


Spark Streaming partie 3 : DevOps, outils et tests pour les applications Spark

31 mai 2019
- Catégories
- Big Data
- Data Engineering
- DevOps & SRE
- Tags
- Apache Spark Streaming
- DevOps
- Enseignement et tutorial
- Spark [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
L’indisponibilité des services entraîne des pertes financières pour les entreprises. Les applications Spark Streaming ne sont pas exempts de pannes, comme tout autre logiciel. Une application streaming utilise des données du monde réel, l’incertitude est donc intrinsèque aux données arrivant dans l’application. Les tests sont essentiels pour détecter les défauts logiciels et les logiques défectueuses autant que possible afin que l’application demeure en condition opérationnelle une fois en exploitation dans un environnement de production.
Cet article est la troisième partie d’une série de quatre parties :
- Dans la première partie, un pipeline de données est créé en Python avec Spark Structured Streaming.
- La deuxième partie concerne la migration du pipeline vers un cluster Hadoop.
- Dans la troisième partie, l’application PySpark a été portée et testée dans un environnement Scala Spark et des test unitaires ont été ajoutés.
- La quatrième et dernière partie enrichie le pipeline de données avec un algorithme du regroupement par apprentissage automatique.
Dans cet article, des tests unitaires sont incorporés afin de réduire le risque de dysfonctionnement et d’échec de notre application Spark. L’automatisation de test dans le processus de compilation de l’application est nécessaire pour éviter les bugs logiciels et les cas critiques (Edge cases) mal gérés. Grâce aux tests automatisés, l’application Spark est automatiquement vérifiée par rapport à une suite de tests lors de chaque compilation.
Le code source Python développé précédemment sera réécrit en code Scala. Scala est un langage compilé et typé statiquement qui rend les applications Spark écrites en Scala moins sujettes aux erreurs. Les applications Scala Spark s’intègrent mieux à l’infrastructure JVM qui est probablement déjà présente dans l’entreprise. La performance n’est pas la motivation ici, car les applications PySpark utilisant l’API DataFrame sont généralement presque aussi rapides que leurs homologues en Scala.
Le projet se trouve dans le répertoire GitHub du dépôt adaltas/spark-streaming-scala sur GitHub. Il contient la version Scala Spark du précédent projet spark-streaming-pyspark, ainsi que les tests unitaires développés dans cet article.
Vue d’ensemble sur une chaîne d’outils DevOps
La pratique de l’écriture de tests automatisés est une activité importante qui améliore la qualité et la fiabilité du logiciel et de son cycle de vie. De plus, ils apportent du confort aux développeurs en réduisant le temps nécessaire à la compilation et à l’exécution du code en cours d’écriture, rendant ainsi le processus de programmation plus fluide et réactif tout en garantissant la préservation des fonctionnalités acquises.
Les tests automatisés font partie de la stratégie d’intégration continue (CI) qui vise l’intégrité de l’application dans le cycle de vie du logiciel à tout moment. La liste ci-dessous donne un aperçu général de l’ensemble des pratiques de DevOps dans le cycle de vie du logiciel :
- Intégration continue (CI)
- Le développement du code avec la gestion de versions (e.g. GIT)
- Automatisation des builds (e.g. Jenkins compilant du code Scala géré par GIT avec sbt)
- Automatisation de tests unitaires, d’intégration et de validation
- Déploiement continu (CD)
- Emballage/Packaging (pré-déploiement) des logiciels dans des dépôts (“registries” et “repositories”)
- Releasing
- Configuration et provisionnement d’infrastructures (IaC - configuration et gestion de l’infrastructure, par exemple avec Ansible)
- Surveillance - surveillance de la performance des applications, expérience de l’utilisateur final
Tous les points s’appliquent au cycle de vie d’une application Spark, comme à tout autre logiciel. L’intégration continue d’une application Spark ne diffère pas beaucoup de celle d’une application Scala. Elle doit être gérée par un logiciel de contrôle de source, compilée et testée automatiquement. Le déploiement continu dépend en grande partie de l’infrastructure cible et sort du cadre de cet article. De toutes les pratiques DevOps, cet article met l’accent sur l’écriture de tests unitaires, la couverture de tests et l’utilisation d’un linter.
Tests unitaires et tests d’intégration
Un test unitaire vérifie rapidement qu’une partie isolée du code source fonctionne comme prévu. Les unités du code source testées peuvent par exemple être associés à des méthodes. Ils vérifient que les méthodes ont un comportement spécifié, en particulier dans des conditions difficiles. Les tests garantissent qu’une unité du code source est conforme à la spécification.
Strictement parlant, tout test unitaire doit être complètement isolé des autres tests unitaires et des composants externes. Sur cette base, on pourrait soutenir que tout test Spark est un test d’intégration plutôt qu’un test unitaire. Cela semble justifié puisqu’un test impliquant Spark nécessite une SparkSession, qui est non seulement une dépendance externe, mais qui est également souvent partagée entre les tests. Néanmoins, la partie la plus importante de l’isolation des tests unitaires est la séparation des données entre les tests. Cela pourrait être assuré en créant des DataFrames individuels simulés pour chaque test, auquel cas il est acceptable d’appeler ces tests Spark des tests unitaires.
En complément des tests unitaires, il est recommandé d’écrire des tests d’intégration qui simulent un environnement dans lequel les différents composants interagissent. Dans certains cas, les frameworks fournissent déjà les connecteurs et les tests d’intégration ne sont pas nécessaires. Par exemple, Spark supporte Kafka et cette intégration a déjà été testée.
Les tests de bout en bout pourraient être considérés en plus de tests d’intégration. Les tests de bout en bout vérifient de manière concluante que tous les composants sont configurés correctement et que la chaîne fonctionne d’un bout à l’autre. Les tests d’acceptation sont un autre type de tests qui pourraient être effectués pour valider que la solution finale fonctionne comme prévu dans les spécifications. Les tests de bout en bout et les tests d’acceptation sont relativement coûteux, complexes et prennent beaucoup de temps.
Tests unitaires de fonctions assistantes
Dans les applications Spark, il y a souvent des fonctions qui ne dépendent en aucune façon de Spark et des RDD/DataFrames. Ces fonctions contiennent généralement une logique métier (par exemple spécifique à l’entreprise) et peuvent être testées indépendamment de Spark. Dans le code Python développé dans la première partie de la série, la fonction isPointInPath() a été créée pour vérifier si le point (x, y) est dans un polygone donné. Le code ci-dessous est une implémentation Scala de cette fonction.
package com.adaltas.taxistreaming.utils
object PointInPoly {
def isPointInPoly(xCoordinate: Double, yCoordinate: Double, poly: Seq[Seq[Double]]): Boolean = {
// https://wrf.ecse.rpi.edu/Research/Short_Notes/pnpoly.html
val numberOfVertices = poly.length
var i = 0
var j = numberOfVertices-1
var crossedPolygone = false
for (i <- 0 until numberOfVertices) {
if (( (poly(i)(1) > yCoordinate) != (poly(j)(1) > yCoordinate) ) &&
( xCoordinate < poly(i)(0) + (poly(j)(0) - poly(i)(0)) * (yCoordinate - poly(i)(1)) / (poly(j)(1) - poly(i)(1)) )
) crossedPolygone = !crossedPolygone
j = i
}
crossedPolygone //true when point is in poly (vertical line crossed polygone an odd number of times)
}
}La structure de dossier sbt doit être respectée. Tous les fichiers de code source Scala et les fichiers de test doivent être placés dans les dossiers “src/main/scala/” et “src/test/scala/”, respectivement. Ils pourraient y être placés directement, mais le regroupement de fichiers Scala dans des packages Scala est une bonne pratique.
Suivant la convention com.adaltas.taxistreaming.utils. Les tests unitaires vérifiant le code source du fichier “src/main/scala/com/adaltas/taxistreaming/utils/PointInPoly.scala” doivent être écrits dans le fichier “src/test/scala/com/adaltas/taxistreaming/utils/PointInPolyTest.scala”.
Le framework ScalaTest sera utilisé pour écrire ces tests unitaires. ScalaTest est une bibliothèques qui fournit des outils pour tester le code Scala. Elle fournit une abstraction de haut niveau facilitant la rédaction de tests pour les applications Scala. Les tests sont écrits avec l’un des styles de test disponibles dans ScalaTest.
Le code ci-dessous est un exemple de fichier PointInPolyTest.scala avec trois tests unitaires simples.
package com.adaltas.taxistreaming.utils
import org.scalatest.FlatSpec
class PointInPolyTest extends FlatSpec {
val manhattanBox: Seq[Seq[Double]] = Vector(
Seq(-74.0489866963, 40.681530375),
Seq(-73.8265135518, 40.681530375),
Seq(-73.8265135518, 40.9548628598),
Seq(-74.0489866963, 40.9548628598),
Seq(-74.0489866963, 40.681530375)
)
"A Geopoint from Manhattan" must "be inside Manhattan polygon" in {
val pointManhattan: (Double, Double) = (-73.997940, 40.718320)
assert(PointInPoly.isPointInPoly(pointManhattan._1, pointManhattan._2, manhattanBox))
}
"A Geopoint from Meudon" must "not be inside Manhattan polygon" in {
val pointMeudon: (Double, Double) = (2.247600, 48.816210)
assert(!PointInPoly.isPointInPoly(pointMeudon._1, pointMeudon._2, manhattanBox))
}
"An arbitrary point (1,1)" must "be inside a square ((0,0),(2,0),(2,2),(0,2))" in {
assert(PointInPoly.isPointInPoly(1.0, 1.0, Seq(Seq(0,0), Seq(2,0), Seq(2,2), Seq(0,2))))
}
}Que vous utilisiez un IDE ou la console, les commandes pour préparer le fichier built.sbt et exécuter les tests sont disponibles sur le site Web officiel de Scala. Assurez-vous d’inclure la ligne libraryDependencies += "org.scalatest" %% "scalatest" % "3.0.5" % "test" dans le fichier build.sbt. L’exécution de tous les tests doit maintenant afficher les trois tests ci-dessus réussis. Ces tests unitaires ne vérifient que la logique la plus importante, d’autres tests pourraient être écrits pour les compléter.
Les stratégies pour tester Spark
Tous les tests Spark nécessitent une SparkSession, le point d’entrée de tout programme Spark. La SparkSession pourrait être fournie aux tests et gérée entre eux de plusieurs façons :
- Initialiser
SparkSessionet le détruire entre chaque test avec leBeforeAndAfterEachde ScalaTest - Grouper les tests en suites de test ; initialiser
SparkSessionet le détruire entre chaque suite de test avec leBeforeAndAfterAllde ScalaTest - Exploiter la bibliothèque spark-testing-base et réutiliser facilement la
SparkSession - Utiliser la SharedSparkSession native de Spark qui est disponible à partir de Spark 2.3
Dans toutes ces stratégies, les tests sont exécutés localement. Une application Spark en production est exécutée sur plusieurs nœuds d’un cluster. Les applications distribuées nécessitent des tests supplémentaires. Par exemple, il est important de savoir si le code lancé sur les exécuteurs a été correctement parallélisé.
Néanmoins, l’exécution sur une machine locale garantit que l’application s’exécute conformément à la logique souhaitée et respecte les spécifications. Une application en streaming traite les données comme des évènements, mais sa logique pourrait être testée à l’aide de test unitaires à la manière d’une application Spark en batch. Après tout, le traitement avec Spark structured streaming et le traitement en batch utilisent le même moteur Spark SQL et partagent la même API.
Réécriture du code de nettoyage des données Taxi
Dans les parties précédentes, le premier traitement effectué sur les données Taxi était le nettoyage des données. L’objectif était de filtrer les trajets de taxi qui ont commencés ou qui se sont terminés en dehors de New York. Le code ci-dessous implémente cela en Scala et peut être sauvegardé sous “src/main/scala/com/adaltas/taxistreaming/processing/TaxiProcessing.scala” dans le paquet com.adaltas.taxistreaming.processing.
package com.adaltas.taxistreaming.processing
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.functions.col
object TaxiProcessing {
def cleanRidesOutsideNYC(dfRides: DataFrame): DataFrame = {
val lonEast = -73.7
val lonWest = -74.05
val latNorth = 41.0
val latSouth = 40.5
dfRides.filter(
col("startLon") >= lonWest && col("startLon") <= lonEast &&
col("startLat") >= latSouth && col("startLat") <= latNorth &&
col("endLon") >= lonWest && col("endLon") <= lonEast &&
col("endLat") >= latSouth && col("endLat") <= latNorth
)
}
}D’autres traitements sur les données de taxi développés dans la première partie pourraient être réécrits comme fonctions additionnelles dans l’objet TaxiProcessing. Nous ne testerons que le nettoyage des données de Taxi et considérerons le code source comme prêt.
Nous voulons tester que l’application du traitement sur un DataFrame renvoie le résultat attendu. Une SparkSession est nécessaire pour gérer le DataFrame et les données à traiter avec les résultats attendus. Parmi les stratégies de test décrites précédemment, la seconde sera incorporée.
La préparation des tests unitaires Spark sur les données de taxi
Préparons une suite de tests “src/test/scala/com/adaltas/taxistreaming/processing/TaxiProcessingTest.scala” qui teste la logique de traitement principale sur les données de taxi. Spark est nécessaire pour exécuter des tests reposant sur des DataFrames. Afin d’obtenir la main sur une session Spark, un trait SparkTestingSuite est défini. Il étend les FlatSpec et BeforeAndAfterAll de ScalaTest.
package com.adaltas.taxistreaming.processing
import org.scalatest.{BeforeAndAfterAll, Suite}
import org.apache.spark.sql.SparkSession
trait SparkTestingSuite extends FlatSpec with BeforeAndAfterAll { self: Suite =>
var sparkTest: SparkSession = _
override def beforeAll() {
super.beforeAll()
sparkTest = SparkSession.builder().appName("Taxi processing testing")
.master("local")
.getOrCreate()
}
override def afterAll() {
sparkTest.stop()
super.afterAll()
}
}Maintenant, tous les traits qui étendent SparkTestingSuite auront accès à une session Spark au travers de la variable spartTest.
Les tests doivent être simples et courts, il faut donc veiller à ne pas écrire du code sortant du contexte spécique de ce pourquoi ils ont été écrits. Le trait TaxiTestDataHelpers défini ci-dessous fournit des fonctions d’assistance pour créer des jeux de données et générer des DataDrames que des tests unitaires individuels pourraient utiliser. Effectivement, cela permet de supprimer le code répétitif. Le trait étend la SparkTestingSuite de sorte que toutes les fonctions assistantes aient déjà un accès à la session Spark.
import org.apache.spark.sql.Row
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import java.sql.Timestamp
trait TaxiTestDataHelpers extends SparkTestingSuite {
private val taxiRidesSchema = StructType(Array(
StructField("rideId", LongType), StructField("isStart", StringType),
StructField("endTime", TimestampType), StructField("startTime", TimestampType),
StructField("startLon", FloatType), StructField("startLat", FloatType),
StructField("endLon", FloatType), StructField("endLat", FloatType),
StructField("passengerCnt", ShortType), StructField("taxiId", LongType),
StructField("driverId", LongType))) // "yyyy-MM-dd hh:mm:ss" e.g. 2013-01-01 00:00:00
def getDataRides(): List[String] = {
List(
"6,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.866135,40.771091,-73.961334,40.764912,6,2013000006,2013000006",
"11,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.870834,40.773769,-73.792358,40.771759,1,2013000011,2013000011",
"55,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.87117,40.773914,-73.805054,40.68121,1,2013000055,2013000055",
"31,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.929344,40.807728,-73.979935,40.740757,2,2013000031,2013000031",
"34,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.934555,40.750957,-73.916328,40.762241,5,2013000034,2013000034"
)
}
def convTaxiRidesToDf(inputData: List[String]): DataFrame = {
val rdd = sparkTest.sparkContext.parallelize(inputData) // RDD[String]
val rddSplitted = rdd.map(_.split(",")) //RDD[Array[String]]
val rddRows: RDD[Row] = rddSplitted.map(arr => Row(
arr(0).toLong, arr(1), Timestamp.valueOf(arr(2)), Timestamp.valueOf(arr(3)),
arr(4).toFloat, arr(5).toFloat, arr(6).toFloat, arr(7).toFloat,
arr(8).toShort, arr(9).toLong, arr(10).trim.toLong)) //rowRideRDD
sparkTest.createDataFrame(rddRows, taxiRidesSchema)
}
}Le fichier build.sbt nécessite une configuration supplémentaire pour Spark. La fonctionnalité de Forking doit être activée pour exécuter Spark dans une JVM séparée. Par défaut, le code tourne sur la même JVM que sbt, ce qui crée un risque que Spark fasse tomber sbt. Dans l’ensemble, le projet est compilé avec la configuration sbt comme ci-dessous :
name := "taxi-streaming-scala"
scalaVersion := "2.11.12"
fork in Test := true
libraryDependencies += "org.scalatest" %% "scalatest" % "3.0.5" % "test"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.1"
libraryDependencies += "org.apache.spark" %% "spark-hive" % "1.5.0"
libraryDependencies += "org.apache.spark" %% "spark-hive-thriftserver" % "2.4.1"Il est également utile de cacher les messages log de niveau INFO des tests. Ceci peut être fait en copiant le fichier conf/log4j.properties.template de Spark dans “src/test/resources/log4j.properties” et en modifiant la ligne :
log4j.rootCategory=INFO, consolevers :
log4j.rootCategory=WARN, consoleTester le traitement Taxi avec Spark
Une fois les traits SparkTestingSuite et TaxiTestDataHelperspréparés, les tests unitaires pourront être écrits rapidement et de manière concise. Les tests de nettoyage des données relatives au côté est de NYC est couvert ci-dessous. Sur l’image ci-dessous, il y a une zone géographique délimitant NYC (sans le quartier de Staten Island). Étant donné que les paramètres sont des coordonnées, il est facile de voir la signification des terms anglais : “edge case” et “corner case”.
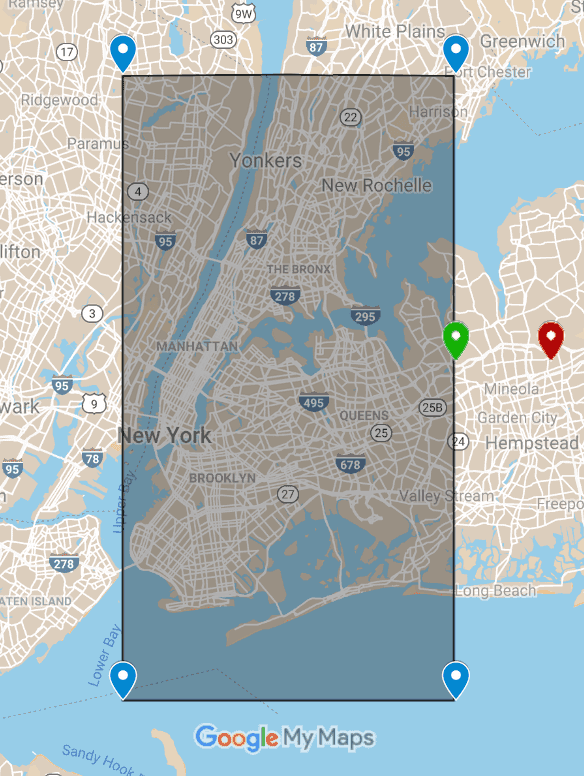
- La course commençant à l’extérieur de NYC (rouge) doit être confirmée pour être supprimée.
- La course commençant du côté est de NYC (vert) doit être conservée. Le cas est appelé “edge case”.
- L’écriture de tests pour les bords de la boîte garantit que toutes les courses avec des coordonnées géographiques à l’intérieur de la boîte seront également conservées. La même approche de test s’applique à tous les autres paramètres, y compris les paramètres temporels, les données financières, etc.
Deux tests unitaires correspondant au bord est de la zone sont écrits dans le code ci-dessous. Une approche identique pourrait couvrir les cas du nord, de l’ouest et du sud.
class TaxiProcessingTest extends TaxiTestDataHelpers {
"A ride starting OUTSIDE the east edge of NYC" should "be filtered out" in {
val dfRides = convTaxiRidesToDf(getDataRides() :+
"-1,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.6,40.771091,-73.961334,40.764912,6,2013000006,2013000006"
// ride with -73.6 startLon appended is outside east edge of NYC and should be filtered out
)
assert(TaxiProcessing.cleanRidesOutsideNYC(dfRides).count() === 5)
}
"A ride starting ON the east edge of NYC" should "not be filtered out (edge case)" in {
val dfRides = convTaxiRidesToDf(getDataRides() :+
"-1,START,2013-01-01 00:00:00,1970-01-01 00:00:00,-73.70001,40.771091,-73.961334,40.764912,6,2013000006,2013000006"
// ride with -73.70001 startLon appended isn't outside NYC, it's an edge case that should work
)
assert(TaxiProcessing.cleanRidesOutsideNYC(dfRides).count() === 6)
}
}Le reste de la logique du traitement streaming pourra être ajouté dans TaxiProcessing.scala et testé de la même façon en ajoutant de nouvelles fonctions à la classe TaxiProcessingTest et en utilisant d’autres fonctions d’assistance dans le trait TaxiTestDataHelpers.
- La logique de la jonction stream-stream pourra être testée. En l’absence d’un stream basé sur un jeu de données réel, une suite de tests pourrait simuler les courses avec des horodatages spécifiés pour vérifier que les courses qui violent les contraintes de temps de jointure soient rejetées.
- Les résultats de fonctions de type “aggregate” ont pu être vérifiés. Par exemple, un test pourrait simuler une heure de parcours, calculer et comparer le
avg("tip")pour chaque fenêtre temporelle - La section d’ingénierie des fonctionnalités pourrait être testée de manière très similaire. Le
SparkTestdevrait être utilisé pour créer une instance de la variable de broadcast explicite - La fonction
parse_data_from_kafka_message()du premier article de la série pourrait être testée avec des DataFrames simulés, sans dépendance sur Kafka
Les linters Scala
Les linters sont des outils utilisés pour analyser le code afin de détecter d’éventuelles erreurs de programmation et de style. L’utilisation de linters est considérée comme une bonne pratique dans le processus de développement de logiciel. L’examen du code source à l’aide de linters est important pour identifier autant de ”code smell” et de constructions de code suspectes que possible avant la mise en production de l’application. Les linters ont plus d’utilisations que seulement éviter les erreurs. Les règles d’un linter peuvent imposer un format unifié et une conformité aux directives de style spécifiques au projet. La cohérence du code des applications est particulièrement importante dans les entreprises, où de nombreuses personnes de différentes équipes collaborent au sein d’un même projet.
Scalafix est un linter scala qui s’exécute après la compilation. Premièrement, il analyse statiquement le code source pour rechercher les mauvais patterns spécifiés par les règles du linter. Deuxièmement, Scalafix corrige les problèmes rencontrés lors de la refactorisation.
Pour installer Scalafix, ajoutez la ligne ci-dessous dans le fichier “project / plugins.sbt” :
addSbtPlugin ("ch.epfl.scala"% "sbt-scalafix"% "0.9.5")A titre d’exemple, considérons la règle Scalafix RemoveUnused. Avant d’exécuter le linter, ajoutez les options suivantes dans le fichier build.sbt :
addCompilerPlugin (scalafixSemanticdb) // active SemanticDB
scalacOptions ++ = List (
"-Yrangepos", // requis par le plugin de compilation SemanticDB
"-Ywarn -used-import" // requis par la règle `RemoveUnused`
)Scalafix peut être lancé via sbt avec une commande :
sbt "scalafix RemoveUnused"Si des importations non utilisées dans le code du projet ont été trouvées, elles sont automatiquement supprimées par Scalafix. Vous pouvez utiliser d’autres règles intégrées. Il est aussi possible d’implémenter des [règles personnalisées](https://scalacenter.github.io/ scalafix / docs / developers / setup.html).
Une alternative à Scalafix est WartRemover, qui est un type de linter sur compilation. Comme il fonctionne au moment de la compilation, il est considéré comme intéractif et flexible. Un autre avantage de WartRemover est son ensemble plus riche de règles intégrées, nommés warts.
Parmi les autres linters figurent Scalafmt et scalastyle qui, tout en offrant des fonctionnalités limitées, s’intègrent à IntelliJ IDEA, l’un des IDE les plus populaire pour le développement en Scala.
La couverture de code
La suite de tests doit couvrir l’ensemble du code et de ses fonctionnalités. Des IDE ou sbt-coverage peuvent être utilisés pour obtenir le pourcentage du code source testé. Une couverture de code élevée est un bon indicateur du fait que l’application fonctionnera comme prévu, mais ce n’est pas la métrique ultime décrivant la qualité de l’application. Si les tests sont écrits uniquement pour le principe de tester, avoir une couverture élevée de tests est fallacieuse. Avant tout, les tests doivent être significatifs et vérifier les fonctionnalités nécessaires.
La couverture de code peut être mesurée selon différents critères. Une métrique classique est la couverture par ligne, qui indique le nombre de pourcentages de lignes de code testées. D’autres exemples sont la couverture des fonctions, la couverture des branches et la couverture des instructions. Scala n’est pas un langage verbeux. Il peut y avoir plusieurs déclarations sur une seule ligne. Ainsi, tester le code Scala en fonction de la couverture des instructions fournit des résultats plus précis qu’en utilisant une approche basée sur la couverture des lignes.
De nombreux IDE fournissent des fonctionnalités de mesure de couverture de code. Par exemple, IntelliJ IDEA a son propre runner de couverture de code. Il est aussi possible d’utiliser un runner externe tel que JaCoCo. La mesure de la couverture de code avec IntelliJ IDEA présente deux inconvénients principaux. Premièrement, seules les classes, méthodes et lignes sont utilisées comme métriques de couverture de code, tandis que la couverture d’instructions est plus appropriée pour Scala. Deuxièmement, les outils de couverture de code d’IntelliJ ne peuvent être utilisés que dans l’environnement de développement, alors que l’indicateur de couverture de code peut être utile dans toute la chaîne du cycle de vie du logiciel.
Mesurer la couverture de code avec sbt-scoverage
Scoverage est un outil de couverture de code pour Scala qui utilise des instructions et des branches comme métriques de couverture de code. Scoverage est un plugin de compilation scalac qui doit être utilisé avec un plugin de construction. Par exemple, sbt-scoverage est un plug-in pour sbt qui intègre la bibliothèque de scoverage. Un autre avantage de l’utilisation de scoverage est son support pour SonarQube et Jenkins. On peut appliquer des tests de couverture de code en CI et analyser les résultats en continu dans SonarQube.
Avant d’exécuter des tests avec sbt-scoverage, ajoutez la ligne addSbtPlugin (" org.scoverage "%" sbt-scoverage "%" 1.5.1 ") dans le fichier “project / plugins.sbt”.
La commande ci-dessous exécute tous les tests avec couverture et génère un rapport :
sbt clean test de couvertureLes emplacements des rapports HTML et XML générés par scoverage sont indiqués par sbt après l’exécution des tests. Un exemple de rapport HTML qui se trouve généralement dans le répertoire “scoverage-report” est présenté ci-dessous :
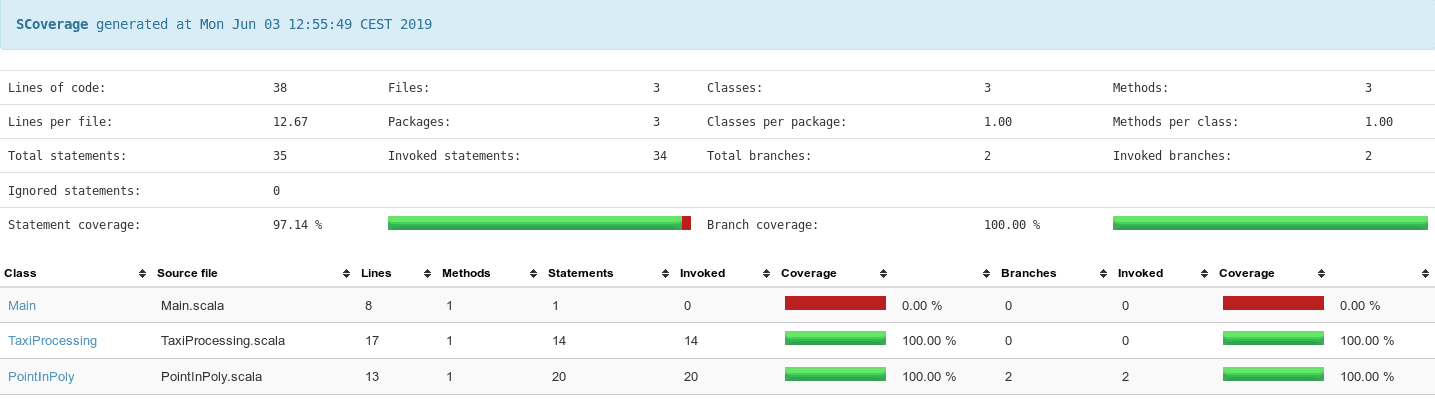
Le rapport indique que toutes les instructions du code source développé dans cet article ont été appelées lors des tests. Si les rapports statiques ne suffisent pas, Scoverage peut être utilisé avec SonarQube pour fournir des résultats de couverture de code pour une inspection continue dans SonarQube.
Résumé
Les tests en génie logiciel sont importants, comme dans tout autre projet d’ingénierie. Le test unitaire automatique est l’approche la plus fondamentale pour tester un logiciel. Avec une stratégie de test adéquate, une application Spark peut être testée aussi facilement qu’une application classique. Cet article a montré comment les tests unitaires Spark peuvent être écrits à l’instar de l’exemple du code Spark développé dans les parties précédentes de la série. Pour réécrire et tester le code source des articles précédents, la méthodologie présentée resterait la même.
