


Stockage objet Ceph dans un cluster Kubernetes avec Rook

By BIGOT Luka
4 août 2022
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Ceph est un système tout-en-un de stockage distribué. Fiable et mature, sa première version stable est parue en 2012 et a été depuis la référence pour le stockage open source. L’avantage principal de Ceph est de proposer, dans une seule solution, à la fois du stockage bloc, des systèmes de fichiers et du stockage objet.
Le stockage au sein de Ceph est géré par le cluster Ceph. Ce cluster est constitué de plusieurs composants, divisant les tâches disques des tâches de gestion du cluster ou de métriques. Le cluster Ceph est déployé soit sur des hôtes indépendants en dehors de Kubernetes, soit au sein d’un cluster Kubernetes avec Rook, un orchestrateur.
Rook est un outil utilisé pour gérer et simplifier l’installation de Ceph dans Kubernetes en tirant profit des avantages de Kubernetes. Rook est le plus souvent utilisé pour déployer Ceph, mais gère également d’autres systèmes de stockage distribué au travers d’opérateurs spécialisés.
Rook est ainsi capable d’héberger du stockage objet dans des environnements Kubernetes. Le stockage distribué est indispensable pour assurer la haute disponibilité, la robustesse et la scalabilité du service de stockage. De plus, le stockage objet est plus adapté aux larges tailles de données que le stockage bloc et systèmes de fichiers. Notre article sur l’architecture du stockage objet développe ce sujet.
Nous détaillons ici comment déployer un environnement Kubernetes local avec du stockage objet Ceph. Héberger le stockage objet localement est un bon moyen pour en comprendre sa structure et son fonctionnement, que ce soit dans une optique de développement ou de test, ou encore pour déployer MinIO en production. L’installation du cluster Ceph avec Rook se fait en une poignée de commandes, permettant de rapidement passer à sa découverte et son utilisation.
Cet article est le dernier d’une série de trois :
- Architecture des stockages objets et attributs du standard S3
- Stockage objet avec MinIO dans un cluster Kubernetes
- Stockage objet Ceph dans un cluster Kubernetes avec Rook
Ceph
Red Hat Ceph est un système de stockage unifié open-source. Ce système est capable de fournir simultanément du stockage bloc, des systèmes de fichiers et du stockage objet. Ceph vise à être un système de stockage distribué résistant et scalable sans point de défaillance unique (SPOF).
Il existe deux moyens officiellement recommandés pour déployer Ceph :
- Avec cephadm : des containers sur la machine hôte forment le cluster Ceph ;
- Avec Rook : des pods au sein d’un cluster Kubernetes forment le cluster Ceph. C’est le scénario de déploiement couvert par cet article.
Les données dans Ceph sont encapsulées dans une structure interne portant le nom d’objet. Ces objets ont un ID objet, des données en binaire et des métadonnées, paires de clés-valeurs. Grâce à la sémantique flexible de ces métadonnées, Ceph est capable d’implémenter les logiques de stockage bloc et de système de fichiers en partant des objets. Par exemple, Ceph en tant que système de fichiers utilise les métadonnées objet pour enregistrer le propriétaire d’un fichier ainsi que d’autres attributs, établissant l’abstraction du système de fichiers.
Le cœur de l’implémentation du stockage objet de Ceph s’appelle RADOS (Reliable Autonomic Distributed Object Store). Depuis ce cœur, les trois types d’architectures de stockage sont établis :
- Ceph expose RADOS à ses clients avec
radosgw(RGW), une passerelle REST gérant la compatibilité S3. C’est le stockage objet de Ceph ; - L’abstraction des systèmes de fichiers de Ceph construite avec RADOS est appelée CephFS. Ce système de fichiers est distribué, conforme au standard POSIX et est compatible avec FUSE ;
- Le stockage bloc de Ceph est établi avec RADOS Block Device (RBD).
De plus, Ceph fournit l’API librados pour directement accéder à RADOS.
Le stockage objet de Ceph supporte l’API S3, étant donc compatible avec n’importe quelle application cliente S3. Les déploiements hybrides locaux et cloud sont supportés, et le déploiement sur plusieurs sites avec réplication de données est possible.
L’architecture d’un cluster de stockage Ceph comporte quatre types de daemons. Ces types sont :
- Les Ceph Object Storage Daemons (OSDs), responsables du stockage à proprement parler. Ils gèrent également la réplication, répartition et récupération des données. Ils doivent être associés avec des disques physiques. Un minimum de trois OSDs est requis pour garantir la redondance et la haute-disponibilité des données ;
- Les Monitors (MONs), surveillant et enregistrant l’état des composants du cluster Ceph. Ces enregistrements sont critiques pour coordonner les différents daemons du cluster ;
- Les Managers (MGRs), gérant l’état du stockage Ceph (espace actuellement libre, charge actuelle…) ainsi que les métriques. Ils sont également responsables de l’hébergement du dashboard Ceph et de l’API REST permettant la propagation du statut et des métriques ;
- Les Metadata Servers (MSDs), uniquement utilisés avec Ceph en tant que système de fichiers.
Rook
Rook est un orchestrateur pour différents systèmes de stockage distribué. Il supporte plusieurs fournisseurs de stockage dont Ceph, NFS et Cassandra. Il fournit des opérateurs Kubernetes spécialisés pour le déploiement de chacun. Rook est également compatible avec Red Hat OpenShift et fournit des ressources dédiées à l’usage de cette plateforme.
Rook est principalement utilisé pour son opérateur Ceph. L’opérateur installe et configure le cluster Ceph dans Kubernetes. Ce processus est automatisé, en comparaison avec une configuration manuelle de Ceph sur des machines individuelles. Du point de vue de l’utilisateur, le déploiement est démarré en appliquant des manifests depuis un nœud du plan de contrôle. Rook utilise ensuite plusieurs CRDs, ou Custom Resource Definitions pour obtenir cette automatisation.
Les nœuds du plan de contrôle sont les nœuds gérant les ressources du cluster, typiquement les nœuds maîtres ou master dans les petits clusters.
Rook construit le stockage objet par étapes :
- Les CRDs et les paramètres généraux du cluster sont déployés pour permettre aux composants Rook suivants de fonctionner ;
- L’opérateur est ensuite déployé, gérant la création de pods futurs ;
- Un fichier de ressources contenant les paramètres du cluster est appliqué, contenant des paramètres de monitoring ou encore des tolérations de pods ;
- Les ressources spécifiques au stockage objet sont déployées, permettant d’établir celui-ci ;
- La déclaration d’un bucket et de son bucket claim associé sont les dernières étapes pour utiliser le stockage objet.
Rook avec Ceph permet à un cluster Kubernetes d’avoir un système unique couvrant plusieurs besoins de stockage. Chaque type de stockage fourni par Ceph est optionnel et complètement configurable. Ainsi, Rook répond à la fois aux besoins des applications consommant du stockage S3 et aux besoins typiques de stockage dans Kubernetes pour un serveur PostgreSQL, par exemple.
Rook fournit également un service de dashboard au sein du cluster, donnant de la visibilité sur l’état actuel du stockage. Celui-ci nous renseigne sur la santé du cluster, sa capacité totale de stockage, les logs de pods ainsi qu’une vue avancée sur la configuration de chacun des trois types de stockage. La dashboard est protégée par des identifiants et, pour s’y connecter avec un navigateur web sur la machine hôte, un proxy temporaire ou une exposition du service avec un Ingress est nécessaire.
Prérequis pour héberger Rook avec Ceph
Le tutoriel de cet article détaille le déploiement de Rook dans un cluster local. Cette installation s’applique à la fois aux clusters physiques et aux clusters de machines virtuelles au sein d’une machine hôte. Ce dernier scénario étant plus pratique pour le développement, un cluster de VMs sera supposé durant ce tutoriel.
Ce tutoriel nécessite :
- Un cluster Kubernetes avec un plugin Container Network Interface (CNI) installé (par exemple, Calico) ;
- Au moins 3 nœuds travailleurs avec 3 GB de RAM ;
- Des disques non formatés sur les nœuds travailleurs ou des partitions non formatées au sein de ces disques. Ils peuvent être physiques sur un cluster bare-metal ou virtuels sous des machines virtuelles.
Ce dépôt GitHub fournit un template permettant d’obtenir facilement un cluster répondant aux exigences de ce tutoriel.
Si vous souhaitez apprendre comment ajouter des disques virtuels sur un cluster Vagrant utilisant VirtualBox, cet article indique comment procéder.
Note : Pour un cluster en production, séparer les nœuds travailleurs des nœuds de stockage objet est une bonne pratique, les opérations de calcul et de stockage se trouvant non-affectées mutuellement. Cette pratique s’appelle le stockage asymétrique.
Installation de Rook
Il existe deux méthodes pour installer Rook :
- En passant par les manifests pour configurer les ressources Rook unes par unes ;
- En utilisant le gestionnaire de packages Helm permettant une centralisation de la configuration de Ceph, une configuration plus avancée et un déploiement de cluster Ceph proche d’un niveau de production.
Les deux méthodes produisent le même résultat final. La première méthode est pratique pour ce tutoriel, proposant un processus d’installation simple de Rook. Sur le long-terme, l’installation avec Helm est préférable. Elle centralise la configuration et facilite le processus de mise à niveau. Toutefois, son paramétrage est plus avancé et sa consommation en ressources est plus élevée, rendant les déploiements difficiles sur les machines avec peu de RAM.
Ce tutoriel débute avec le déploiement par manifests. Le déploiement par Helm est détaillé plus tard.
Installation de Rook avec les manifests
Depuis un nœud du plan de contrôle ayant accès à kubectl, clonons le dépôt GitHub de Rook. Depuis le dossier rook/deploy/examples, récupérons les manifests d’exemple dans un dossier en dehors du dépôt Git :
git clone --single-branch --branch v1.9.4 https://github.com/rook/rook.git
mkdir rook-files
cp -r rook/deploy/examples/. rook-manifests/
cd rook-manifests/Les manifests gèrent la configuration des composants Rook. Par exemple :
object.yamlpermet la gestion du nombre de répliques pour les données du stockage objet ou des pools de métadonnées ;cluster.yamlpermet le contrôle du nombre de répliques pour les composants Ceph (nombre de pods MGR, MON…) ;
Il est possible de désactiver le déploiement des plugins CephFS et RBD dans operator.yaml. Les désactiver permet de réduire l’utilisation des ressources physiques puisque nous ne voulons que le stockage objet. Modifiez le manifest en exécutant nano operator.yaml et en modifiant les champs suivants :
data:
ROOK_CSI_ENABLE_CEPHFS: "false"
ROOK_CSI_ENABLE_RBD: "false"Lors de l’utilisation de nœuds de stockage dédiés, des tolérations Kubernetes doivent être indiquées, sinon les disques de stockage ne sont pas détectés par Rook. Les tolérations sont requises pour le champ placement dans cluster.yaml :
spec:
placement:
all:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: storage-node
operator: In
values:
- "true"
tolerations:
- key: storage-node
operator: ExistsInstallation de Rook et vérification de la détection des disques
En utilisant les manifests, exécutons les commandes suivantes créant le cluster Ceph et son stockage objet :
kubectl create -f crds.yaml -f common.yaml -f operator.yaml
kubectl create -f cluster.yaml -f object.yamlRook déploie les pods dans l’ordre suivant : le pod de l’opérateur, les pods du cluster Ceph puis enfin le pod du stockage objet. Durant ce processus, Ceph cherche des disques ou partitions non formatées dans le cluster. La détection de ces disques est critique pour établir le stockage objet et doit donc être vérifiée.
Après avoir appliqué les manifests, attendons l’initialisation des pods Rook qui prend en général plus de 10 minutes.
Exécutons kubectl get pods -n rook-ceph pour obtenir le statut actuel des pods Rook. Après quelques minutes, des pods avec le nom rook-ceph-osd-prepare- apparaissent dans la liste pour chaque nœud que Ceph inspecte. La série de pods rook-ceph-osd-X sont générés quand Ceph parvient à trouver et formater les disques.
Si les pods d’OSD n’apparaissent pas malgré les pods
rook-ceph-osd-prepare-marqués commeCompleted, la commande suivante permet d’inspecter le processus de découverte des disques :kubectl -n rook-ceph logs rook-ceph-osd-prepare--XXXXX provision
Création d’un bucket et d’un BucketClaim
Une fois que le cluster dispose de pods d’OSD (et donc de disques fonctionnels pour le stockage objet), la dernière étape est la création d’un bucket dans le stockage objet ainsi que son BucketClaim correspondant. Ce dernier génère les identifiants S3 pour accéder au stockage objet :
kubectl create -f storageclass-bucket-delete.yaml -f object-bucket-claim-delete.yamlLe suffixe
deletedans les noms de fichiers désigne lareclaimPolicydes buckets supprimés, valantdeleteouretain.
Vérifions la création des identifiants S3 dans le namespace default. Leur apparition peut prendre du temps lorsque le cluster Rook est encore en démarrage. Leur noms sont définis dans le champ metadata.name des manifests précédents :
kubectl get secret ceph-delete-bucket
kubectl get configmap ceph-delete-bucketLorsqu’ils sont créés, le stockage objet de Rook est prêt et utilisable. Il ne reste qu’à vérifier que celui-ci fonctionne correctement.
Installation de Rook avec Helm
Comme observé avec l’installation par manifests, la gestion de différents fichiers pour la configuration du stockage dans le cluster avec Rook devient rapidement fastidieuse. De plus, ces fichiers ne gèrent pas la création de ressources supplémentaires tels qu’un Ingress pour accéder à la dashboard de Rook. L’installation de Rook avec le gestionnaire de packages Helm simplifie ce processus en centralisant toutes les configurations dans deux fichiers de valeurs.
Cette section décrit un autre moyen d’installer Rook. Passez à la section test du stockage objet si l’installation par manifests est suffisante.
Attention : L’installation de Rook avec Helm consomme plus de ressources machine qu’avec l’installation par manifests. Les machines hôtes possédant moins de 32 GB de RAM auront des difficultés pour cette installation plus proche d’un scénario de production. Nous recommandons :
- Au moins 6 GB de RAM sur chaque nœud ;
- Trois nœuds travailleurs avec un disque chacun, car un OSD consommant environ 2 GB de RAM est créé par disque.
L’installation de Helm se fait à partir d’un script d’installation, que nous téléchargeons. Les fichiers *-values.yaml pour la chart Helm de Rook doivent ensuite être téléchargés. Leur contenu par défaut doit être ajusté, à la fois pour la chart de l’opérateur Rook et pour la chart du cluster Ceph de Rook.
Exécutons les commandes suivantes :
# Installation de Helm
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
sudo chmod 0700 get_helm.sh
./get_helm.sh
# Téléchargement des fichiers de valeurs
curl -fsSL -o operator-values.yaml https://raw.githubusercontent.com/rook/rook/master/deploy/charts/rook-ceph/values.yaml
curl -fsSL -o ceph-values.yaml https://raw.githubusercontent.com/rook/rook/master/deploy/charts/rook-ceph-cluster/values.yamlModification des valeurs et installation des charts
Ouvrez les fichiers avec un éditeur de texte (par exemple nano operator-values.yaml) et modifiez les champs suivants :
- Pour le fichier
operator-values.yaml:- En haut du fichier, dans
image.tag, indiquez la version désirée de l’imagerook/ceph, par exemplev1.9.6. Les versions sont listées sur le dépôt de l’image sur Docker Hub ; - Indiquez
falseàcsi.enableRbdDriveretcsi.enableCephfsDriver, déployant sinon des pods gourmants en ressources pour le stockage bloc et les systèmes de fichiers non établis ici.
- En haut du fichier, dans
- Pour le fichier
ceph-values.yaml:- Videz les tableaux des champs
cephFileSystemetcephBlockPoolsmais ne supprimez pas ces champs, le comportement par défaut les créant quand même s’ils sont absents. Nous ne voulons que le stockage objet. Attribuez des tableaux vides[ ]à ces champs. Avecnano, le raccourciCtrl+6permet de sélectionner des larges sections du fichier etCtrl+kcoupe la sélection ; - Si les machines ont de basses ressources, dans
cephClusterSpec.resources, ajustez les requêtes et limites CPU et mémoires. En particulier, réduisez la mémoire utilisée par les OSDs de2Giau lieu de4Gi; - Si un contrôleur Ingress est présent dans le cluster, le champ
ingress.dashboardpermet d’exposer la dashboard de Rook.
- Videz les tableaux des champs
Déployez les charts Helm en utilisant les fichiers *-values.yaml :
helm repo add rook-release https://charts.rook.io/release
helm install --create-namespace --namespace rook-ceph rook-ceph rook-release/rook-ceph -f operator-values.yaml
helm install --create-namespace --namespace rook-ceph rook-ceph-cluster \
--set operatorNamespace=rook-ceph rook-release/rook-ceph-cluster -f ceph-values.yamlLe cluster Ceph se déploie ensuite, et le stockage objet s’établit. La vérification de la progression actuelle du déploiement est permise par kubectl --namespace rook-ceph get cephcluster.
Création du BucketClaim pour l’installation Helm
Une étape de plus est nécessaire pour obtenir les identifiants S3, nous permettant l’accès au stockage objet. Une ressource ObjectBucketClaim correspondant au bucket généré est requise.
Créez le manifest pour cette ressource dans un nouveau fichier :
cat > object-bucket-claim.yaml << EOF
apiVersion: objectbucket.io/v1alpha1
kind: ObjectBucketClaim
metadata:
name: ceph-delete-bucket
spec:
generateBucketName: ceph-bkt
storageClassName: ceph-bucket
EOFAppliquez ce manifest pour générer le secret contenant les identifiants S3 :
kubectl apply -f object-bucket-claim.yamlNœuds de stockage dédiés pour l’installation Helm
Dans ce tutoriel, la configuration de cluster recommandée comprend un nœud maître et trois nœuds travailleurs avec disques associés pour faire simple. Des configurations de cluster Kubernetes plus avancées séparent les opérations de calcul des opérations de stockage, et ont besoin de nœuds de stockage dédiés. Les étapes suivantes expliquent l’installation de Rook avec Helm dans ce scénario de stockage asymétrique.
Les nœuds de stockage dédiés ne sont pas obligatoires. Sautez à la prochaine partie s’ils ne vous sont pas requis.
Les nœuds de stockage dédiés possèdent des taints Kubernetes, empêchant la planification habituelle de pods sur ces nœuds. Une taint est la combinaison d’une clé, d’une valeur et d’un effet, par exemple storage-node=true:NoSchedule. Pour permettre à Rook de planifier ses pods sur ces nœuds à taints, des tolérations doivent être données. En prenant la taint précédente, la toleration correspondante au format YAML est :
- key: "storage-node"
operator: "Equal"
value: "true"
effect: "NoSchedule"La tolération correspondant aux taints doit être insérée dans les champs suivants des fichiers de valeurs des charts :
operator-values.yaml:- Ajoutez la tolération dans le tableau d’objets
tolerations; - Ajoutez la tolération dans le champ
csi.provisionerTolerations; - Ajoutez la tolération dans le champ
discover.tolerationspour le processus de découvertes de Rook ; - Ajoutez la tolération dans le champ
admissionController.tolerations.
- Ajoutez la tolération dans le tableau d’objets
ceph-values.yaml:- Ajoutez la tolération dans le champ
cephClusterSpec.placement.all.tolerations.
- Ajoutez la tolération dans le champ
Ensuite, l’installation des charts avec les fichiers de valeurs mis à jour se fait comme vu précédemment.
Vérification de la santé de Rook avec le pod Toolbox
La vérification du fonctionnement du stockage objet Rook s’effectue en vérifiant l’état de santé de Ceph et en envoyant et récupérant un fichier dans le stockage. Le pod toolbox de Rook est équipé de l’outil en ligne de commande ceph, préconfiguré pour communiquer avec le cluster Ceph.
En utilisant le manifest de la toolbox du dépôt GitHub de Rook, la commande suivante créée le pod toolbox avant d’y accéder :
# Téléchargement du manifest
curl -fsSL -o toolbox.yaml https://raw.githubusercontent.com/rook/rook/master/deploy/examples/toolbox.yaml
# Déploiement du pod toolbox
kubectl create -f toolbox.yaml
# Attente du démarrage du pod
kubectl -n rook-ceph rollout status deploy/rook-ceph-tools
# Accès au pod toolbox en mode interactif
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bashVérifions la santé du cluster Ceph avec les commandes ceph status et ceph health detail :
HEALTH_OKest la valeur attendue ;HEALTH_WARNsignale des erreurs non-critiques :- Le clock skew est une erreur fréquente, réglée en synchronisant les horloges des nœuds du cluster avec des outils tels que Chrony.
HEALTH_ERRindique que le stockage objet est dans un état non utilisable.
Pour quitter le pod toolbox, utilisons exit. Ensuite, supprimons le pod :
kubectl delete -f toolbox.yamlEnvoi d’un fichier dans le stockage objet de Rook avec s5cmd
Après avoir vérifié la santé du cluster Ceph, l’étape suivante est le test d’écriture et de lecture dans le stockage objet. Le client S3 en ligne de commande s5cmd est utilisé pour communiquer avec le stockage objet par moyens externes. Il s’agit du moyen privilégié pour effectuer ces tests.
Téléchargeons l’archive du binaire de s5cmd et extrayons-le localement :
curl -fsSL -o s5cmd_2.0.0_Linux-64bit.tar.gz https://github.com/peak/s5cmd/releases/download/v2.0.0/s5cmd_2.0.0_Linux-64bit.tar.gz
# Téléchargement du checksum
curl -fsSL -o s5cmd_checksums.txt https://github.com/peak/s5cmd/releases/download/v2.0.0/s5cmd_checksums.txt
# Vérification du checksum avant extraction
grep 's5cmd_2.0.0_Linux-64bit.tar.gz' s5cmd_checksums.txt | sha256sum -c - && tar -xf s5cmd_2.0.0_Linux-64bit.tar.gzPour permettre à s5cmd d’interagir avec notre instance du stockage objet, de la configuration supplémentaire est requise depuis des variables d’environnement.
Tout particulièrement, le point d’accès du stockage objet doit être indiqué. Puisque le test se fait depuis un nœud du cluster et non dans un pod, un suivi de port sur le point d’accès nous permet d’y accéder temporairement.
Depuis une fenêtre de terminal séparée connectée au nœud maître, exécutons la commande suivante en utilisant le nom du service du stockage objet :
# Lancez ces commandes depuis une fenêtre de terminal séparée
# Pour l'installation par manifestes :
kubectl port-forward -n rook-ceph service/rook-ceph-rgw-my-store 8080:80
# Pour l'installation par Helm :
kubectl port-forward -n rook-ceph service/rook-ceph-rgw-ceph-objectstore 8080:80Le suivi de ports du service vers la machine du cluster permet de faire des tests simplement. En pratique, le point d’accès du service est directement accessible dans les pods, l’utiliser est la manière adaptée pour accéder au stockage objet depuis le cluster. Son nom de domaine est récupérable depuis la commande suivante :
kubectl get cm ceph-delete-bucket -o jsonpath='{.data.BUCKET_HOST}'
Préparons l’export des paramètres S3 depuis des requêtes à kubectl avec les commandes suivantes :
# L'addresse ci-dessous correspond à localhost, puisque le service est suivi sur le nœud actuel
export AWS_HOST=127.0.0.1
export PORT=8080
export BUCKET_NAME=$(kubectl -n default get cm ceph-delete-bucket -o jsonpath='{.data.BUCKET_NAME}')
export AWS_ACCESS_KEY_ID=$(kubectl -n default get secret ceph-delete-bucket -o jsonpath='{.data.AWS_ACCESS_KEY_ID}' | base64 --decode)
export AWS_SECRET_ACCESS_KEY=$(kubectl -n default get secret ceph-delete-bucket -o jsonpath='{.data.AWS_SECRET_ACCESS_KEY}' | base64 --decode)Créons un fichier d’identifiants S3 pour s5cmd utilisant les variables d’environnement venant d’être définies :
mkdir ~/.aws
cat > ~/.aws/credentials << EOF
[default]
aws_access_key_id = ${AWS_ACCESS_KEY_ID}
aws_secret_access_key = ${AWS_SECRET_ACCESS_KEY}
EOFs5cmd est maintenant prêt à être utilisé. Les commandes suivantes effectuent les tests en créant un fichier dans /tmp/ l’envoyant dans le stockage S3, le récupérant et affichant son contenu :
echo "This is the S3 storage test" > /tmp/myFile
./s5cmd --endpoint-url http://$AWS_HOST:$PORT cp /tmp/myFile s3://$BUCKET_NAME
./s5cmd --endpoint-url http://$AWS_HOST:$PORT cp s3://$BUCKET_NAME/myFile /tmp/myDownloadedFile
cat /tmp/myDownloadedFile
# Sortie attendue: This is the S3 storage testLa dernière commande affiche le contenu du fichier retéléchargé. Si celui-ci est identique au myFile original, le stockage objet S3 est alors prêt. Interrompons le suivi de ports depuis l’autre terminal en utilisant Ctrl+C.
Accéder au dashboard Rook
La dashboard de Rook fournit une interface web pratique pour gérer le cluster de stockage Ceph. Tout comme nous avons exposé temporairement le point d’accès du stockage objet plus tôt, nous allons procéder de la même manière pour accéder au dashboard depuis la machine hôte sur un navigateur web.
Depuis le cluster, récupérons tout d’abord les identifiants de la dashboard pour s’y connecter :
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echoLa console affiche alors le mot de passe du compte admin de la dashboard.
Suivons le port du service de la dashboard de manière à le rendre accessible depuis la machine hôte :
kubectl port-forward --address 0.0.0.0 -n rook-ceph service/rook-ceph-mgr-dashboard 8443:8443Ouvrons un navigateur web depuis la machine hôte en accédant à l’adresse du nœud du plan de contrôle en HTTPS au port 8443. Pour le cluster donné en exemple, l’adresse est https://192.168.56.10:8443. Une page d’identification est affichée après avoir accepté un éventuel risque de sécurité.

Utilisons le nom d’utilisateur admin en copiant le mot de passe affiché dans la console précédemment.
La dashboard est désormais accessible : il est possible de voir la santé du cluster, l’état actuel du stockage ainsi que plus de détail sur les trois types de stockage Ceph depuis les onglets de gauche.
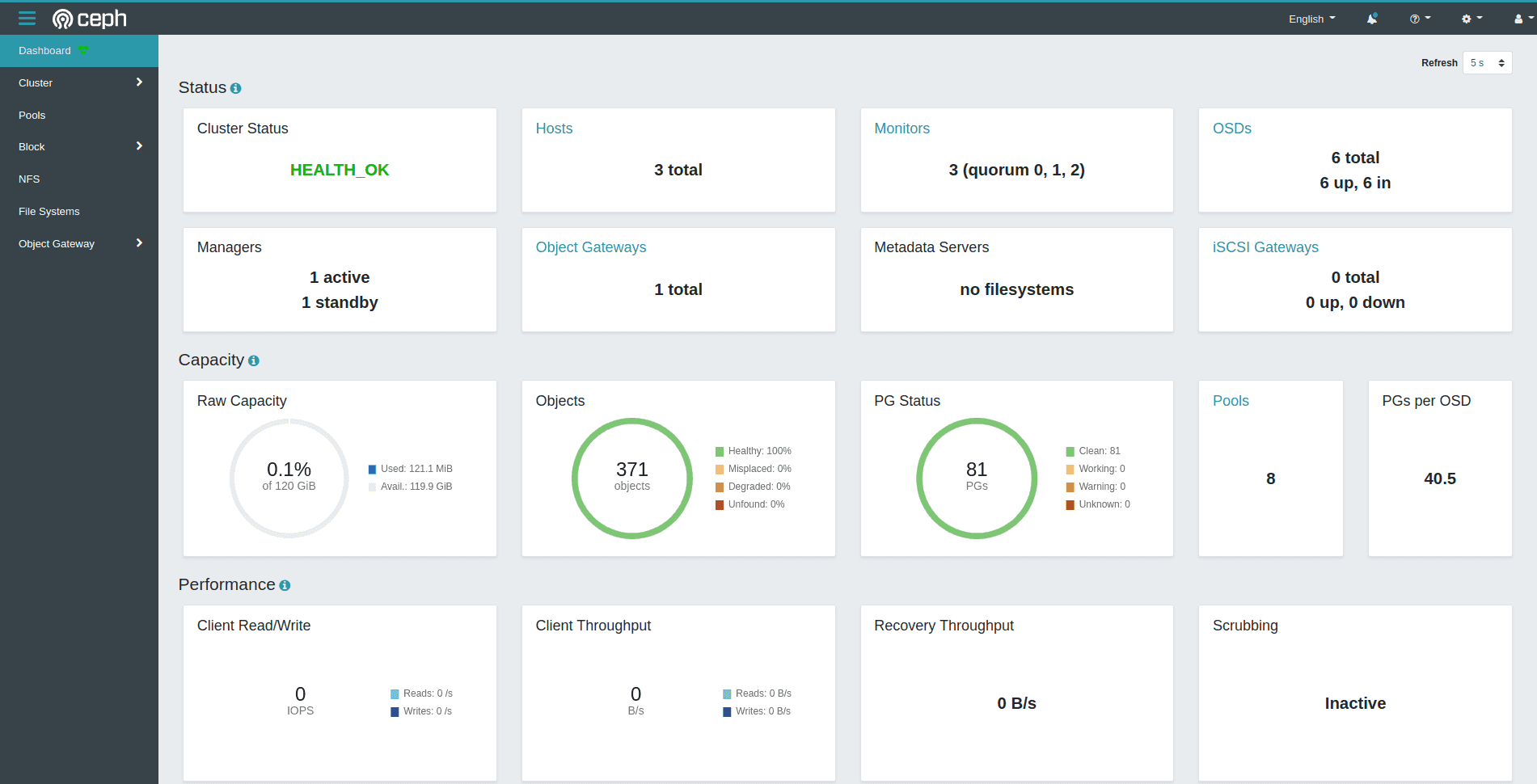
En dehors du développement et au lieu de faire du suivi de ports pour accéder au dashboard, les Ingress sont souvent utilisés quand un contrôleur Ingress et du load balancing sont disponibles pour le cluster.
Rook et MinIO, une autre solution de stockage objet dans Kubernetes
MinIO est une autre solution de stockage objet populaire pour les clusters Kubernetes. Il s’agit d’une alternative à Rook et propose différents bénéfices, sans pourtant fournir d’autres systèmes de stockage à la manière de Ceph.
Nous détaillons le déploiement de MinIO dans Kubernetes dans un autre article de cette série. Voici la comparaison des différences clés avec Rook :
Avantages de MinIO :
- MinIO est plus simple à déployer dans un cluster que Ceph en autonome, même si Rook aide grandement à simplifier ce process ;
- MinIO a plus d’outils à sa disposition pour rendre la consommation d’objets S3 aisée, avec les kits de développement dédiés à MinIO et un client MinIO compatible avec n’importe quelle solution de stockage objet.
Inconvénients de MinIO :
- Au niveau de la documentation, celle de MinIO n’est pas aussi claire que celle de Ceph ou de Rook, avec de nombreux détails manquants et une possible confusion générale ;
- La console de l’opérateur MinIO n’est pas parfaite et souffre de quelques bugs.
Conclusion
Utiliser Rook permet à la fois de couvrir les besoins de stockage objet et à la fois les besoins de systèmes de fichiers ou stockage bloc pour d’autres services et applications du cluster. De plus, son déploiement pour le tester se fait rapidement, comme montré avec ce tutoriel. Dans l’ensemble, Rook apporte la flexibilité du stockage Ceph aux clusters Kubernetes avec un déploiement facile et une gestion automatisée.
Les fonctionnalités avancées du stockage objet sont activées avec des configurations plus poussées. Ces fonctionnalités vont de l’exposition de la dashboard avec un Ingress à la réplication des pools de stockage sur différents sites.
