


Installing Hadoop from source: build, patch and run

Aug 4, 2020
- Categories
- Big Data
- Infrastructure
- Tags
- Maven
- Java
- LXD
- Hadoop
- HDFS
- Docker
- TDP
- Unit tests [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Commercial Apache Hadoop distributions have come and gone. The two leaders, Cloudera and Hortonworks, have merged: HDP is no more and CDH is now CDP. MapR has been acquired by HP and IBM BigInsights has been discontinued.
Note: Since the publication of this article, Microsoft announced that they developed a fork of HDP 3.1.6.2 called “HDInsight-4.1.0.26”. This version is now automatically picked while provisioning an Azure HDInsight cluster.
Some of these organizations are important contributors of the Apache Hadoop project and their clients rely on them to get a secure, tested and stable Hadoop (and other software of the Big Data ecosystem) builds. Hadoop is now a decade old project with thousands of commits, dozens of dependencies and a complex architecture. This got us thinking: How hard is it to build and run Hadoop from source in 2020?
In this article we will go through the process of building, testing, patching and running a minimal working Hadoop cluster from the Apache Hadoop source code. All the commands shown below can be scripted for automation purposes.
Prepare the build environment
The first thing we will do is to git clone the Apache Hadoop repository:
git clone https://github.com/apache/hadoop.git && cd hadoopNotice the start-build-env.sh file at the root of the project. It is a very convenient script that builds and runs a Docker container in which everything needed for building and testing Hadoop is included. The Docker image is based on Ubuntu 18.04. Having an “official” building container is a really great addition to any open source project, it helps both new developers on their journey to a first contribution as well as maintainers to reproduce issues more easily by providing a controlled and reproducible environment.
At the end of the start-build-env.sh script, the container is started with the following properties:
docker run --rm=true $DOCKER_INTERACTIVE_RUN \
-v "${PWD}:/home/${USER_NAME}/hadoop${V_OPTS:-}" \
-w "/home/${USER_NAME}/hadoop" \
-v "${HOME}/.m2:/home/${USER_NAME}/.m2${V_OPTS:-}" \
-v "${HOME}/.gnupg:/home/${USER_NAME}/.gnupg${V_OPTS:-}" \
-u "${USER_ID}" \
"hadoop-build-${USER_ID}" "$@"Building Hadoop without running the tests
Let’s now try to build Hadoop from within the build environment. The latest Hadoop release at the time of writing was the 3.3.0 so we will build this one. All the releases are tags inside the git repository:
git checkout rel/release-3.3.0The BUILDING.txt file at the root of the project gives us a few build commands with Maven as examples. Let’s try out the first one:
# Create binary distribution without native code and without documentation:
mvn package -Pdist -DskipTests -Dtar -Dmaven.javadoc.skip=trueThe -DskipTests parameter, as the name suggests makes a build without running the unit tests. -Pdist and -Dtar are the parameters we use to produce a distribution with a .tar.gz file extension like the one we obtain from downloading the latest build on the Apache Hadoop release page. Finally, -Dmaven.javadoc.skip=true is there to exclude the documentation from the build.
These options contribute to speed up the build process. After a few minutes, here is the output of the command:
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 12:54 min
[INFO] Finished at: 2020-07-21T12:41:50Z
[INFO] ------------------------------------------------------------------------The building and packaging of the distribution is done but where is our .tar.gz file? It is located in the hadoop-dist (for Hadoop distribution assembler) maven module under the target folder:
➜ hadoop git:(aa96f1871bf) ✗ ls -alh ./hadoop-dist/target/hadoop-3.3.0.tar.gz
-rw-r--r-- 1 leo leo 431M Jul 27 14:42 ./hadoop-dist/target/hadoop-3.3.0.tar.gzThe .tar.gz is also available outside of the docker container because the Hadoop source directory was mounted in the docker run command.
Running the unit tests
We have just seen how to build a release but we did not run any tests. We built the official 3.3.0 release as is but if we were to fix a bug or add a feature, it becomes critical to make sure the tests are running properly before making our release.
We will keep using the docker image provided in the Hadoop project to run the tests. Our first attempt at building with the test running was done with this command (same as the previous one, only removing the -DskipTests):
mvn package -Pdist -Dtar -Dmaven.javadoc.skip=trueHadoop is a big and complex project. Therefore, it is split into multiple maven modules as described in the BUILDING.txt file of the repository. Among all the modules, we can cite hadoop-common-project, hadoop-hdfs-project or hadoop-yarn-project.
For simplicity’s sake, we will only run the tests of hadoop-hdfs-project which contains the core code for its components such as the Namenode, the Datanode, etc. There are more than 700 unit tests defined in this submodule only.
cd hadoop-hdfs-project && mvn package -Pdist -Dtar -Dmaven.javadoc.skip=trueOne of the tests failed after a few minutes with the following error:
[ERROR] testExcludedNodesForgiveness(org.apache.hadoop.hdfs.TestDFSClientExcludedNodes) Time elapsed: 2.727 s <<< ERROR!
java.lang.IllegalStateException: failed to create a child event loop
at io.netty.util.concurrent.MultithreadEventExecutorGroup.(MultithreadEventExecutorGroup.java:88)
...
Caused by: io.netty.channel.ChannelException: failed to open a new selector
at io.netty.channel.nio.NioEventLoop.openSelector(NioEventLoop.java:175)
... 28 more
Caused by: java.io.IOException: Too many open files
at sun.nio.ch.IOUtil.makePipe(Native Method)
... The Too many open files indicates us that the user’s (running Maven) ulimit are too low.
After increasing the ulimit, we can run the container again with the --ulimit docker flag to set the new upper limit inside the container:
docker run --rm=true -i -t -v /home/leo/Apache/hadoop:/home/leo/hadoop -w /home/leo/hadoop -v /home/leo/.m2:/home/leo/.m2 -v /home/leo/.gnupg:/home/leo/.gnupg -u 1000 --ulimit nofile=500000:500000 hadoop-build-1000The testing can now proceed and we can see in the output logs that the test which failed because of the ulimit is now passing:
[INFO] Running org.apache.hadoop.hdfs.TestDFSClientExcludedNodes
[INFO] Tests run: 2, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 9.247 s - in org.apache.hadoop.hdfs.TestDFSClientExcludedNodesIt took a while but the tests for the hadoop-hdfs-project sub modules all passed. After a few hours, we obtained the following output:
[INFO] Reactor Summary for Apache Hadoop HDFS Project 3.3.0:
[INFO]
[INFO] Apache Hadoop HDFS Client .......................... SUCCESS [01:16 min]
[INFO] Apache Hadoop HDFS ................................. SUCCESS [ 04:47 h]
[INFO] Apache Hadoop HDFS Native Client ................... SUCCESS [ 2.420 s]
[INFO] Apache Hadoop HttpFS ............................... SUCCESS [02:59 min]
[INFO] Apache Hadoop HDFS-NFS ............................. SUCCESS [01:39 min]
[INFO] Apache Hadoop HDFS-RBF ............................. SUCCESS [21:35 min]
[INFO] Apache Hadoop HDFS Project ......................... SUCCESS [ 0.058 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 05:14 h
[INFO] Finished at: 2020-07-27T18:32:20Z
[INFO] ------------------------------------------------------------------------There are currently more than 700 tests in the hadoop-hdfs-project submodule but five hours is a bit long. We decided to look around the Apache Foundation Jenkins to see how the tests for HDFS are run.
The Hadoop PMC (Project Management Committee) team uses Apache Yetus to make a test run after every pull request on GitHub. For example this pull request triggered this Jenkins build. In the output logs, we can see that the tests are launched with the -Pparallel-tests parameter. This Maven target is configured in ./hadoop-hdfs-project/hadoop-hdfs/pom.xml.
Let’s try to package our release again with the tests running in parallel:
mvn package -Pdist -Dtar -Pparallel-tests -Dmaven.javadoc.skip=true
...
[INFO] Reactor Summary for Apache Hadoop HDFS Project 3.3.0:
[INFO]
[INFO] Apache Hadoop HDFS Client .......................... SUCCESS [01:17 min]
[INFO] Apache Hadoop HDFS ................................. SUCCESS [ 01:26 h]
[INFO] Apache Hadoop HDFS Native Client ................... SUCCESS [ 2.095 s]
[INFO] Apache Hadoop HttpFS ............................... SUCCESS [02:41 min]
[INFO] Apache Hadoop HDFS-NFS ............................. SUCCESS [01:31 min]
[INFO] Apache Hadoop HDFS-RBF ............................. SUCCESS [06:04 min]
[INFO] Apache Hadoop HDFS Project ......................... SUCCESS [ 0.045 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 01:37 h
[INFO] Finished at: 2020-07-28T16:23:22Z
[INFO] ------------------------------------------------------------------------Much better, the parallel execution drastically decreased the testing time to an hour and a half.
Building Hadoop with a patch
The Hadoop version we just built and packaged is the 3.3.0. Let’s say we need the improvement from the HDFS-15160 issue. A patch is available in the JIRA issue, let’s see if we can apply it, run the tests and package a new release with this fix.
Getting and applying the patch is straightforward:
wget https://issues.apache.org/jira/secure/attachment/13006188/HDFS-15160.008.patch
git apply HDFS-15160.008.patchWe will want to differentiate this version from our previous build, let’s change the version in all the pom.xml of every submodules from 3.3.0 to 3.3.1. The version number is mentioned a lot of times but a practical mvn goal changes every pom.xml in a single command:
mvn versions:set -DnewVersion=3.3.1After that, we can start the same package command we ran earlier (mvn package -Pdist -Dtar -Pparallel-tests -Dmaven.javadoc.skip=true). It fails early with the following error:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-enforcer-plugin:3.0.0-M1:enforce (enforce-property) on project hadoop-main: Some Enforcer rules have failed. Look above for specific messages explaining why the rule failed. -> [Help 1]Looking at the root pom.xml of the project, we can find the Maven plugin defined as:
<execution>
<id>enforce-property</id>
<goals>
<goal>enforce</goal>
</goals>
<configuration>
<rules>
<requireProperty>
<property>hadoop.version</property>
<message>You must set a hadoop.version to be the same as ${project.version}</message>
<regex>${project.version}</regex>
<regexMessage>The hadoop.version property should be set and should be ${project.version}.</regexMessage>
</requireProperty>
</rules>
<fail>true</fail>
</configuration>
</execution>In our case, replacing the
<hadoop.version>3.3.1</hadoop.version>After changing this, the tests and build run correctly without issues and the distribution is available at ./hadoop-dist/target/hadoop-3.3.1.tar.gz.
Installing the distribution
Once we have a Hadoop distribution tested and packaged, let’s now try to install a minimal running Hadoop cluster (1 NameNode and 1 DataNode) using the documentation’s cluster setup instruction. We will be installing Hadoop in LXD containers.
The first step is to spin up two LXD containers, which will be our NameNode and DataNode:
lxc launch images:centos/7 hdfsnamenode
lxc launch images:centos/7 hdfsdatanodeThen we will upload our Hadoop distribution .tar.gz to the containers and extract it in /opt:
lxc file push ./hadoop-dist/target/hadoop-3.3.1.tar.gz hdfsdatanode/opt/hadoop-3.3.1.tar.gz
lxc file push ./hadoop-dist/target/hadoop-3.3.1.tar.gz hdfsnamenode/opt/hadoop-3.3.1.tar.gz
lxc exec hdfsdatanode -- tar -xzf /opt/hadoop-3.3.1.tar.gz -C /opt
lxc exec hdfsnamenode -- tar -xzf /opt/hadoop-3.3.1.tar.gz -C /optJava needs to be installed, we will go for OpenJDK:
lxc exec hdfsdatanode -- yum install -y java
lxc exec hdfsnamenode -- yum install -y javaBefore actually starting Hadoop, we need to apply a minimal working configuration. Since we only care about the Datanode finding the Namenode, the only configuration we need in the core-site.xml is fs.defaultFS. The next commands create this file and send it to the LXD containers:
cat <<EOF > /tmp/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdfsnamenode.lxd:9000</value>
</property>
</configuration>
EOF
lxc file push /tmp/core-site.xml hdfsdatanode/opt/hadoop-3.3.1/etc/hadoop/core-site.xml
lxc file push /tmp/core-site.xml hdfsnamenode/opt/hadoop-3.3.1/etc/hadoop/core-site.xmlWe are all set and can start both NameNode and Datanode daemons:
lxc exec hdfsnamenode --env JAVA_HOME=/usr/lib/jvm/jre -- /opt/hadoop-3.3.1/bin/hdfs namenode -format
lxc exec hdfsnamenode --env JAVA_HOME=/usr/lib/jvm/jre -T -- /opt/hadoop-3.3.1/bin/hdfs --daemon start namenode
lxc exec hdfsdatanode --env JAVA_HOME=/usr/lib/jvm/jre -T -- /opt/hadoop-3.3.1/bin/hdfs --daemon start datanodeThe --env parameter is mandatory for the HDFS command to find where Java is installed. The -T parameter makes LXD run the command in a non-interactive terminal.
The Namenode’s WebUI is now reachable at http://hdfsnamenode.lxd:9870:
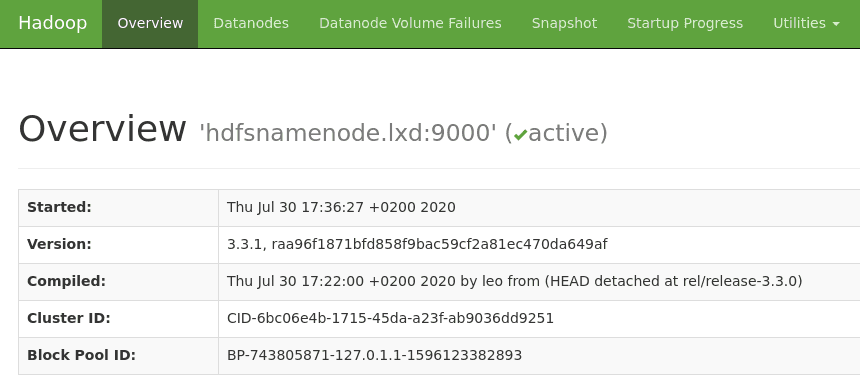
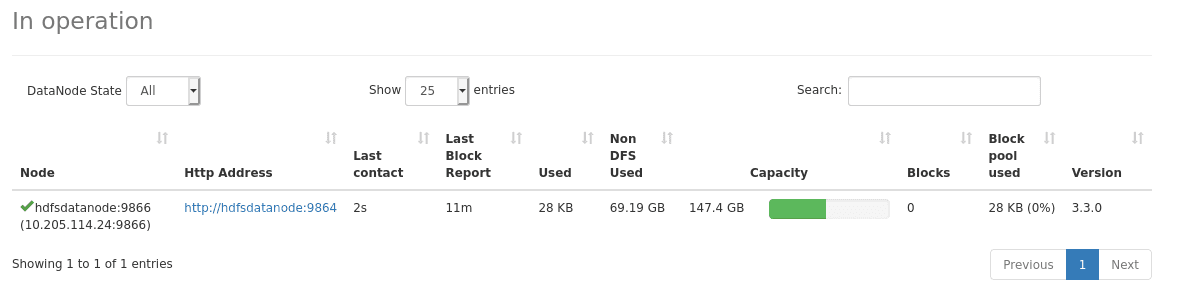
In the “Datanodes” tab, we can see that the Datanode is registered correctly to the Namenode:
We can also test if HDFS is working properly by putting a file and reading it with WebHDFS:
curl -L -X PUT "http://hdfsnamenode.lxd:9870/webhdfs/v1/README.txt?op=CREATE&user.name=root"
curl -L "http://hdfsnamenode.lxd:9870/webhdfs/v1/README.txt?op=OPEN&user.name=root"
For the latest information about Hadoop, please visit our website at:
http://hadoop.apache.org/
and our wiki, at:
https://cwiki.apache.org/confluence/display/HADOOP/
