are reduced.
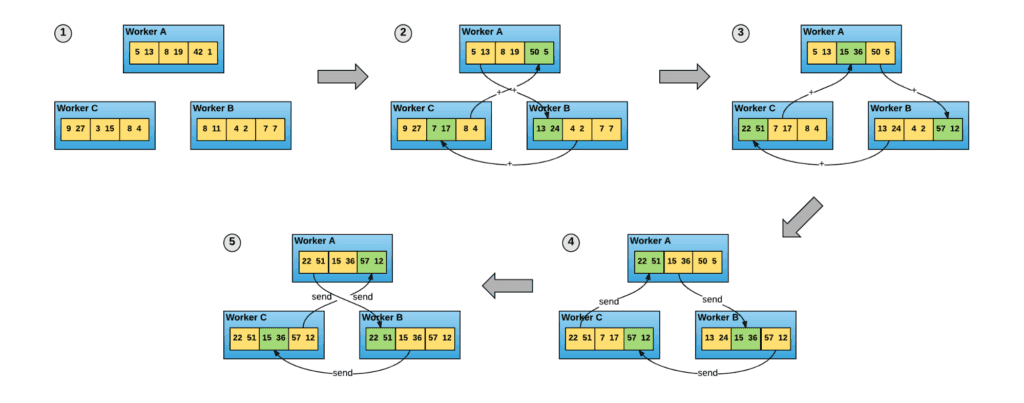
While Tensorflow lets you choose your distributed training strategy, Horovod and OpenMPI are lower level and take advantage of this memory proximity (especially with RDMA over Ethernet) and tend to outperform Tensorflow.
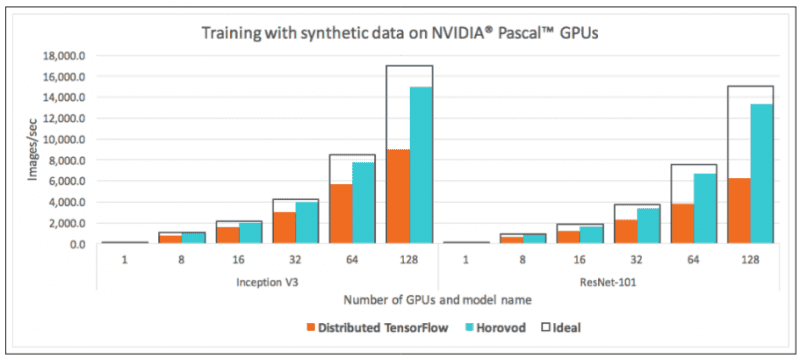
Also, the version 2 of Tensorflow introduces major features, specifically a new distributed training strategy: the CollectiveAllReduce Strategy, which seems to give outstanding results. Horovod remains relevant, especially when using PyTorch which is gaining in popularity.
Takeaways
- Distributed computing introduces a lots of new challenges but is a mandatory step to have an efficient Deep Learning pipeline.
- Among these problems, bottlenecks can nullify the benefits of a Deep Learning cluster.
- Projects such as Horovod try to provide a fast and seamless solution for distributed Deep Learning training.
Sources
- High-Performance Input Pipelines for Scalable Deep Learning: https://www.slideshare.net/Hadoop_Summit/highperformance-input-pipelines-for-scalable-deep-learning
- Uber’s Horovod Paper: https://arxiv.org/pdf/1802.05799.pdf
- OpenMPI: https://www.open-mpi.org/
- OpenMPI tutorials: http://mpitutorial.com/tutorials/
- Horovod’s repository: https://github.com/horovod/horovod
- Adadelta paper: https://arxiv.org/pdf/1212.5701.pdf
