


Architecture of object-based storage and S3 standard specifications

By Luka BIGOT
Jun 20, 2022
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Object storage has been growing in popularity among data storage architectures. Compared to file systems and block storage, object storage faces no limitations when handling petabytes of data. By design, the limitless nature of object storage makes it fit for Big Data and Cloud contexts.
Moreover, object storage is simple and efficient. It offers easy data replication, scalability and is fit for “Write Once Read Many” contexts such as data analytics. Those characteristics combined with its ease of implementation and programmability all account to its widely spread usage.
What exactly is an object? How does object storage work, and what enables it to scale? We aim to clarify this.
Object storage is not exclusive to Cloud services such as AWS Simple Storage Service (S3), and multiple local object storage solutions exist as alternatives. Because AWS S3 sets a standard for object storage’s API interface, storage solutions and applications consuming from them are federated under “S3 compatibility”. Any S3-compatible app works with a large number of S3-compliant object storage solutions and vice-versa, which enhances both of their growth.
This article is the first of a series of three:
- Architecture of object-based storage and S3 standard specifications
- MinIO object storage within a Kubernetes cluster
- Ceph object storage within a Kubernetes cluster with Rook
Object storage: how it works, why it scales
As the name suggests, object storage contains data in the form of objects. The core paradigm of object storage is to optimize common data and metadata operations while coupling the two together. What is an object made of?
It is the combination of a key (granting access), a value (actual data) and associated metadata: both the object’s and the extra metadata added by object storage for large-scale management. This metadata is stored in the same place as the data, unlike in file systems. The key, used to access the object, is the object’s name, path and unique object ID (OID) which the object storage generates.
Metadata plays a key role in object storage, allowing to make an abstraction of the hierarchy found in file systems. With object-based storage, everything is stored in a flat repository with no hierarchy. Indexing and further management is achieved through the sole use of metadata properties.
Custom metadata enrichment in objects is supported, allowing for more flexible data analysis. They also help control data replication.
Object Storage Devices (OSDs) are the physical devices supporting actual storage, and are either dedicated disks or dedicated partitions within disks. OSDs can be of different types, and belong to one or more storage pools. These pools are logical divisions of data, own objects, and are replicated among multiple OSDs as shown below.
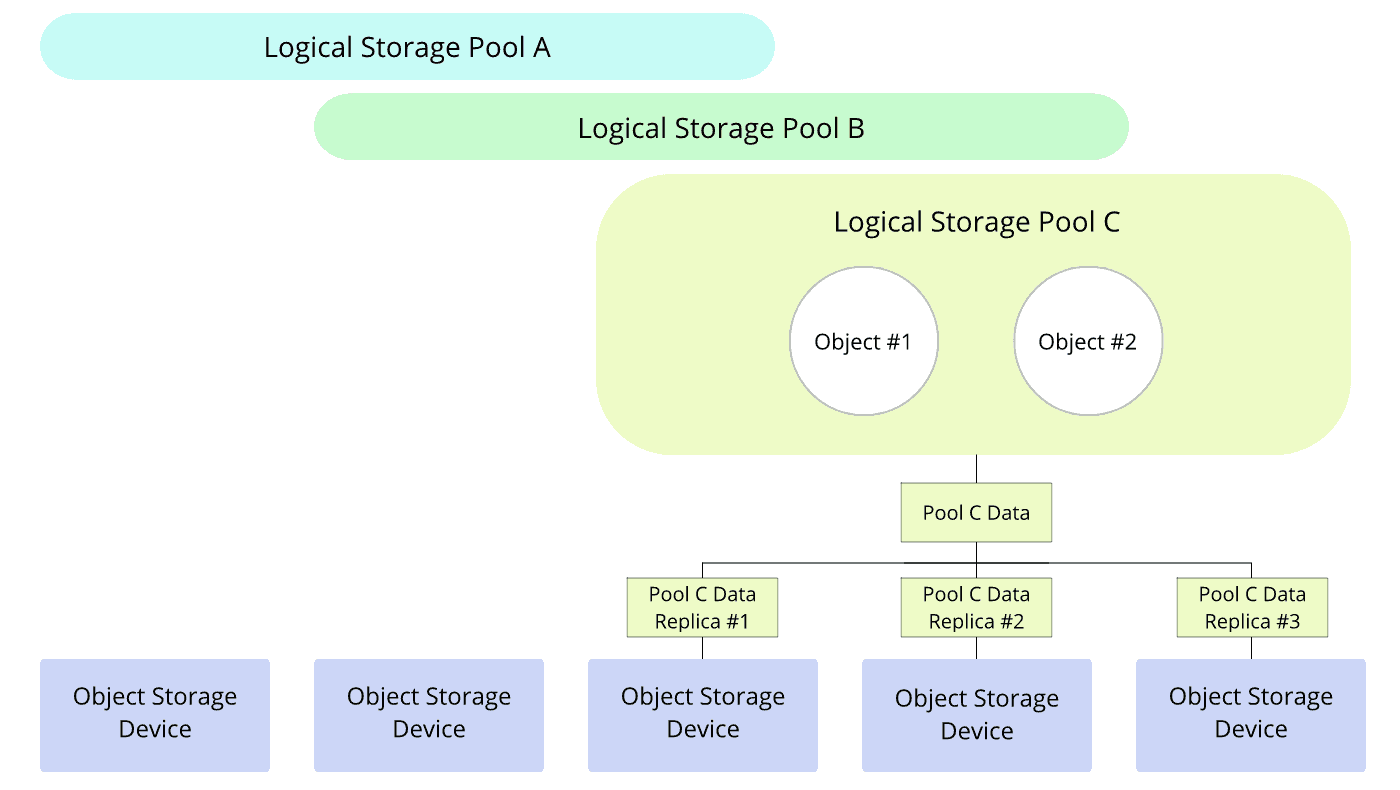
Thanks to this data replication across multiple locations, object storage achieves:
- High-availability ensuring low latency for queries and no bottlenecks on a single busy device;
- Resilience and failovers against device failures;
- Scalability, where an infinite amount of OSDs can be added.
It is easy with object data storage to start small and grow big: the available storage and number of devices can be expanded without endangering existing data. It is as simple as adding a new node with raw disks in the cluster, which are automatically integrated within storage pools. Removing a storage device is also handled, copying the data it previously held on other devices. And the combination of objects’ name, path and ID helps eliminate name collisions.
This ability to scale the storage is endless. Performance-wise, there are no differences between handling terabytes or petabytes of data. This is thanks to object storage’s flat structure, and extra object metadata usage in indexing and efficient management of the store.
Overall, object storage is suited for large volumes of unstructured data, and never exposes its underlying storage infrastructure to its consumers. It is a fit architecture for distributed, scalable storage. Let us now dive further into the interface providing access to this data.
Object storage data access: the S3 API Standard
Different implementations of object storage exist, with one common modern interface: the S3 API interface.
In object storage, it is common to transport data using an HTTP REST API. Multiple proprietary implementations of those APIs used to exist in the past for object storage, and few developers programmed using these. In 2006, AWS Simple Storage Solution (S3) set widely accepted common grounds for this API interface.
In other words: S3 will be used here to designate the open standard, not the AWS service.
The S3 REST API is easy to learn and use. It allows users to write, list, get and delete objects from a single endpoint, using PUT, GET, etc… In object storage, data is logically divided in buckets: protected partitions of data which can only be accessed by their associated S3 user. The bucket name is typically a prefix of a S3 request URI.
S3 users can own one or many buckets, and their S3 credentials grant them this access. S3 credentials are a pair of Access Key and Secret Key. Those two keys are confidential and grant write, read and delete access to everything the user owns in the object storage, so they should be propagated with care.
As a whole, the S3 API provides a number of benefits:
- Security as any operation requires S3 credentials;
- Confidentiality and isolation of data with multiple users, each user being granted an isolated part of the storage;
- Atomicity, writes and updates being performed in a single transaction.
Having both storage providers and user applications converge on this standard is a huge beneficial factor for the growth of object storage, for both providers and users. S3-compatible apps have a large market of different possible storage solutions, and object storage providers are themselves compatible with many different S3 apps.
Using object storage through S3 clients
Object access is done programmatically, through S3 clients. Those clients are used by S3-compatible apps to interact with the storage. There are two types of clients:
- Command-line clients, such as the AWS CLI or s5cmd. s5cmd is open-source, one of the fastest clients and the recommended way to interact with S3 object storage solutions through the CLI. It is written in Go and can be either used from a pre-built binary, built from source or used in a Docker container;
- AWS SDKs, which are development tools allowing applications to query S3-compliant object storage. SDKs exist for a number of different programming languages, including Java, C++, Python, JavaScript and more.
S3 URI schemes
Accessing an object using the API requires the object name, bucket name and region name if using AWS S3. Those are then merged into a REST URI, serving as a unique identifier for an object. This URI uses the s3:// family of schemes:
s3://: Deprecated, used to create a block-based overlay on top of S3 storage and won’t be used in this context;s3n://: S3 Native protocol, supports individual objects up to a size of 5GB;s3a://: Successor to s3n, built with the AWS SDK, more performant, less limited and the recommended option for object storage.
Furthermore, we need to specify the S3 endpoint. By default, when the S3 clients query those schemes, they query the Amazon AWS S3 Object Storage. This needs to be changed when using other object storage solutions, which use their own endpoint. In configuration settings for S3-compatible applications or as options for S3 CLI tools, it is possible to change the endpoint used for S3.
Credentials usage for clients
Credentials must be passed to the client in order to connect to a given bucket within object storage. Most S3 clients can fetch the credentials in different ways, but the three most common ways are:
- As environment variables:
AWS_ACCESS_KEY_IDfor the Access Key andAWS_SECRET_ACCESS_KEYfor the Secret Key; - As a
credentialsfile, under~/.aws/credentials; - In the
configfile, under~/.aws/config.
When either one of those 3 is provided, the S3 client is able to fetch them to connect to the object storage instance. Note that credentials settings have a precedence order, with environment variables having the highest priority.
Because those credentials grant access to all operations in a S3 bucket, securing them is critical. Passing them as options in the shell is not recommended, as they will be logged in plain text. Therefore, handling them as either files or environment variables is the preferred way. In Kubernetes environments, Kubernetes Secrets help manage those credentials, and passing them to containers as environment variables is done securely using env and envFrom along with secretRef.
Conclusion
Object-based storage is popular for its simplicity in its use, as every file operation is handled with HTTP queries such as PUT, GET…
Some object storage solutions are on-premises, in spite of the model being associated with the cloud. The most popular two are open-source and simple to deploy. They are full-fledged alternatives to Cloud object storage providers, and will not impact the way object storage consumers behave.
The two following articles of the series explain how to host object storage in a local cluster, through Rook and Ceph and through MinIO.
