


Architecture du stockage objet et attributs du standard S3

By BIGOT Luka
20 juin 2022
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Le stockage objet a gagné en popularité parmi les architectures de stockage de données. Comparé aux systèmes de fichiers et au stockage bloc, le stockage objet ne rencontre pas de limitations lorsqu’il s’agit de traiter des pétaoctets de données. Par essence, sa flexibilité en quantité de stockage en fait un candidat idéal pour les utilisations Big Data et Cloud.
De plus, le stockage objet est simple et efficace. Il offre la possibilité de répliquer les données, assure la scalabilité et permet une utilisation en “Write Once Read Many” : des données sont insérées une fois, modifiées rarement et accédées plusieurs fois par la suite, ce qui est le cas lorsque l’on fait de l’analyse de données. Ces caractéristiques, combinées avec la facilité d’implémentation et de programmation contribuent à l’utilisation largement répandue du stockage objet.
Qu’est-ce qu’un objet ? Comment fonctionne le stockage objet, et qu’est-ce qui le rend scalable ? C’est ce que nous allons clarifier.
Le stockage objet n’est pas exclusif aux services Cloud comme AWS Simple Storage Service (S3), et de multiples solutions de stockage objet local existent comme alternatives. C’est parce que AWS S3 a érigé un standard pour les APIs de stockage objet que les solutions de stockage ainsi que les applications qui en tirent parti sont fédérées sous la bannière de la compatibilité S3. Toute application compatible S3 fonctionne avec n’importe quel stockage compatible S3 et réciproquement.
Cet article est le premier d’une série de trois :
- Architecture des stockages objets et attributs du standard S3
- Stockage objet avec MinIO dans un cluster Kubernetes
- Stockage objet Ceph dans un cluster Kubernetes avec Rook
Stockage objet : Comment ça fonctionne, pourquoi c’est scalable
Comme son nom l’indique, le stockage objet contient des données sous forme d’objets. Le paradigme du stockage objet est d’optimiser les opérations sur les données et métadonnées en les fusionnant. De quoi est fait un objet ?
C’est la combinaison d’une clé (permettant l’accès), d’une valeur (des données) et des métadonnées associées : celles propres à l’objet ainsi que des métadonnées supplémentaires ajoutées par le stockage objet pour la gestion de grands volumes d’objets. Les métadonnées sont stockées au même endroit que la donnée, contrairement aux systèmes de fichiers. La clé utilisée pour accéder à un objet est générée par le stockage objet et correspond au nom, au chemin d’accès et à l’ID unique d’un objet (OID).
Les métadonnées jouent un rôle crucial dans le stockage objet en permettant l’abstraction de la hiérarchie que l’on peut trouver dans les systèmes de fichiers. Dans le stockage objet, tout est stocké sous forme de dépôt horizontal, sans arborescence de fichier. L’indexation et la gestion sont totalement gérés par l’utilisation des propriétés des métadonnées.
Des métadonnées personnalisées peuvent être ajoutées aux objets, permettant de la flexibilité dans l’analyse de données. Elles permettent également le contrôle de la réplication des données.
Les périphériques de stockage objet, en anglais Object Storage Devices (OSDs), sont les périphériques physiques qui supportent le stockage effectif et sont soit des disques dédiés, soit des partitions dédiées au sein des disques. Les OSDs peuvent être de différents types, et appartiennent à un ou plusieurs espaces de stockage, appelés “pools”. Ces pools sont des divisions logiques de données, contiennent les objets et sont répliquées parmi les multiples OSDs comme indiqué sur le diagramme suivant.
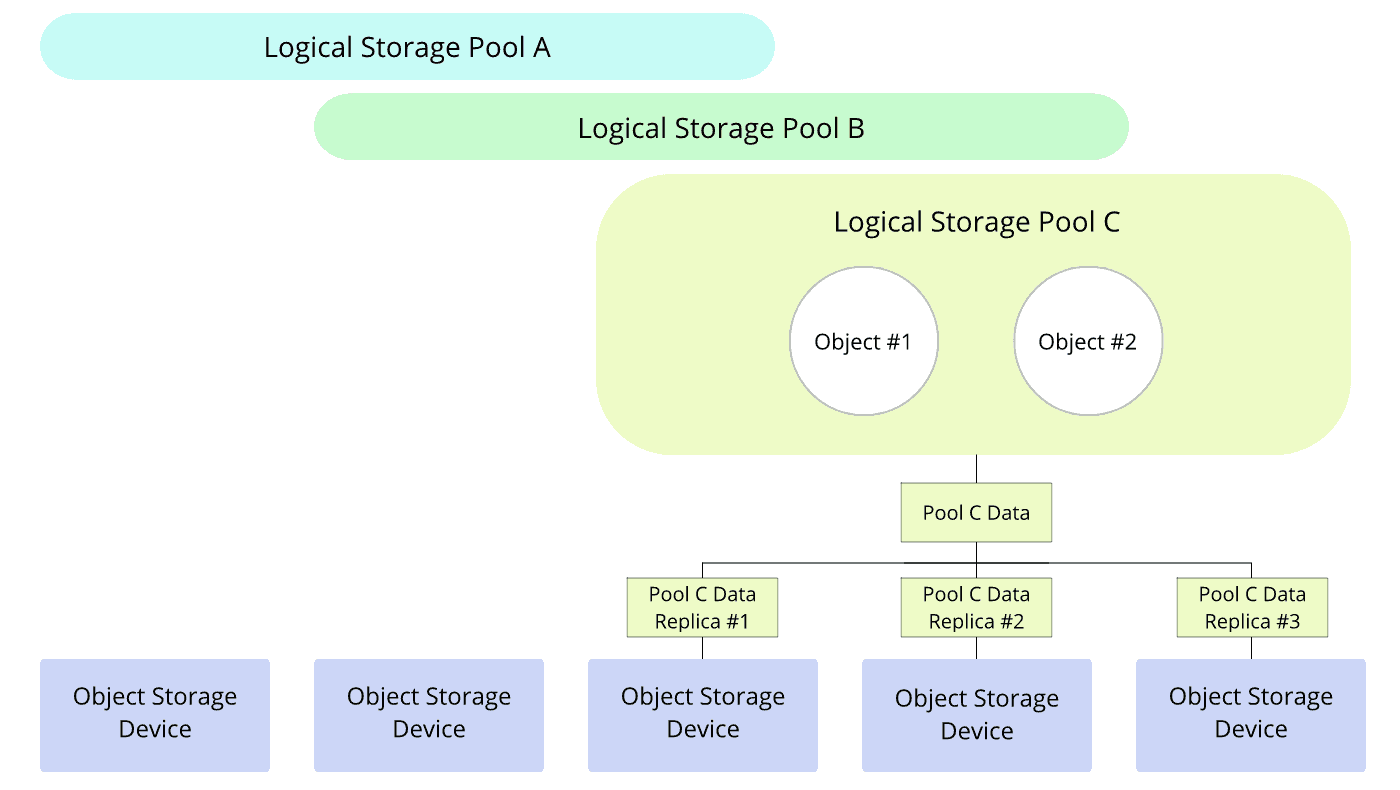
Grâce à cette réplication des données à travers de multiples périphériques, le stockage objet permet :
- La haute-disponibilité, s’assurant une latence faible pour les requêtes et évitant le bottleneck sur un périphérique occupé ;
- La résilience et le basculement en cas de défaillance du disque ;
- La scalabilité, laissant la possibilité d’ajouter un nombre infini d’OSDs.
L’avantage du stockage objet, c’est que l’on peut commencer petit puis l’agrandir après : le stockage disponible et le nombre d’OSDs peut être étendu sans risquer d’endommager les données existantes. Le processus est aussi simple que d’ajouter un nouveau nœud avec des disques non formatés dans le cluster, automatiquement intégrés dans les pools de stockage. La suppression d’une OSD est également prise en charge, en copiant les données que le disque contenait sur une autre OSD. De plus, la combinaison du nom de l’objet, le chemin d’accès et l’ID permettent d’éviter la collision de nom.
Cette capacité d’extension du stockage est quasiment infinie. Les performances ne sont pas affectées même lorsque les données atteignent les pétaoctets, et ce grâce à la structure horizontale du stockage objet ainsi que l’utilisation des métadonnées pour l’indexer et le gérer efficacement.
Au bout du compte, le stockage objet est adapté pour de larges volumes de données non structurées, et n’expose jamais son infrastructure de stockage à ses utilisateurs. C’est une architecture adaptée pour les besoins scalables de stockage distribué. Intéressons-nous maintenant à l’interface permettant l’accès à ces données.
L’accès aux données du stockage objet : le standard S3 pour l’API
Différentes implémentations du stockage objet existent, la majorité disposent d’une interface commune : l’API S3.
Avec le stockage objet, le transport de données se fait principalement avec une API HTTP REST. Par le passé, de multiples implémentations propriétaires de ces APIs existaient pour le stockage objet, mais aucune ne fédérait les développeurs. En 2006, AWS Simple Storage Solution (S3) mit en place un terrain d’entente pour l’API, communément accepté par la communauté.
En d’autres termes : le terme S3 sera employé ici pour désigner le standard et non pas le service AWS.
L’API REST S3 est abordable et simple d’utilisation. Elle permet aux utilisateurs d’écrire, de lister, d’obtenir et de supprimer des objets depuis un point d’accès unique, en utilisant des requêtes PUT, GET, etc… Dans le stockage objet, les données sont divisées logiquement au sein de buckets : des partitions de données protégées qui peuvent seulement être accédées par leur utilisateur S3 associé. Le nom du bucket est typiquement un préfixe de l’URI d’une requête S3.
Les utilisateurs S3 peuvent posséder un ou plusieurs buckets, et leur identifiants S3 permettent d’y avoir accès. Les identifiants S3 représentent une paire de clés : une clé d’accès et une clé secrète. Ces deux clés sont confidentielles et donnent accès en écriture, en lecture et permettent la suppression de tout ce qu’un utilisateur possède dans son stockage objet, ce qui veut dire que ces clés doivent absolument être partagées avec précaution.
L’API S3 apporte de nombreux bénéfices :
- Sécurité, comme chaque opération nécessite les identifiants S3 ;
- Confidentialité et isolation des données avec de multiples utilisateurs, chaque utilisateur se voyant confier sa propre partie du stockage ;
- Atomicité de la modification, les écritures et les modifications sont effectuées en une transaction unique.
Le fait que les fournisseurs de stockage et que les utilisateurs s’accordent sur l’utilisation d’un standard commun est un facteur décisif dans le développement et la pérennisation du stockage objet. Le marché des solutions de stockage étant largement fourni, les fournisseurs de stockage et les applications compatibles avec le standard S3 profitent d’une interchangeabilité que ce soit du côté client, ou du côté serveur.
Utilisation du stockage objets à travers les clients S3
L’accès aux objets au sein du stockage est effectué par des programmes, les clients S3. Ces clients sont utilisés par les applications compatibles S3 afin d’interagir avec le stockage. Il existe deux types de clients :
- Les clients en invite de commande (CLI), comme AWS CLI ou s5cmd. s5cmd est open-source, l’un des clients les plus rapides, et la manière recommandée d’accéder au stockage S3 au travers d’une invite de commande. Ce CLI est écrit en Go, et peut soit être utilisé depuis un fichier binaire pré-compilé, compilé depuis la source ou utilisé dans un conteneur Docker ;
- Les AWS SDKs, qui sont les outils de développement permettant aux applications d’effectuer des requêtes sur les stockages objet compatibles S3. Les SDK (Source Development Kit) existent pour de nombreux langages : Java, C++, Python, JavaScript et plus encore.
Schéma d’URI S3
Accéder à un objet en utilisant l’API nécessite le nom de l’objet, le nom du bucket et le nom de la région (spécifique à AWS S3). Ces variables sont concaténées en un URI REST, servant d’identifiant unique pour un objet. Cet URI utilise la famille de schéma s3:// :
s3://: Le protocole obsolète, utilisé pour créer des surcouches de blocs par dessus le stockage S3, et qui ne sera pas utilisé dans ce contexte ;s3n://: Le protocole natif S3, qui supporte les objets de moins de 5 GB ;s3a://: Le successeur de s3n, construit avec AWS SDK. Plus performant, moins limité et l’option recommandée pour le stockage objet.
De plus, il est nécessaire de spécifier un point d’accès. Par défaut, quand le client S3 effectue une requête de ces schémas, elle est retransmise au stockage objet Amazon AWS S3. C’est un paramètre qu’il est nécessaire de modifier quand on utilise d’autres solutions de stockage objet, utilisant leur propre point d’accès. Il est possible de changer le point d’accès dans les paramètres de configuration des applications compatibles S3, ou dans les options du terminal lié à l’application S3.
Utilisation des identifiants pour les clients
Les identifiants doivent être partagés au client afin de pouvoir se connecter à un bucket du stockage objet. Il existe de nombreuses manières pour récupérer ses identifiants, mais les trois méthodes communes sont :
- Avec des variables d’environnement :
AWS_ACCESS_KEY_IDpour la clé d’accès etAWS_SECRET_ACCESS_KEYpour la clé secrète ; - En passant par un fichier
credentials, dans le répertoire~/.aws/credentials; - Dans le fichier
config, dans le répertoire~/.aws/config.
Lorsque l’un des trois est spécifié, le client S3 est capable de se connecter au stockage objet. Il est important de remarquer que les paramètres liés aux identifiants ont un ordre de priorité, avec les variables d’environnement en tête de liste.
Comme ces identifiants donnent accès à toutes les opérations au sein d’un bucket S3, les sécuriser est essentiel. Fournir ces identifiants à travers l’invite de commande n’est pas recommandé, car ils seront visibles sous format texte. Fournir ces identifiants à travers un fichier ou une variable d’environnement sont des méthodes à favoriser. Dans les environnements Kubernetes, les secrets Kubernetes s’occupent de gérer ces identifiants, et de les fournir aux conteneurs qui les demandent de manière sécurisée grâce à env et envFrom, ainsi que secretRef.
Conclusion
Le stockage objet est populaire pour sa simplicité d’utilisation, comme chaque opération sur les fichiers est effectuée à travers une API REST et des requêtes HTTP comme PUT, GET…
Certaines solutions de stockage objet sont disponibles pour les infrastructures locales, et ce en dépit du modèle qui à tendance à être associé au Cloud. Les deux solutions les plus populaires sont open-source et simples à déployer. Elles sont des alternatives sérieuses et convaincantes au stockage objet des fournisseurs de services Cloud, et n’impacteront pas l’utilisateur dans sa manière d’utiliser son stockage objet.
Les deux articles qui viendront compléter la série expliqueront comment héberger un stockage objet au sein d’un cluster Kubernetes local, grâce à Rook et Ceph, ainsi que MinIO.
