


Intégration de Druid et Hive

17 juin 2019
- Catégories
- Big Data
- Business Intelligence
- Tech Radar
- Tags
- LLAP
- OLAP
- Hive
- Analyse de données
- SQL
- Druid [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Nous allons dans cet article traiter de l’intégration entre Hive Interactive (LLAP) et Druid. Cet article est un complément à l’article Ultra-fast OLAP Analytics with Apache Hive and Druid.
Présentation des Outils
Hive et Hive LLAP
Hive est un environnement permettant l’exécution de requêtes SQL sur des données stockées dans HDFS. Hive peut configurer différents exécuteurs :
- Map Reduce
- TEZ
- TEZ + LLAP
LLAP est un système de cache spécifiquement conçu pour Hive. C’est un long-running service s’exécutant dans YARN (via slider). Cette architecture permet à Hive de servir les requêtes sans instancier de nouveaux contextes d’exécution ralentissant significativement les temps de réponse (d’où sa dénomination Hive Interactive). D’autre part, la mise en place d’un cache mutualisé pour l’ensemble des utilisateurs permet une utilisation optimale. Cependant, LLAP présente tout de même quelques défauts :
- L’utilisation de LLAP est en mode “fair”, dans lequel les tâches reçoivent, en moyenne, une part égale des ressources au fil du temps mais ce qui ne permet pas de gérer finement ses ressources en fonction des utilisateurs (low multitenancy)
- La mémoire RAM réservée par les démons LLAP, souvent conséquente, est gaspillée lorsque Hive LLAP n’est pas sollicité.
Druid
Druid est un data store open source, distribué, orienté colonne, conçu pour requêter rapidement (sub-second) des données événementielles et historisées. Druid permet une ingestion de données à très faible latence (quasi-temps réel) et des agrégations rapides. La présence d’index inversés en fait d’autre part un excellent choix pour le filtrage de données. Druid est donc un outil particulièrement adapté pour la BI (agrégations, index inversés) et les séries temporelles (ingestion rapides, agrégations).
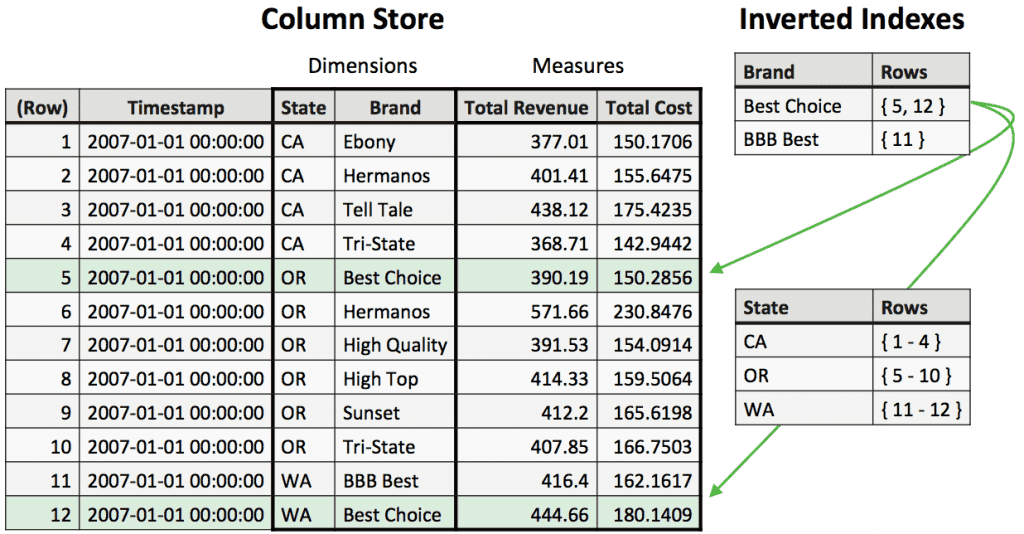
Cependant, Druid n’est pas du tout adapté pour effectuer des requêtes complexes, telles que les jointures.
Pourquoi intégrer Druid et Hive LLAP ?
Hive et Druid sont deux outils Big Data orientés colonnes, mais leurs fonctionnalités sont complémentaires :
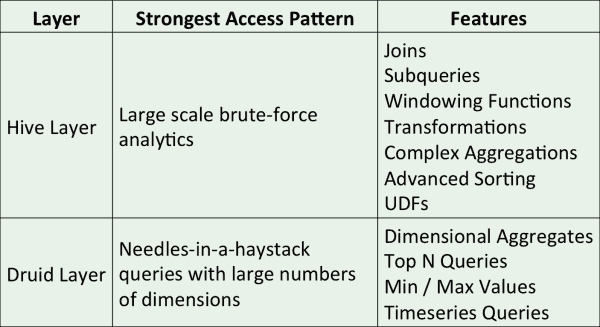
- Profiter des index inversés dans Druid pour les requêtes de type “chercher une aiguille dans une botte de foin”. Hive n’est en général pas du tout performant dans ce type de requête, car il ne possède pas de système d’index.
- Utiliser une API SQL par dessus Druid. Druid se requête via JSON à travers son interface REST. Une fois la table Hive déclarée, l’utilisateur pourra alors requêter Druid via SQL (en passant par Hive).
- Permettre des opérations complexes sur des données Druid. Druid n’est pas adapté pour la jointure de tables, ce que fait très naturellement Hive.
- Indexer les résultats de requêtes complexes dans Druid. La déclaration d’une table Druid dans Hive permet à Hive de pouvoir stocker le résultat d’une requête directement dans druid, et de pouvoir requêter ce dataset. Cela est notamment utilisé pour la matérialisation de vues (HIVE-10459) et la construction de cubes OLAP.
Comment cela fonctionne ?
Hive est agnostique sur la source de données. Il peut requêter n’importe quel système, tant qu’on lui fournit une classe de sérialisation/dé-sérialisation et un schéma. C’est justement l’ajout de la classe org.apache.hadoop.hive.druid.DruidStorageHandler, à partir de Hive 2.2 (backporté sur Hive 2.1 par Hortonworks), qui se charge des lectures/écritures. Le schéma est fourni, comme pour n’importe quelle table Hive, par l’utilisateur.
Actuellement, Druid se présente comme un fournisseur de données. L’ensemble des calculs est effectué par Hive. Cependant, il est prévu pour les prochaines versions de Hive que le moteur de calcul du plan (Calcite) puisse pousser certains calculs dans Druid.
Installation
Nous avons utilisé pour ce test une machine virtuelle sur laquelle nous avons installé HDP 2.6.4.0. Nous avons seulement activé les services nécessaires à notre test :
- Zookeeper
- 1 znode
- HDFS
- 1 namenode
- 1 datanode
- YARN
- 1 resourcemanager
- 1 nodemanager
- Hive
- 1 Hive metastore
- 1 Hiveserver2
- 1 Hiveserver2 Interactive
- Druid
- 1 Druid Broker
- 1 Druid Coordinator
- 1 Druid Overlord
- 1 Druid Router
- 1 Druid Historical
- 1 Druid MiddleManager
Hive
Hive Interactive (LLAP) doit être installé pour interagir avec Druid. Nous avons alloué 32 GB de RAM à YARN nodemanager sur cette machine. Hive LLAP est configuré avec 1 noeud démon et 20GB de cache. Pour plus d’informations sur l’installation de Hive LLAP, consulter l’article LLAP sizing and Setup
Druid
Puisque nous utilisons une unique machine, l’ensemble des services a été colocalisé. Globalement, 24 GB de RAM ont été alloués à Druid. La répartition a été calculée afin de respecter les proportions spécifiées par la documentation druid.
Le deep Storage est configuré sur HDFS.
Star Schema Benchmark
Le Star Schema Benchmark est un banc de test pour la performance des bases de données orientées BI, et basées sur le TPC-H.
Télécharger le projet SSB-hive-druid
Ce projet permet de :
- Générer des CSV honorant le schéma SSB via un job MapReduce exécutant ssb-dbgen
- Injecter ces CSV dans HDFS
- Déclarer les CSV en tables externes dans Hive
- Copier les données dans un format optimisé (ORC)
- Exécuter des queries de benchmark dans Hive
- Générer les données dans Druid
- Exécuter les requêtes dans Druid et comparer avec les précédents résultats
Éditer le fichier config selon la configuration cible
BEELINE=beeline -u "${HS2_URI}" # Beeline command to execute. The auth parameter can be added regarging Hive configurationSCALE=2 # facteur numérique pr le volume de données générées (≃ scale*200MB)
#HDFS
HDFS_WORKDIR="/tmp/ssb/${SCALE}n/" # Dossier temporaire des fichiers CSV
# HIVE
HS2_URI='jdbc:hive2://localhost:10001/' # URI JDBC pour Hive
HIVE_WH='/apps/hive/warehouse' # Dossier HDFS contenant les tables hive
RAW_DB="ssb_${SCALE}n_raw" # nom de la DB contenant les tables externes pointant sur les CSV
ORC_DB="ssb_${SCALE}n_orc_flat" # nom de la DB contenant les ORC optimisé copiés depuis la RAW_DB
# DRUID
META_URI='jdbc:postgresql://localhost:5432/druid' # metastore druid
META_USERNAME='druid' # druid metastore username
META_PASSWORD='druid' # druid metastore password
BROKER_ADDR='localhost:8082' # druid broker address
COORDINATOR_ADDR='localhost:8081' # druid coordinator address
BEELINE=beeline -u "${HS2_URI}" # Commande beeline à exécuter. Les paramètres d'authentification peuvent être à rajouter selon la configuration de hiveLa compilation de ssb-dbgen nécessite les dépendances suivantes :
- make
- gcc
- javac
- maven
Le chemin HDFS_WORKDIR ne doit pas exister avant la génération de données. Une fois les dépendances installées, lancer la compilation ainsi que la génération des données dans HDFS et Hive via le script.
La génération des données nécessite les paquets suivants, configurés :
- hdfs
- yarn
- beeline
Génération des données
Pour vérifier l’ensemble des dépendances, exécuter le script
./00_check_dependencies.shHive
La compilation et la génération de données se fait via l’exécution du script
./01_datagen.shL’exécution est ignorée si la database ORC_DB existe déjà.
Cette étape ne requiert pas Hive LLAP. En revanche, les données sont générées par un job MapReduce. YARN doit donc pouvoir instancier un Application Master ainsi qu’au moins un container. Si les ressources sont limitées, il est alors possible d’éteindre LLAP afin de libérer les ressources consommées par les démons LLAP.
Dans ce cas, un Hiveserver2 en mode non-interactif (sans LLAP) doit être démarré afin de pouvoir créer les différentes bases de données et déclarer les tables externes. L’URI JDBC HS2_URI doit être adapté en conséquence.
ATTENTION : Si le job YARN échoue avec une erreur de type “Buffer Overflow” cela signifie que la version de glibc n’est pas compatible avec les paramètres d’optimisations de compilation. Pour corriger ce bug, éditer le fichier ssb-generator/ssb-dbgen/makefile et supprimer le paramètre -O des CFLAGS (ligne 17)
Une fois le script ./O1_datagen.sh terminé, se connecter à Hive (via beeline par exemple) et vérifier la présence des tables suivantes dans les databases RAW_DB et ORC_DB :
- customer
- dates
- lineorder
- part
- supplier
Le nombre de lignes dépend du paramètre SCALE, mais doit être identique d’une DB à l’autre.
Une fois la création et l’alimentation de la database ORC_DB terminées, il est possible de supprimer RAW_DB ainsi que les fichiers /tmp/ssb/
Druid
La génération des données dans Druid se fait via l’exécution du script
./02_load_druid.shCette étape peut être longue. À titre d’exemple, la construction des données Druid pour 10GB de données (scale=50) a duré 4h33 sur notre machine de test. Cependant, le job est particulièrement mal distribué dans notre cas, puisque les tests ont été exécutés sur une seule machine. L’utilisation d’un cluster Hadoop multi-nœuds devrait très significativement améliorer les performances.
Une fois le script ./O2_load_druid.sh terminé, se connecter à Hive et vérifier la présence de la table ${ORC_DB}.ssb_druid
Les segments Druid sont sauvegardés sur HDFS, dans le chemin suivant : ${HIVE_WH}/${ORC_DB}.ssb_druid. Attention, les segments Druid ne sont pas stockés dans le dossier de la database ORC (${HIVE_WH}/${ORC_DB}.db/).
Exécution du Benchmark
Les requêtes de benchmark se trouvent dans le dossier queries. Chaque requête est en deux versions, une version qui requêtera Druid (sous-dossier druid) et l’autre qui requêtera les tables ORC (sous-dossier hive).
L’ensemble des requêtes peuvent être exécutées via les scripts suivants :
./03_run.sh # exécute toutes les requêtes sur les tables ORC
./04_run_with_druid.sh # exécute toutes les requêtes sur les segments DruidIl n’est pas nécessaire d’alimenter druid (./O2_load_druid.sh) avant le lancement du script ./O3_run.sh
Ces scripts afficheront la durée du traitement une fois terminé.
Résultats
Le benchmark a été exécuté avec différents facteurs, de 2 à 50. Il représente le temps d’exécution, en secondes, de l’ensemble des requêtes en fonction du facteur de taille.
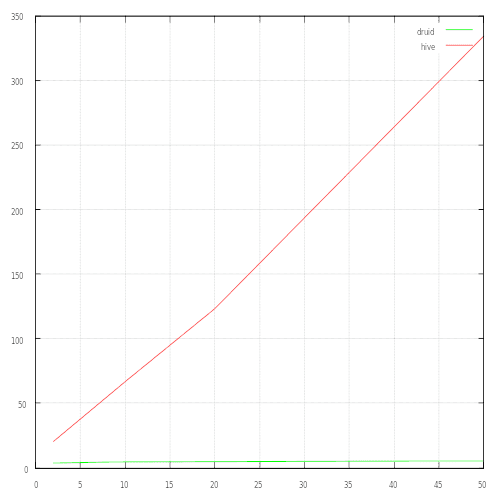
On remarque ici que le temps d’exécution Hive est proportionnel au facteur de taille, et dépasse la minute dès le facteur 10 (2Go de données), pour atteindre 5 à 6 min de traitement pour un facteur 50 (10 Go).
A l’inverse, les performances de Druid sont quasi-constantes, avec 1,2 sec de temps total pour un facteur 2 (400 Mo), et 2,1 pour un facteur 50 (10Go).
Conclusion
Si Hive s’etait récemment vu doté d’un moteur de cache (LLAP) capable de répondre à une requete en moins d’une seconde, les capacités BI étaient limités à la consultation de données précalculées. En effet, toute requête non précalculées, dont le résultat n’est pas en cache, sera intégralement calculé via le moteur TEZ.
A l’inverse, si l’utilisation de Druid et Hive nécessite actuellement un export batch qui peut être long, Druid permet à la fois de :
- desservir très rapidement une dimension via son stockage orienté timeseries
- en fournir son résultat aggrégé, car ces indicateurs sont maintenus par Druid
Le couple Hive + Druid semble enfin proposer une solution complète permettant de brancher son outil de BI sur un cluster Hadoop.
Cependant :
- L’intégration entre les 2 composants est complexe
- Druid est un composant dont la configuration est hardue et mal documenté
- Il y a actuellement peu de retours d’expérience, hors preuve de concept
Nous ne pouvons donc pas conclure que c’est une solution mature et clé en main, mais elle est d’hors et déjà en capacité de résoudre des cas d’usage exigeants adaptés à des utilisateurs expérimentés. De plus, c’est un couple prometteur à l’avenir à mesure qu’il deviendra mature et plus facile de prise en main.
