


Ceph object storage within a Kubernetes cluster with Rook

By Luka BIGOT
Aug 4, 2022
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Ceph is a distributed all-in-one storage system. Reliable and mature, its first stable version was released in 2012 and has since then been the reference for open source storage. Ceph’s main perk is both delivering block storage, file systems and object storage in a single solution.
Storage in Ceph is supported by the Ceph cluster. It consists of a variety of components such as object storage daemons, monitors, managers… The Ceph cluster is deployed either on individual hosts in non-Kubernetes environments, or in a Kubernetes cluster with Rook as an orchestrator.
Rook is a tool used for managing and simplifying the installation of Ceph in Kubernetes by leveraging Kubernetes’ strengths. Rook is most commonly used to deploy Ceph, but also manages other kinds of distributed storage systems thanks to specialized operators.
Rook is thus capable of providing object storage in Kubernetes environments. Distributed storage is a must-have to ensure high availability, resilience and scalability. Furthermore, object storage is more scalable in comparison with block storage and file systems when it comes to large sizes of data. Our article about object storage’s architecture dives further into the matter.
We provide instructions to set up a local Kubernetes environment with Ceph object storage. Hosting object storage locally is a good way to understand how it works both in its structure and usage, either for development and testing purposes or while aiming to deploy it in production. Installing the Ceph cluster with Rook takes only a handful of commands, allowing one to quickly get to learning and testing.
This article is the last of a series of three:
- Architecture of object-based storage and the S3 standard
- MinIO object storage within a Kubernetes cluster
- Ceph object storage within a Kubernetes cluster with Rook
Ceph
Red Hat Ceph is an open-source unified system for storage. It is simultaneously able to provide block storage, file systems and object storage. Ceph aims to be a resilient and scalable distributed storage system with no Single Point of Failure (SPOF).
Two ways to deploy Ceph are officially recommended:
- Using cephadm: containers on your host machine form the Ceph cluster;
- Using Rook: pods within a Kubernetes cluster form the Ceph cluster. This is the deployment scenario covered in the article.
Data in Ceph is managed by an internal structure called an object. Those objects have an object ID, binary data and metadata key-value pairs. Thanks to the metadata semantic being flexible, Ceph is able to implement block storage and file systems logic with objects as a base. For example, Ceph as a file system uses metadata to record file owners and other attributes, establishing the file system abstraction.
Ceph’s core object storage implementation is named RADOS (Reliable Autonomic Distributed Object Store). From it, the three kinds of storage architectures are established:
- RADOS is exposed to Ceph consumers with
radosgw(RGW), a REST gateway handling S3 compatibility: this is Ceph’s object storage; - Ceph’s abstraction of file systems built on top of RADOS is called CephFS. It is POSIX-compliant, distributed and supports FUSE;
- The Ceph Block Device on top of RADOS (RBD) establishes block storage in Ceph.
Moreover, Ceph provides an API to directly access RADOS through librados.
Ceph’s object storage supports the S3 API and is therefore compatible with any application consuming from S3. It also supports hybrid on-premises and cloud deployment, and provides multi-site capabilities, enabling replication across different sites.
A Ceph storage cluster architecture is made of four kinds of specialized daemons. Those kinds are:
- Ceph Object Storage Daemons (OSDs), responsible for actual data storage. They also manage replication, recovery and rebalancing. They need to be associated with physical disks. A minimum of three OSDs is required to guarantee data redundancy and availability;
- Monitors (MONs), collecting maps of the cluster state across all Ceph cluster components. Those monitoring maps are critical for coordination between daemons in the cluster;
- Managers (MGRs), handling the state of the Ceph storage itself (how much storage remains, current load…), as well as metrics. They are also in charge of hosting the web Ceph Dashboard and the REST API to propagate the status and metrics;
- Metadata Servers (MSDs), appearing only when using Ceph as a File system.
Rook
Rook is an orchestrator for multiple distributed storage systems. Rook works with different storage providers, namely Ceph, NFS and Cassandra. It provides specialized Kubernetes operators to deploy each of those solutions. It is also compatible with Red Hat OpenShift and provides operators specific to this platform.
Rook is mostly used for its Ceph operator. The operator installs and configures the Ceph cluster in Kubernetes. This process is automated, compared to configuring Ceph manually on individual bare-metal machines. From the user’s perspective, the deployment is initiated by applying manifests from a control-plane node. Rook then relies on multiple Custom Resource Definitions (CRDs) to achieve this automation.
Control-plane nodes are nodes managing the resources of the cluster, typically master nodes in low-scale clusters.
Rook builds object storage sequentially:
- CRDs and common cluster parameters are deployed to enable all subsequent Rook components to work;
- The operator is then deployed, handling further pods creation;
- A resource file specifying cluster settings is applied, containing monitoring settings or pod tolerations;
- Ceph’s object-storage specific resources are deployed, eventually establishing the actual storage;
- Declaring a bucket and a subsequent bucket claim are the final steps before usage of this storage.
Rook with Ceph allows a Kubernetes cluster to have a unique system covering multiple storage needs. Each kind of storage provided by Ceph is optional and fully customizable. Therefore, Rook satisfies both applications consuming from S3 storage and regular storage needs such as a PostgreSQL server.
Rook also provides an in-cluster dashboard service, granting insight on the current state of the storage. It contains health status, total storage capacity, pod logs and an advanced view of the configuration of the three storage systems. The dashboard is password-protected, and accessing it is done by either using a temporary proxy or exposing the service through means such as an Ingress.
Requirements for hosting Rook with Ceph
The following tutorial goes through Rook’s deployment steps in a local cluster. This installation applies both to bare-metal clusters and VM clusters in a host machine. As the latter is more convenient for development, a cluster of VMs is assumed in the tutorial.
This tutorial requires:
- A Kubernetes cluster with a Container Network Interface (CNI) plugin installed (for example, Calico);
- At least 3 worker nodes with 3 GB of RAM;
- Available unformatted disks on your worker nodes or unformatted partitions within those disks. Those must either be physical devices if on bare-metal, or virtual disks if using VMs.
This repository provides a template to easily obtain a cluster fulfilling this tutorial’s requirements.
If you wish to learn how to add virtual disks in a Vagrant cluster using VirtualBox, take a look at this article.
Note: For a production cluster, separating worker nodes from object storage nodes is a good practice, as computing operations and storage operations do not affect each other as a result. This is known as asymmetrical storage.
Installing Rook
There are two ways to install Rook:
- By using manifests to configure the Rook resources, going through them one by one;
- By using the Helm package manager which centralizes Ceph’s configuration, allows for more advanced deployments and is generally fit for production-grade Ceph clusters.
Both methods achieve the same final result. The first installation method is convenient for this tutorial as it steps us through a simple Rook installation process. In the long run, a Helm installation is preferred. It centralizes configuration and eases the upgrading process. However, it requires more tweaks in its configuration and enforces Kubernetes resource limitations, making deployments difficult on machines with low RAM.
This tutorial starts with the manifests deployment. The Helm deployment is covered later on.
Installing Rook through manifests
From a control-plane node with access to kubectl, clone the Rook repository and from the rook/deploy/examples directory, fetch the example manifests in a folder outside of the repository:
git clone --single-branch --branch v1.9.4 https://github.com/rook/rook.git
cp -r rook/deploy/examples/. rook-manifests/
cd rook-manifests/The manifests control configuration of Rook components. For example:
object.yamlallows management of the number of replicas for object storage data or metadata pools;cluster.yamlallows controlling the number of replicas for Ceph components (MGR, MON pods number);
It is possible to disable CephFS and RBD plugins deployment in operator.yaml. This is useful to save resources because we only wish to deploy object storage. Modify the manifest using nano operator.yaml and set the relevant fields as follows:
data:
ROOK_CSI_ENABLE_CEPHFS: "false"
ROOK_CSI_ENABLE_RBD: "false"If using dedicated storage nodes, tolerations need to be specified, otherwise, storage disks go undetected by Rook. Tolerations are required in the placement field in cluster.yaml:
spec:
placement:
all:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: storage-node
operator: In
values:
- "true"
tolerations:
- key: storage-node
operator: ExistsInstalling Rook and verifying disk detection
The Ceph cluster’s deployment is handled by different manifests. Run the following commands:
kubectl create -f crds.yaml -f common.yaml -f operator.yaml
kubectl create -f cluster.yaml -f object.yamlRook deploys pods sequentially: the operator pod, the cluster pods and finally the object storage pod. During this process, Ceph searches for available unformatted disks and partitions in the cluster. Successful detection of the disks is critical for object storage establishment and therefore needs to be ascertained.
After applying the manifests, wait for Rook pods initialization, which usually takes more than 10 minutes.
Run kubectl get pods -n rook-ceph to check the current status of the Rook pods. After a few minutes, pods with the rook-ceph-osd-prepare- name appear in the list for each node that Ceph inspects. The rook-ceph-osd-X series of pods are generated when Ceph succeeds in finding and formatting the disks.
If the OSD pods do not appear despite
rook-ceph-osd-prepare-pods beingCompleted, inspect the discovering process for those nodes with the following command:kubectl -n rook-ceph logs rook-ceph-osd-prepare--XXXXX provision
Creating a bucket and bucket claim
Once the cluster establishes OSD pods (and therefore has recognized and formatted disks for object storage), the last step is creating a bucket in object storage and its corresponding BucketClaim. The latter generates the S3 credentials to access object storage:
kubectl create -f storageclass-bucket-delete.yaml -f object-bucket-claim-delete.yamlThe
deletein the filenames refers to thereclaimPolicyof deleted buckets, set as eitherdeleteorretain.
Check for the successful creation of S3 credentials in the default namespace. It may take a while for them to appear when the Rook cluster is still starting. Their names are defined in the metadata.name field of the above manifests:
kubectl get secret ceph-delete-bucket
kubectl get configmap ceph-delete-bucketOnce they appear, Rook Object Storage is ready and usable. All that is left is to make sure it is functional.
Installing Rook through Helm
As seen in the installation through manifests, managing different files to configure Rook’s storage configuration in the cluster quickly becomes tedious. In addition, such files do not handle additional resources such as the Ingress to access the Rook dashboard. Installing Rook using the Helm package manager simplifies this process by centralizing all configuration in two values files.
This section covers an alternate installation method for Rook. Skip ahead to object storage testing if the manifests installation is sufficient.
Warning: The Rook Helm installation is more resource-intensive than the manifests installation. Host machines with less than 32 GB of RAM may struggle running this deployment, more dedicated to production setups. The following is recommended:
- Each node needs at least 6 GB of RAM;
- Use 3 worker nodes with 1 disk each, as an OSD is created for each disk and consumes around 2 GB of RAM per disk.
Installing Rook through Helm first requires installing Helm by downloading and running its installation script. Afterwards, Helm’s Rook chart requires *-values.yaml files containing the configuration, which we download. The default content of those files need to be reviewed and adjusted, both for the Rook operator chart and the actual Rook Ceph cluster chart.
Run the following commands:
# Install Helm
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
sudo chmod 0700 get_helm.sh
./get_helm.sh
# Download values files
curl -fsSL -o operator-values.yaml https://raw.githubusercontent.com/rook/rook/master/deploy/charts/rook-ceph/values.yaml
curl -fsSL -o ceph-values.yaml https://raw.githubusercontent.com/rook/rook/master/deploy/charts/rook-ceph-cluster/values.yamlEditing and installing the charts
Open a text editor (for example, nano operator-values.yaml) and change the following:
- For the
operator-values.yamlfile:- At the top of the file, in
image.tag, specify a desiredrook/cephimage version, for examplev1.9.6. Versions are listed in the Docker Hub image repository; - Set both
csi.enableRbdDriverandcsi.enableCephfsDrivertofalse, as they deploy resource-intensive pods for block storage and file systems respectively.
- At the top of the file, in
- For the
ceph-values.yamlfile:- Empty the arrays of the
cephFileSystemandcephBlockPoolsfields, but do not delete them as the default behavior creates them otherwise. Only object storage is desired, so add empty arrays[ ]for those fields. Withnano, theCtrl+6shortcut helps selecting large portions of the file andCtrl+kcuts the selection; - If the machines have low resources, in
cephClusterSpec.resources, adjust the CPU and memory requests and limits. In particular, reduce the OSDs memory requests and limits to2Giinstead of4Gi; - If using an Ingress controller, the
ingress.dashboardfield allows exposing the Rook dashboard.
- Empty the arrays of the
Deploy the Helm charts using the *-values.yaml files:
helm repo add rook-release https://charts.rook.io/release
helm install --create-namespace --namespace rook-ceph rook-ceph rook-release/rook-ceph -f operator-values.yaml
helm install --create-namespace --namespace rook-ceph rook-ceph-cluster \
--set operatorNamespace=rook-ceph rook-release/rook-ceph-cluster -f ceph-values.yamlThe Ceph cluster then deploys, and object storage sets itself up. The process takes a while. To check the current progress of the deployment, run kubectl --namespace rook-ceph get cephcluster.
Creating the bucket claim in the Helm installation
One more step is required in order to obtain the S3 credentials granting us access to the generated bucket in object storage. A corresponding ObjectBucketClaim resource is required.
Create the corresponding manifest for this resource in a new file:
cat > object-bucket-claim.yaml << EOF
apiVersion: objectbucket.io/v1alpha1
kind: ObjectBucketClaim
metadata:
name: ceph-delete-bucket
spec:
generateBucketName: ceph-bkt
storageClassName: ceph-bucket
EOFApply this manifest to generate the secret containing S3 credentials:
kubectl apply -f object-bucket-claim.yamlUsing dedicated storage nodes in Helm installation
In this tutorial, the recommended cluster setup is one master node and three worker nodes with attached disks to keep things simple. More advanced Kubernetes clusters separate computing operations from storage operations. Therefore, they need dedicated storage nodes. The following steps explain installing Rook through Helm in this asymmetric storage scenario.
Dedicated storage nodes are not mandatory. Skip to the next part if this is not required.
Dedicated storage nodes have Kubernetes taints applied to them, preventing regular scheduling. Taints are a combination of key, value and effect, for example storage-node=true:NoSchedule. To let Rook schedule pods on those tainted nodes, tolerations need to be specified. Given the previous taint, the corresponding toleration in YAML format is:
- key: "storage-node"
operator: "Equal"
value: "true"
effect: "NoSchedule"Insert the matching toleration in the following necessary fields in the charts values files:
operator-values.yaml:- Add the toleration in the
tolerationsobject array; - Add the toleration in the
csi.provisionerTolerationsfield; - Add the toleration in the
discover.tolerationsfield for the disk discovery process of Rook; - Add the toleration in the
admissionController.tolerationsfield.
- Add the toleration in the
ceph-values.yaml:- Add the toleration in the
cephClusterSpec.placement.all.tolerationsfield.
- Add the toleration in the
Then, install the charts with the updated values files as seen previously.
Checking Rook’s health with the Toolbox pod
Successful setup of Rook’s object storage is validated by checking the Ceph health status and trying to successfully send and retrieve a file. The Rook toolbox pod comes ready with the ceph CLI tool, preconfigured to communicate with the Ceph cluster.
Using the toolbox manifest from the Rook repository, the following command creates the toolbox pod and accesses it:
# Download the manifest if it is not already there
curl -fsSL -o toolbox.yaml https://raw.githubusercontent.com/rook/rook/master/deploy/examples/toolbox.yaml
# Deploy toolbox pod
kubectl create -f toolbox.yaml
# Wait for the pod to be running
kubectl -n rook-ceph rollout status deploy/rook-ceph-tools
# Access the toolbox pod in interactive mode
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bashRun the ceph status and ceph health detail commands to obtain information about the Ceph cluster’s health:
HEALTH_OKis expected;HEALTH_WARNindicates non-critical errors:- One such frequent error is clock skew, which is fixed by syncing the clocks across cluster nodes using tools such as Chrony.
HEALTH_ERRindicates that the object storage is unusable.
To exit the toolbox pod, run exit. Then delete the pod:
kubectl delete -f toolbox.yamlSending a file to Rook’s object storage with s5cmd
After checking the Ceph cluster health, the following step tests successful writes and reads in storage. The s5cmd S3 storage CLI client is used to communicate with object storage through external means. It is the preferred choice to perform those tests.
Download the s5cmd binary archive and extract it locally:
curl -fsSL -o s5cmd_2.0.0_Linux-64bit.tar.gz https://github.com/peak/s5cmd/releases/download/v2.0.0/s5cmd_2.0.0_Linux-64bit.tar.gz
# Download checksum
curl -fsSL -o s5cmd_checksums.txt https://github.com/peak/s5cmd/releases/download/v2.0.0/s5cmd_checksums.txt
# Verify checksum before unzipping
grep 's5cmd_2.0.0_Linux-64bit.tar.gz' s5cmd_checksums.txt | sha256sum -c - && tar -xf s5cmd_2.0.0_Linux-64bit.tar.gzTo let s5cmd interact with our object storage instance, additional configuration is required from environment variables.
In particular, the object storage endpoint needs to be specified. Because testing is done from a node of the cluster and not in a pod, port-forwarding the endpoint service temporarily allows us to access it.
Run the following from another terminal window connected to the master node, using the name of the object storage service:
# Run the following from another terminal window
# For manifests installs:
kubectl port-forward -n rook-ceph service/rook-ceph-rgw-my-store 8080:80
# For Helm installs:
kubectl port-forward -n rook-ceph service/rook-ceph-rgw-ceph-objectstore 8080:80Forwarding the service on the cluster machine allows for simpler testing. In practice, the endpoint service name is resolvable in pods and is the preferred way to contact object storage from within the cluster. Its domain name is obtained from the following command:
kubectl get cm ceph-delete-bucket -o jsonpath='{.data.BUCKET_HOST}'
Prepare S3 settings exports from kubectl queries with the following commands:
# The below address is localhost, as the service port is forwarded to the current node
export AWS_HOST=127.0.0.1
export PORT=8080
export BUCKET_NAME=$(kubectl -n default get cm ceph-delete-bucket -o jsonpath='{.data.BUCKET_NAME}')
export AWS_ACCESS_KEY_ID=$(kubectl -n default get secret ceph-delete-bucket -o jsonpath='{.data.AWS_ACCESS_KEY_ID}' | base64 --decode)
export AWS_SECRET_ACCESS_KEY=$(kubectl -n default get secret ceph-delete-bucket -o jsonpath='{.data.AWS_SECRET_ACCESS_KEY}' | base64 --decode)Create an S3 credentials file for s5cmd, which uses previously set environment variables:
mkdir ~/.aws
cat > ~/.aws/credentials << EOF
[default]
aws_access_key_id = ${AWS_ACCESS_KEY_ID}
aws_secret_access_key = ${AWS_SECRET_ACCESS_KEY}
EOFs5cmd is now ready to use. The below commands perform the testing, creating a file in /tmp/, sending it to the S3 storage, retrieving it and displaying it:
echo "This is the S3 storage test" > /tmp/myFile
./s5cmd --endpoint-url http://$AWS_HOST:$PORT cp /tmp/myFile s3://$BUCKET_NAME
./s5cmd --endpoint-url http://$AWS_HOST:$PORT cp s3://$BUCKET_NAME/myFile /tmp/myDownloadedFile
cat /tmp/myDownloadedFile
# Expected output: This is the S3 storage testThe last command displays the content of the file we downloaded back. If its content is the same as the original myFile, the S3 object storage is functional and ready. Interrupt the port-forwarding from the other terminal using Ctrl+C.
Accessing the Rook dashboard
Rook’s dashboard provides a convenient web UI to manage the Ceph storage cluster. Much like how the endpoint was exposed temporarily for testing earlier, the same is done to access it from the host machine on a web browser.
From the cluster, first fetch the dashboard credentials in order to authenticate:
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echoThe console outputs the password of the admin dashboard user.
Port-forward the dashboard service so that it is accessible on the host machine:
kubectl port-forward --address 0.0.0.0 -n rook-ceph service/rook-ceph-mgr-dashboard 8443:8443Open a web browser on the host machine, navigate to the address of the control plane node with HTTPS at port 8443. For the example cluster, the address is https://192.168.56.10:8443. After accepting the security risk, a login page is displayed.

Use the admin username and paste the password displayed in the terminal previously.
The dashboard is now accessible: it is possible to view the cluster’s health, current storage state and more detail about all three kinds of Ceph storage from the left-side tabs.
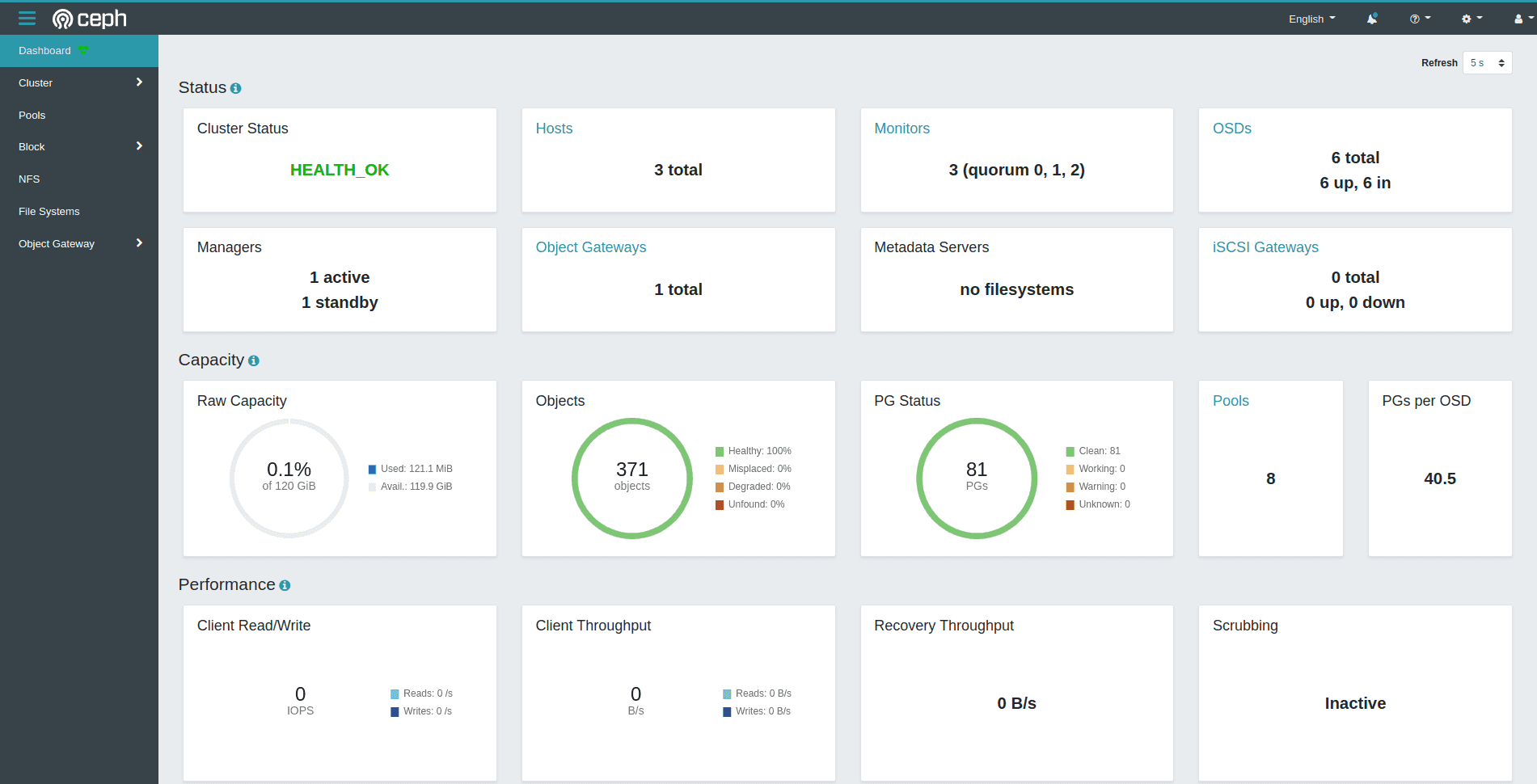
Outside of development and instead of port-forwarding to access this dashboard, Ingresses are commonly used when an Ingress controller and further load balancing are functional in the cluster.
Rook and MinIO, another Kubernetes object storage solution
MinIO is another popular object storage solution for Kubernetes clusters. It is an alternative to Rook and provides different benefits, while it does not cover other storage systems like Ceph does.
We cover MinIO deployment in Kubernetes in a previous article of this series. Here are key comparison indications with Rook:
Pros of MinIO:
- MinIO is more straightforward to deploy in a cluster than standalone Ceph, although Rook dramatically helps in simplifying this process;
- MinIO has more tools to make S3 object storage consumption easy, with dedicated MinIO SDKs and a MinIO Client compatible with any object storage solution;
Cons of MinIO:
- Documentation-wise, MinIO’s is not as clear as Ceph’s or Rook’s, with missing details and possible confusion;
- The MinIO operator console is not perfect and suffers from some bugs.
Conclusion
Using Rook provides the advantage of both covering object storage needs as well as file systems or block storage requirements for other cluster services and applications. Moreover, deploying it for testing is done quickly, as shown in the tutorial. Overall, it brings the flexibility of Ceph storage to Kubernetes clusters with a painless deployment and automated management.
Advanced object storage capabilities are enabled when diving into more complex configurations. Such capabilities range from exposing the Rook dashboard through an Ingress to replicating storage pools across different sites.
