


Yahoo's Vespa Engine

Oct 16, 2017
- Categories
- Tech Radar
- Tags
- Database
- Tools
- Elasticsearch
- Search Engine
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Vespa is Yahoo’s fully autonomous and self-sufficient big data processing and serving engine. It aims at serving results of queries on huge amounts of data in real time. An example of this would be serving search results or recommendations to a user.
Yahoo - or Oath - recently made Vespa open source on GitHub. At this time, the documentation focuses on the user experience. Open sourcing the code will attract new developers, especially when it comes to its documentation, like it did with Apache Hadoop more than 10 years ago. Quoting Jon Bratseth, Distinguished Architect for Vespa,
By releasing Vespa, we are making it easy for anyone to build applications that can compute responses to user requests, over large datasets, at real time and at internet scale.
This article compiles some of my notes taken on a journey to better understand the nature of Vespa as well as my feedback and opinion after reading the documentation, trying a few examples and roaming the source code. I make sure to explain any technical vocabulary specific to Vespa, so if you see a word you don’t know, odds are it has a paragraph dedicated to it later on. Let’s see how Vespa lays the groundwork for building powerful and scalable search and recommendation applications.
What does Vespa do?
Vespa lets you:
- Select content using SQL-like queries and unstructured search
- Organize all matches to generate data-driven pages
- Rank matches by handwritten or machine-learned relevance models
- Write persistent data in real time thousands of times per second per node
- Grow, shrink and reconfigure clusters while serving and writing
Vespa is built on a core concept familiar to Hadoop users, to deploy and execute the code as close as possible to the data. Additionally, it provides access to processed data obtained from outside sources if required. Vespa applications can write, lookup, and query documents stored in the engine. They can also execute data dumps and handle outgoing network requests, such as exposing a custom HTTP REST services.
How does Vespa do it?
Vespa divides the nodes that are part of its system into three categories:
- The stateless container clusters host the system’s applications and most of its middleware.
- The content clusters store the system’s data and do most of its processing.
- The administration and configuration cluster rule over all the other components.
Vespa applications, built from component chains, are developed and hosted in JDisc containers. JDisc containers are the basis for the search container and document processing. These applications make use of Vespa’s elastic storage system.
The entire system is administered by a comprehensive Cloud Configuration System, a simple tool that grants Vespa users control over resource allocation.
Vespa is very minimalist in term of security, both external and internal, more details below.
How does Vespa actually work?
While Vespa’s capabilities are reported to be spectacular, how it accomplishes such speed and scalability remains unclear. After going through the project’s documentation, I have a good idea of how to use Vespa and what to use it for, but I cannot clearly visualize how it functions in the background. The most I’ve discovered is that the Vespa engine performs elaborate indexing of data and metadata in order to serve queries with very low latency.
Useful links
Available operations
Write: Add, replace, remove, or edit documents.
Lookup: Find a document or subset of documents with their IDs.
Query: Select documents whose fields match a boolean combination of conditions. The selection can be sorted, or ranked using a given ranking expression (math, business logic, or a machine-learned ranking model). The selection can also be grouped by field values, which can then be aggregated. To avoid needlessly shipping data back to the container cluster, any aggregation is done in a distributed fashion.
Data dump: Get any raw data that matches a given criterion.
Custom network request: Handled by application components deployed on content clusters.
Three-cluster architecture
Vespa divides its system into three cluster types: container clusters, content clusters, and an administration/configuration cluster.
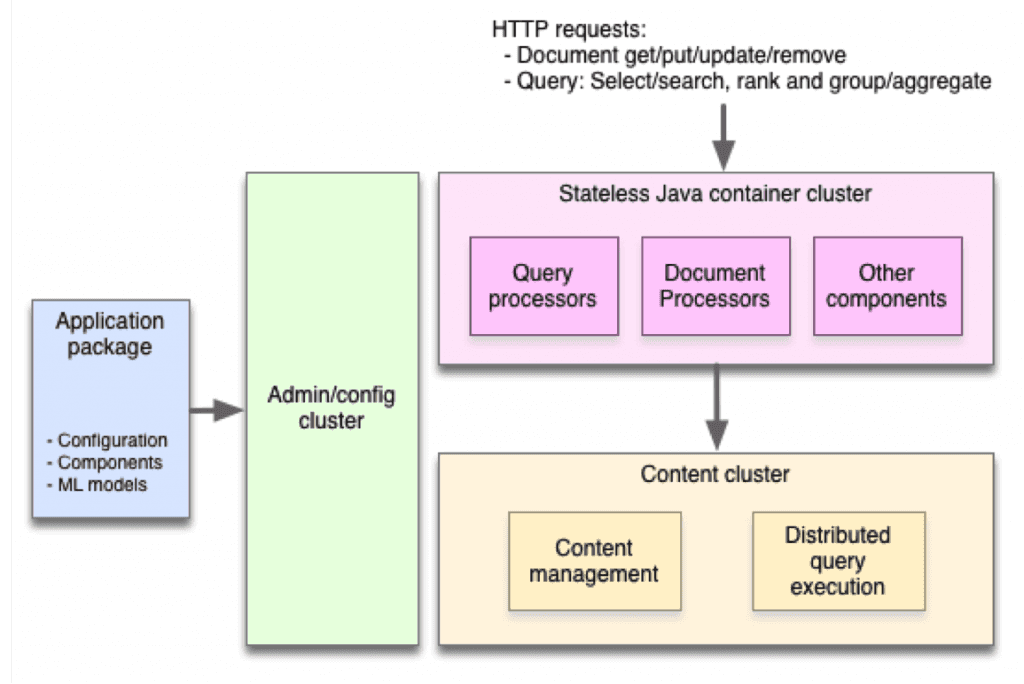
Stateless container clusters
Container clusters are stateless. They host the system’s application components and provide a network layer for handling and issuing remote requests, for which HTTP is readily available but other protocols can be plugged in.
Content clusters
Content clusters reliably store data by replicating it over multiple nodes; the number of copies is specified by the application. The clusters maintain distributed indices of data for searches and selects. These clusters can be grown or shrunk while online by editing the application package.
Lookups are routed directly to the correct node, however, queries spread out over the subset of nodes which contain the relevant documents. These queries use distributed algorithms with steps back and forth between container and content nodes, which allows for low-latency.
Administration and configuration cluster
There is only one such cluster because it controls the other clusters. It derives the low-level configuration required by each node of each other cluster, based on the high-level configuration given be the application developer.
Application packages can be changed, redeployed, or inspected through an HTTP REST API or through CLI commands. The process runs over Zookeeper, to ensure that changes to the configuration are singular and consistent while avoiding any single point of failure.
JDisc containers
On the container clusters, application components and plug-ins are stored in JDisc containers (Data Intensive Java Serving Container), also known as middleware containers (MWC). These are the basis of the Search Container and the Document Processing Container: search containers process queries and return results, while docproc containers return documents fed to them, after having processed them. This structure allows components to process or modify all queries, results, and documents.
JDisc containers provide a development and hosting environment for processing components, through an OSGi based component model which allows deployment and un-deployment of components to a cluster of running instances. They also provide a general model of Documents, Queries, Results, and the components processing them. Finally, they provide a composition mechanism - chains - for building applications from components and managing the execution order dependencies. This allows components to be developed by different teams.
Useful links
Component chains
Vespa uses the following application components: searchers, document processors, handlers, and renderers. Chained components are executed serially and each provides some service or transform.
Each component provides a list of services that should be before it in the chain (its dependants) as well as a list of services that should be after it in the chain (its dependencies). These ordering constraints define the execution order.
Fundamentally, a chain is simply a set of application components with dependencies.
Useful links
- http://docs.vespa.ai/documentation/chained-components.html
- http://docs.vespa.ai/documentation/searcher-development.html
- https://docs.vespa.ai/documentation/reference/services-docproc.html
- http://docs.vespa.ai/documentation/result-rendering.html
Data storage
Elasticity
Vespa stores application data in its content clusters. Which nodes to use for storage is specified in each application’s configuration. Applications can grow or shrink their hardware while serving queries and accepting writes as normal.
When such a change occurs, data is automatically redistributed in the background. Vespa applies minimal data movement required for even data distribution. No restarts are needed: all one needs to do is edit the hardware list in the application’s configuration and redeploy the app.
The same mechanism is used to adapt to faulty nodes or disks in the content clusters.
To date, Vespa is not optimised to function across multiple datacenters because their distribution algorithm is not suitable for global distribution as it does not attempt to minimize bandwidth usage between data centers, nor can it seamlessly tolerate datacenter-wide outages. Currently, a solution to this is to run an instance of Vespa in each data center and have applications write to all instances. Vespa’s development team realizes this is not ideal and is working on a solution.
Storage nodes
Storage nodes do the actual storing. They provide a Service Provider Interface (SPI) that abstracts how documents are stored in the elastic system. This interface is implemented by proton nodes, which make up Vespa’s search core.
Distributors
Whenever a Document is written to or read from the system it goes through a distributor. A distributor’s main role is to decide which bucket a document is stored in.
Buckets
In order to handle a large number of documents, Vespa groups them in buckets. These buckets are split and merged as they grow and shrink over time. The SPI links the elastic bucket system and the actual document storage. Buckets contain tombstones of recently removed documents, which are removed after a configurable amount of time.
Useful links
Cloud configuration
At first sight, Vespa’s Cloud Configuration System (CCS) system does not seem to be complicated.
We can divide configuration into three categories:
- Node system level configuration: set system time, user privileges, …
- Package management: ensure the correct software is installed on all nodes.
- Cloud configuration: start the configured set of processes on each node with their configured startup parameters and provide dynamic configuration to the modules run by these services. Configuration here is any data which cannot be fixed at compile time and is static most of the time.
Vespa relies almost exclusively on cloud configuration, so Vespa users can allow cloud nodes to have the same software packages because differences in behavior are managed entirely through the CCS. The complexity of node variations is thus managed through cloud configuration rather than on multiple systems.
Configuring the Vespa system is divided into assembly and delivery.
Configuration assembly is based on the application package, which is sent to the configuration server. A configuration model of the distributed system is assembled, accepting higher level abstractions as input and automatically deriving detailed configurations with the correct interdependencies. Once validated this configuration can be activated, which will update all relevant application configurations.
Configuration delivery queries the configuration model previously assembled to obtain the concrete configurations of the components of the system. Components subscribe to certain configurations and query the configuration server API before updating. Subscriptions are consecutive long-timeouts gets, which work in a manner comparable to push notifications.
Each node has a configuration proxy so that application components do not interact directly and redundantly with the configuration cluster.
CCS makes several assumptions about the nodes using it:
- All nodes have the software packages needed to run the configuration system and any services which will be configured to run on the node. This usually means that all the nodes have the same software, although this is not a requirement.
- All nodes have set
VESPA_CONFIGSERVERS, which defines the configuration servers to query. - All nodes know its fully qualified domain name.
It is unclear from its documentation how Vespa manages node resources when multiple apps attempt to use it. It seems that a “priority” system is in place, but I couldn’t find details on how it works or how to use it effectively.
Useful links
- http://docs.vespa.ai/documentation/cloudconfig/config-introduction.html
- http://docs.vespa.ai/documentation/cloudconfig/application-packages.html
Security
Content clusters
To say the least, content clusters security included in Vespa is light.
Vespa hosts be isolated from the internal and from your internal network, restrincting access to trusted network actors. All Vespa hosts must be able to communicate with each other. Keep in mind that all internal protocols are authenticated. It is the user responsibility to enforce network isolation. This can be accomplished with VLan, iptables, or AWS Security Groups, proxy servers, etc.
Inter-node communication is not encrypted which is a common practice emphasizing performances.
Container clusters
By default, application containers allow unauthenticated writes and reads to and from the Vespa installation. Custom authentication can be hooked up by leveraging request filters. but it isn’t clear if some mechanismes such as Kerberos or LDAP authentications are available on the shelf. Communications must be encrypted using SSL/TLS to secure the HTTP interface of the JDisc Container.
Additionnal notes
All Vespa processes run under the Linux user given by $VESPA_USER and store their data under $VESPA_HOME. You should ensure the files and directories under $VESPA_HOME are not accessible by other users if you store sensitive data in your application.
Vespa does not have support for encryption of on-disk document stores or indices. Opening the engine to the opensource community may provide additional security features.
Useful links
http://docs.vespa.ai/documentation/securing-your-vespa-installation.html
Personal opinion
In its current state, the documentation, is inconsistent in quality. It cover in detailed the end user experience on how it should be used but does too little from an infrastructure viewpoint to explain how the system works.
In my humble opinion, Vespa is huge. It seems to do a lot and to do it well. That being said, it isn’t ready yet to compete with well-established multi-users / multi-tenant systems like Hadoop for big data processing or Kubernetes for containers orchestration. Vespa gives off a plug-n-play vibe. This is tempting and I wish I had more time at my disposal for tweaking it for specific goals and see how powerful and easy/complicated it get.
