


Installation d'Hadoop depuis le code source : build, patch et exécution

4 août 2020
- Catégories
- Big Data
- Infrastructure
- Tags
- Maven
- Java
- LXD
- Hadoop
- HDFS
- Docker
- TDP
- Tests unitaires [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Les distributions commerciales d’Apache Hadoop ont beaucoup évolué ces dernières années. Les deux concurrents Cloudera et Hortonworks ont fusionné : HDP ne sera plus maintenu et CDH devient CDP. HP a fait l’acquisition de MapR et IBM BigInsights a été abandonné.
Note : Depuis la publication de cet article, Microsoft a annoncé qu’ils développaient un fork de HDP 3.1.6.2 nommé “HDInsight-4.1.0.26”. Cette version étant automatiquement choisie lors du provisionnement d’un cluster Azure HDInsight.
Certaines de ces entreprises sont d’importants contributeurs du projet Apache Hadoop et leurs clients font appels à elles pour être certains d’avoir une distribution Hadoop (ainsi que d’autres logiciels de l’écosystème Big Data) stable, testée et sécurisée. Le projet Hadoop a désormais plus de dix ans d’existence, des milliers de commits, des dizaines de dépendances et une architecture complexe. Cela nous amène à la question : À quel point est-ce compliqué de compiler Hadoop en 2020 ?
Nous allons, dans cet article, parcourir les différentes étapes de compilation, test, patching et lancement d’un cluster Hadoop en partant du code source.
Préparation de l’environement de build
La première étape est d’effectuer un git clone du repository Apache Hadoop :
git clone https://github.com/apache/hadoop.git && cd hadoopNous pouvons remarquer qu’il y a un fichier start-build-env.sh à la racine du projet. Il s’agit d’un script très pratique qui build et lance un container Docker dans lequel sont installés tous les pré-requis nécessaires pour compiler et tester Hadoop. Cette image Docker est basée sur Ubuntu 18.04. Le fait d’avoir un container de build “officiel” est une excellente chose pour un projet open source. En effet, cela permet d’aider les nouveaux développeurs à contribuer plus facilement mais également les mainteneurs du projets à reproduire les bugs de manière plus efficace grâce à un environment de travail contrôlé.
À la fin du script start-build-env.sh, le container est démarré avec les propriétés suivantes :
docker run --rm=true $DOCKER_INTERACTIVE_RUN \
-v "${PWD}:/home/${USER_NAME}/hadoop${V_OPTS:-}" \
-w "/home/${USER_NAME}/hadoop" \
-v "${HOME}/.m2:/home/${USER_NAME}/.m2${V_OPTS:-}" \
-v "${HOME}/.gnupg:/home/${USER_NAME}/.gnupg${V_OPTS:-}" \
-u "${USER_ID}" \
"hadoop-build-${USER_ID}" "$@"Compilation d’Hadoop sans lancer les tests
Essayons maintenant de compiler Hadoop dans notre environement de build. La dernière version publiée d’Hadoop à la parution de cet article était la 3.3.0, nous allons donc builder celle-ci. Toutes les releases sont marquées dans le repo git par un tag :
git checkout rel/release-3.3.0Le fichier BUILDING.txt à la racine du projet indique quelques exemples de command Maven dont on peut s’inspirer. Essayons la première :
# Create binary distribution without native code and without documentation:
mvn package -Pdist -DskipTests -Dtar -Dmaven.javadoc.skip=trueLe paramètre -DskipTests, comme son nom l’indique, build le projet sans lancer les tests unitaires définis dans le code. -Pdist et -Dtar sont les paramètres à utiliser pour créer la distribution dans une archive .tar.gz comme celles disponibles sur la page release sur site d’Apache Hadoop. Enfin, le paramètre -Dmaven.javadoc.skip=true indique que l’on ne souhaite pas inclure la documentation dans la distribution.
Ces options permettent de builder le projet rapidement. Après quelques minutes, voici l’output de la commande précédente :
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 12:54 min
[INFO] Finished at: 2020-07-21T12:41:50Z
[INFO] ------------------------------------------------------------------------Le build et la compression de la distribution ont bien eu lieu mais où est le fichier .tar.gz ? Le sous-dossier hadoop-dist est le module maven associé au build de la distribution, c’est donc dans ce dossier, sous target que nous trouvons l’archive :
➜ hadoop git:(aa96f1871bf) ✗ ls -alh ./hadoop-dist/target/hadoop-3.3.0.tar.gz
-rw-r--r-- 1 leo leo 431M Jul 27 14:42 ./hadoop-dist/target/hadoop-3.3.0.tar.gzL’achive est également disponible en dehors du container de build car le dossier source Hadoop était monté dans le container Docker (voir la commande docker run précédente) à partir de la machine hôte.
Lancement des tests unitaires
Nous venons de voir comment packager une release mais nous n’avons pas fait tourner les tests. Nous avons buildé la versions 3.3.0 telle quelle, si l’on avait corrigé un bug ou ajouter une feature, il deviendrait obligatoire de s’assurer que les tests sont OK avant de créer la release.
Pour cela, continuons d’utiliser le container Docker de build. La première commande (la même que la précédente mais en elevant -DskipTests) que nous avons essayé a été celle ci :
mvn package -Pdist -Dtar -Dmaven.javadoc.skip=trueHadoop est un projet à l’architecture très complexe. Il est composé de plusieurs sous-modules Maven qui sont décris dans le fichier BUILDING.txt. Parmis eux nous pouvons citer hadoop-common-project, hadoop-hdfs-project ou hadoop-yarn-project.
Par soucis de simplicité, nous allons uniquement lancer les tests du sous-module hadoop-hdfs-project qui contient le code des composants majeurs d’HDFS : Namenode, Datanode, etc. Il y a plus de 700 tests unitaires définis dans ce sous-module.
cd hadoop-hdfs-project && mvn package -Pdist -Dtar -Dmaven.javadoc.skip=trueL’un des premiers tests échoue après seulement quelques minutes d’exécution :
[ERROR] testExcludedNodesForgiveness(org.apache.hadoop.hdfs.TestDFSClientExcludedNodes) Time elapsed: 2.727 s <<< ERROR!
java.lang.IllegalStateException: failed to create a child event loop
at io.netty.util.concurrent.MultithreadEventExecutorGroup.(MultithreadEventExecutorGroup.java:88)
...
Caused by: io.netty.channel.ChannelException: failed to open a new selector
at io.netty.channel.nio.NioEventLoop.openSelector(NioEventLoop.java:175)
... 28 more
Caused by: java.io.IOException: Too many open files
at sun.nio.ch.IOUtil.makePipe(Native Method)
... L’erreur Too many open files nous indique que le paramètrage ulimit de l’utilisateur qui exécute Maven est trop bas.
Après avoir augmenté les limites de l’utilisateur, il faut relancer le container de build avec l’option --ulimit pour que celle-ci soit prise en compte dans le container :
docker run --rm=true -i -t -v /home/leo/Apache/hadoop:/home/leo/hadoop -w /home/leo/hadoop -v /home/leo/.m2:/home/leo/.m2 -v /home/leo/.gnupg:/home/leo/.gnupg -u 1000 --ulimit nofile=500000:500000 hadoop-build-1000Nous pouvons relancer la commande de test et s’apercevoir que le test qui avait provoqué l’erreur passe désormais :
[INFO] Running org.apache.hadoop.hdfs.TestDFSClientExcludedNodes
[INFO] Tests run: 2, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 9.247 s - in org.apache.hadoop.hdfs.TestDFSClientExcludedNodesCe fut long mais les tests de hadoop-hdfs-project ont tous été lancés. Après quelques heures, nous obtenons la sortie suivante :
[INFO] Reactor Summary for Apache Hadoop HDFS Project 3.3.0:
[INFO]
[INFO] Apache Hadoop HDFS Client .......................... SUCCESS [01:16 min]
[INFO] Apache Hadoop HDFS ................................. SUCCESS [ 04:47 h]
[INFO] Apache Hadoop HDFS Native Client ................... SUCCESS [ 2.420 s]
[INFO] Apache Hadoop HttpFS ............................... SUCCESS [02:59 min]
[INFO] Apache Hadoop HDFS-NFS ............................. SUCCESS [01:39 min]
[INFO] Apache Hadoop HDFS-RBF ............................. SUCCESS [21:35 min]
[INFO] Apache Hadoop HDFS Project ......................... SUCCESS [ 0.058 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 05:14 h
[INFO] Finished at: 2020-07-27T18:32:20Z
[INFO] ------------------------------------------------------------------------Il y a plus de 700 tests définis rien que dans le sous-module hadoop-hdfs-project mais nous pouvons admettre que cinq heures de tests, c’est un peu long. Nous avons alors décidé de chercher dans le Jenkins de la fondation Apache pour voir comment les tests d’HDFS sont lancés.
L’équipe des Hadoop PMC (pour Project Management Committee) utilise le projet Apache Yetus pour lancer les tests après chaque pull request soumise sur GitHub. Par exemple, cette pull request a déclenché ce build Jenkins. Dans les logs, on peut constater que les tests sont lancés avec le paramètre -Pparallel-tests. Cette option Maven est configurée dans le ./hadoop-hdfs-project/hadoop-hdfs/pom.xml.
Essayons maintenant de re-packager notre release en lançant cette fois ci les tests en parallèle :
mvn package -Pdist -Dtar -Pparallel-tests -Dmaven.javadoc.skip=true
...
[INFO] Reactor Summary for Apache Hadoop HDFS Project 3.3.0:
[INFO]
[INFO] Apache Hadoop HDFS Client .......................... SUCCESS [01:17 min]
[INFO] Apache Hadoop HDFS ................................. SUCCESS [ 01:26 h]
[INFO] Apache Hadoop HDFS Native Client ................... SUCCESS [ 2.095 s]
[INFO] Apache Hadoop HttpFS ............................... SUCCESS [02:41 min]
[INFO] Apache Hadoop HDFS-NFS ............................. SUCCESS [01:31 min]
[INFO] Apache Hadoop HDFS-RBF ............................. SUCCESS [06:04 min]
[INFO] Apache Hadoop HDFS Project ......................... SUCCESS [ 0.045 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 01:37 h
[INFO] Finished at: 2020-07-28T16:23:22Z
[INFO] ------------------------------------------------------------------------Le résultat est probant, le temps d’exécution des tests a fortement diminué pour passer à un peu plus d’une heure et demie.
Compilation d’Hadoop avec un patch
La version d’Hadoop que nous venons de packager est la 3.3.0. Imaginons maintenant que nous ayons besoin des améliorations décrites dans le JIRA HDFS-15160. Un patch est disponible dans l’issue, voyons si nous arrivons à l’appliquer, lancer les tests et créer une nouvelle release comprenant ce fix.
La récupération et l’application du patch sont plutôt simples :
wget https://issues.apache.org/jira/secure/attachment/13006188/HDFS-15160.008.patch
git apply HDFS-15160.008.patchIl va nous falloir être capable de différencier notre nouvelle release du précédent build, pour cela essayons de changer le numéro de version défini dans le pom.xml de chaque sous-module Maven en le passant de la 3.3.0 à la 3.3.1. Le numéro de version est présent un certain nombre de fois mais un “goal” Maven permet de modifier tous les pom.xml en une seule commande :
mvn versions:set -DnewVersion=3.3.1Une fois la commande passée, nous pouvons lancer la même commande de création de distribution que précedemment : mvn package -Pdist -Dtar -Pparallel-tests -Dmaven.javadoc.skip=true. Celle-ci échoue rapidement avec l’erreur suivante :
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-enforcer-plugin:3.0.0-M1:enforce (enforce-property) on project hadoop-main: Some Enforcer rules have failed. Look above for specific messages explaining why the rule failed. -> [Help 1]Dans le pom.xml racine du projet, nous pouvons constater que le plugin Maven suivant est défini :
<execution>
<id>enforce-property</id>
<goals>
<goal>enforce</goal>
</goals>
<configuration>
<rules>
<requireProperty>
<property>hadoop.version</property>
<message>You must set a hadoop.version to be the same as ${project.version}</message>
<regex>${project.version}</regex>
<regexMessage>The hadoop.version property should be set and should be ${project.version}.</regexMessage>
</requireProperty>
</rules>
<fail>true</fail>
</configuration>
</execution>Dans notre cas, remplacer les tags
<hadoop.version>3.3.1</hadoop.version>Après ce dernier changement, les tests et le build se déroulent sans accrocs et la distribution est disponible dans le fichier : ./hadoop-dist/target/hadoop-3.3.1.tar.gz.
Installation de la distribution
Maintenant que nous disposons d’une distribution Hadoop testée et packagée, essayons de faire un tourner un cluster Hadoop minimal (1 Namenode et 1 Datanode) en se basant sur la documentation “cluster setup instruction”. Nous allons ici installer Hadoop dans des containers LXD.
La première étape est de lancer deux containers LXD qui vont nous servir de Namenode et de Datanode :
lxc launch images:centos/7 hdfsnamenode
lxc launch images:centos/7 hdfsdatanodeEnsuite, nous téléchargeons notre distribution Hadoop au format .tar.gz dans les containers et les décompressons dans /opt :
lxc file push ./hadoop-dist/target/hadoop-3.3.1.tar.gz hdfsdatanode/opt/hadoop-3.3.1.tar.gz
lxc file push ./hadoop-dist/target/hadoop-3.3.1.tar.gz hdfsnamenode/opt/hadoop-3.3.1.tar.gz
lxc exec hdfsdatanode -- tar -xzf /opt/hadoop-3.3.1.tar.gz -C /opt
lxc exec hdfsnamenode -- tar -xzf /opt/hadoop-3.3.1.tar.gz -C /optJava est un pré-requis pour faire tourner Hadoop, nous installons ici la version OpenJDK :
lxc exec hdfsdatanode -- yum install -y java
lxc exec hdfsnamenode -- yum install -y javaAvant de lancer Hadoop, il faut appliquer une configuration fonctionnelle minimale. Nous voulons uniquement que le Datanode soit capable de s’enregistrer au Namenode. Pour cela, il faut avoir la propritété fs.defaultFS dans le fichier core-site.xml. La commande suivante créer ce fichier et le positionne au bon endroit dans les containers LXD :
cat <<EOF > /tmp/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdfsnamenode.lxd:9000</value>
</property>
</configuration>
EOF
lxc file push /tmp/core-site.xml hdfsdatanode/opt/hadoop-3.3.1/etc/hadoop/core-site.xml
lxc file push /tmp/core-site.xml hdfsnamenode/opt/hadoop-3.3.1/etc/hadoop/core-site.xmlTout est prêt, nous pouvons démarrer les daemons Namenode et Datanode :
lxc exec hdfsnamenode --env JAVA_HOME=/usr/lib/jvm/jre -- /opt/hadoop-3.3.1/bin/hdfs namenode -format
lxc exec hdfsnamenode --env JAVA_HOME=/usr/lib/jvm/jre -T -- /opt/hadoop-3.3.1/bin/hdfs --daemon start namenode
lxc exec hdfsdatanode --env JAVA_HOME=/usr/lib/jvm/jre -T -- /opt/hadoop-3.3.1/bin/hdfs --daemon start datanodeLe paramètre --env est nécéssaire pour que la commande HDFS puisse trouver notre installation de Java. Le paramètre -T indique que la commande sera lancée dans un terminal non-interactif.
La WebUI du Namenode est accessible à l’adresse http://hdfsnamenode.lxd:9870 :
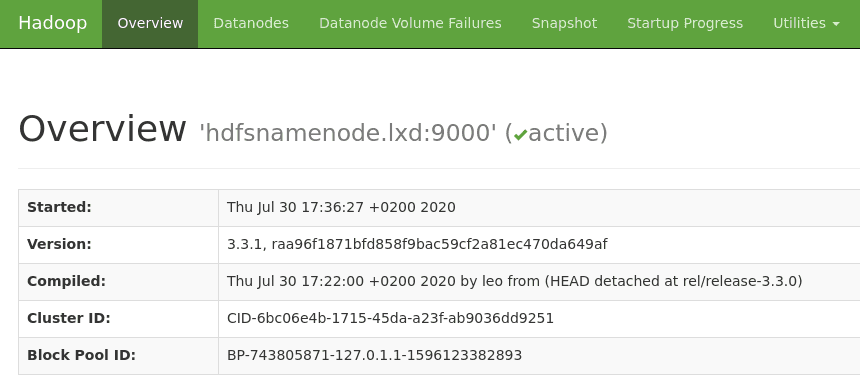
Dans l’onglet “Datanodes”, nous pouvons constater que le Datanode s’est bien enregistré auprès du Namenode :
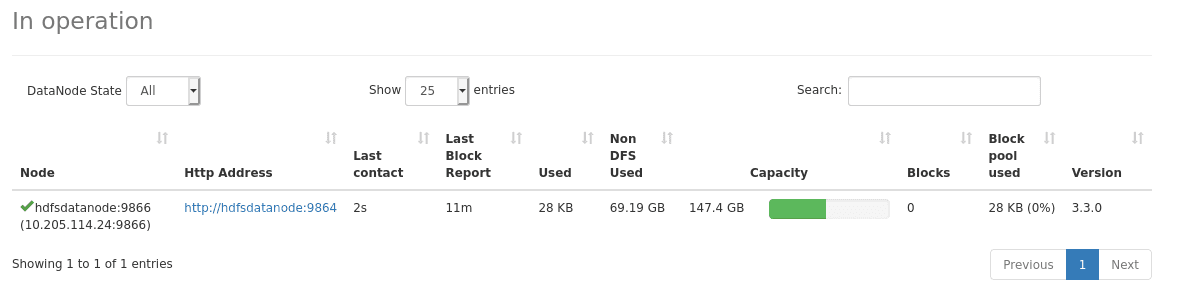
Enfin nous pouvons essayer HDFS pour voir si ce dernier fonctionne correctement. Pour cela, nous allons écrire et lire un fichier avec WebHDFS :
curl -L -X PUT "http://hdfsnamenode.lxd:9870/webhdfs/v1/README.txt?op=CREATE&user.name=root"
curl -L "http://hdfsnamenode.lxd:9870/webhdfs/v1/README.txt?op=OPEN&user.name=root"
For the latest information about Hadoop, please visit our website at:
http://hadoop.apache.org/
and our wiki, at:
https://cwiki.apache.org/confluence/display/HADOOP/
