


Comparison of different file formats in Big Data

By Aida NGOM
Jul 23, 2020
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
In data processing, there are different types of files formats to store your data sets. Each format has its own pros and cons depending upon the use cases and exists to serve one or several purposes. It is important to know and leverage their specificities when choosing a specific format type.
Some formats are more relevant for certain usages or treatments, such as in Business Intelligence, network communication, web application, batch or stream processing. For instance, CSV format is very understandably and, while everyone critics its lack of formalism, it is still widely used. In case of web communication, JSON is privileged and cover most of the world communication even if, in some cases, XML might do the same work. The latest format benefit from a large ecosystem of tools and is widely used in the enterprise world. In terms of streaming processing, AVRO and Protocol Buffers are a privileged formats. In addition, protocol buffers is the foundation of gRPC (RPC stands for Remote Procedure Call) on which rely the Kubernetes ecosystem. Finally, column storage offered by ORC and Parquet provide a significant performance boost in data analytics.
Consideration to be taken into account for choosing a file format
The most popular and representative file formats are described with the various considerations to keep in mind when choosing one format over another one. But first, let’s review their main characteristics in regards to storage, queries types, batch versus streaming usages, …
Text versus binary
Text based file formats are easier to use. They can be read by the end user who can also modify the file content with a text editor. Those formats are usually compressed to reduce their storage footprints. Binary file formats require a tool or a library to be created and consumed but they provides better performance by optimizing the data serialization.
Data type
Some format don’t allow to declare multipe types of data. Types are classified in 2 categories. Scalar types holds a “single” value (eg integer, boolean, string, null, …). Complex types are a compound of scalar types (eg arrays, objects, …). Declaring the type of a value provides some advantages. The consumer can distinguish for example a number from a string or a null value from the string “null”. Once encoded in binary form, the storage gain is significant. For example, the string "1234" uses 4 bytes of storage while the boolean 1234 requires only 2 bytes.
Schema enforcement
The schema can be associated with the data or left to the consumer who is assumed to know and understand how to interpret the data. It can be provided with the data or separately. The usage of a schema garanties that the dataset is valid and provide extra information such as the type and the format of a value. Schemas are also used in binary file formats to encrypt and decrypt the content.
Support Schema evolution
The schema store the definition of each attribute and its types. Unless your data is guaranteed to never change (e.g. of archives) or is by nature immutable (e.g. of logs), you’ll need to think about schema evolution in order to figure out if your data schema changes over time. In other words, schema evolution allows to update the schema used to write new data while maintaining backwards compatibility with the schema of your old data.
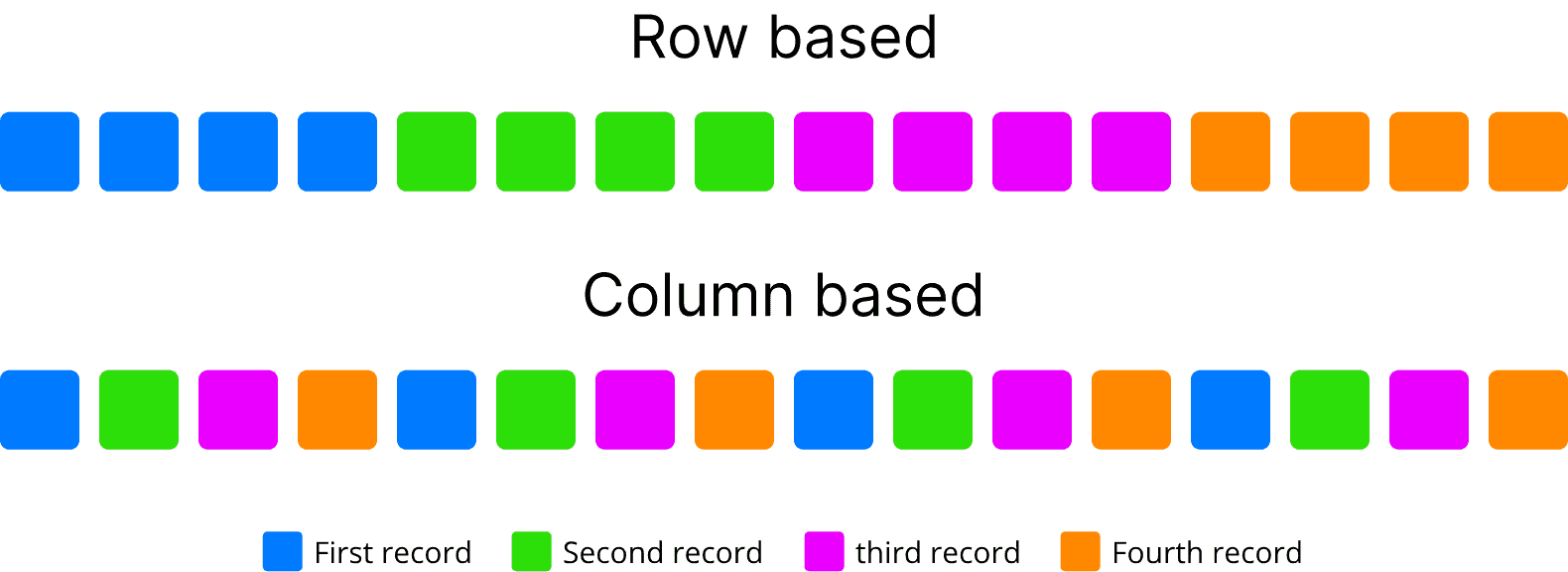
Row and column storage, OLTP versus OLAP
In row based storage, data is stored row by row, such that the first column of row will be next to the last column of the previous row. This architecture is appropriated to add data easily and quickly. It’s also suitable in case where the entire row of data needs to be accessed or processed simultaneously. This is commonly used for Online Transactional Processing (OLTP). OLTP systems usually process CRUD queries (Read, Insert, Update and Delete) at a record level. OLTP transactions are usually very specific in the task they perform, and usually involve a single record or a small selection of records. The main emphasis for OLTP systems is focus on maintaining data integrity in multi-access environments and an effectiveness measured by number of transactions per second.
Inversely, in column-based storage, data is stored such that each row of a column will be next to other rows from that same column. That is most useful when performing analytics queries which require only a subset of columns examined over very large data sets. This way of processing data is usually called OLAP (OnLine Analytical Processing) query. OLAP is an approach designed to quickly answer analytics queries involving multiple dimensions. This approach has played a critical role in business intelligence analytics, especially regarding to Big Data. Storing data in column avoid the excessive processing times of reading irrelevant information across a data set by ignoring all the data that doesn’t apply to a particular query. It also provides a greater compression ratio by aligning data of a same type and optimizing null values of sparse columns.
Here is an example if you wanted to know the average population density in cities with more than a million people. With a row-oriented storage and, your query would access each record in the table (meaning all of its fields) to get the necessary information from the three relevant columns city name, density and population. That would involve a lot of unnecessary disk seeks and disk reads, which impact performance. Columnar databases performs better by reducing the amount of data that needs to be read from disk.
Example grouping records by color
Example grouping properties by color
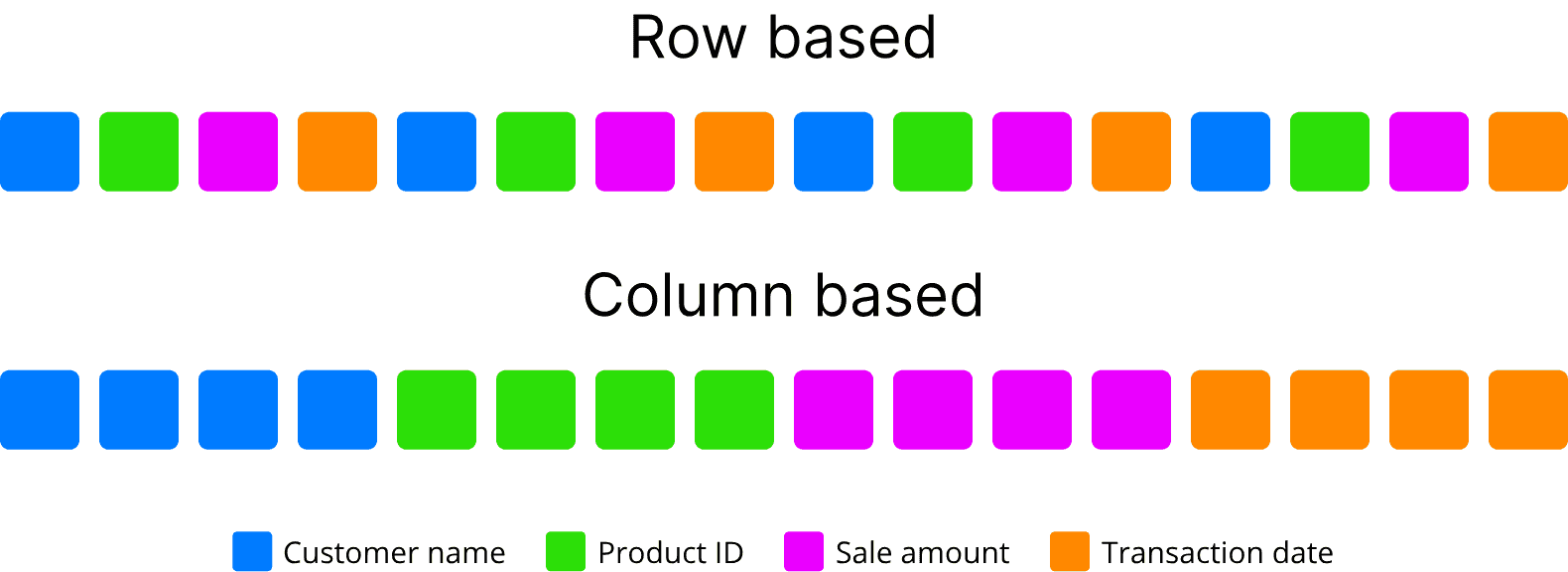
Splittable
In a distributed file system like Hadoop HDFS, it is important to have a file that can be divided into several pieces. In Hadoop, the HDFS file system stores data in chunk and the data processing is initially distributed according to those chunks. To be able to begin reading data at any point within a file is helpful in order to take the full advantages of Hadoop’s distributed processing. When the file format is not splittable, it is the user’s responsibility to partitioned his data into several files to enable the parallelism.
Compression (Bzip2, LZO, Sappy,…)
A system is a slow as its slowest components and, most of the time, the slowest components are the disks. Using compression reduce the size of the data set being stored and thereby reduce the amount of read IO to perform. It also speeds up file transfers over the network. Column based storage brings higher compression ration and better performance compared to row based storage because similar pieces of data are stored together. As mention earlier, it is particularly effective on sparse columns which contains several null values.
In addition, compression mostly applies to text file formats unless the binary file format includes compression in its definition. Attempting to compress a binary file often lead to heavier generated file compare to its original. Also, when comparing compression ratio, we must also put into perspective the original file size. It wouldn’t be fair to compare the compression ratio of JSON versus XML if we don’t take into consideration that the XML is originally larger than its JSON counterpart.
There are many kinds of compression algorithms which differ according of the ratio of compression, speed, performance, splittable, …
Batch and Streaming
Batch processing reads, analyses and transform multiple records at once. In opposition, stream processing works in real time and process records as they arrive. Sometimes, a same data set may be processed both in streaming and in batch. Let’s consider financial transactions received inside a system. The data arrive in Streaming and could be processed instantly to detect fraud detection. Complementary, once the data is stored, a job could run periodically in batch to prepare some reports. In such case, we might rely on one or two file formats between the format of the data arriving over the wire and the format of the data being stored in our Data Warehouse or Data Lake.
Ecosystem
It is often considered a good practice to respect the usage and the culture of an ecosystem when it comes to choose between multiple alternative. For example, when choosing between Parquet or ORC with Hive, it is recommended to use the former on Cloudera platforms and the latter on Hortonworks platforms. Chances are that the integration will be smoother and the documentation and support from the community much helpful.
Popular File formats
CSV
CSV is a text format which uses a newline as a record delimiter with an optional header. It is easy to edit manually and very understandably by human perspective. CSV doesn’t support schema evolution even though sometimes the header is optionally considered as the schema of the data. In its complex form, it’s not splittable because it doesn’t contain a specific character where you could based on to split the text while remaining relevant.
Generally in Big Data, CSV seems to be used for processing but, strictly speaking, it is closer to the TSV format. The differences between the two format are subtle.
CSV format is not a fully standardized format. Its field delimiters could be, for example, colon or semicolons. It becomes difficult to parse when the field itself may also contain these kind of quotes or even embedded line breaks. In addition, the field data could be enclosed by a quotation marks. These quotes raise sometimes irrelevant structure of data about the identification of the beginning or ending of sentences or even a null value. Unlike TSV, CSV embodies an escape character (\) into its data. Thus, all those various considerations make it complex for parsing. Whereas, TSV being generally delimited either by tabulation or a comma, it doesn’t support an escape character. This allows to distinguish easily each field and eventually help to parse easily than CSV. This is the reason why it is mainly used in big data case.
- Advantage
- Excellent compression ratio
- Easy reading
- Supports batch and streaming processing
- Drawback
- No support a null values, identical to empty values
- No garantie to be splittable and no schema evolution support
- Non standard format, everyone with its own interpretations
- Ecosystems
- Supported by a wide range of applications (Hadoop, Spark, kafka,…) and languages (for example CSV for Node.js)
- One of the most popular formats used because of its simplicity, but usually not recommanded
Example of CSV format
Player Name;Position;Nicknames;Years Active
Skippy Peterson;First Base;"""Blue Dog"", ""The Magician""";1908-1913
Bud Grimsby;Center Field;"""The Reaper"", ""Longneck""";1910-1917
Vic Crumb;Shortstop;"""Fat Vic"", ""Icy Hot""";1911-1912JSON (JavaScript object notation)
JSON is a text format containing a record which might be in several forms (string, integer, booleans, array, object, key-value, nested data…). Being human and machine readable, JSON is a relatively lightweight format and privileged in web applications. It widely supported by many software and comparatively simple to implement in multiple languages. JSON natively supports serialization and deserialization process.
Its major inconvenience is related to not being splittable. The alternative used format in this case is generally a JSON lines. This one contains several lines where each individual line is a valid JSON object, separated by newline character \n. Because JSON garanti de absence of newline characters in the data being serialized, we can use the presence of those characters to split the datasets into multiple chunks.
- Advantage
- JSON is a simple syntax. It can be opened by any text editor
- There are many tools available to validate the schema
- JSON is compressible and used as data exchange format
- It supports batch and streaming processing
- It stores metadata with data and supports schema evolution
- JSON is lightweight text-based format in comparison to XML
- Drawback
- JSON is not splittable and lack indexing as many text formats
- Ecosystems
- It is privileged format for web applications
- JSON is a widely used file format for NoSQL databases such as MongoDB, Couchbase and Azure Cosmos DB. or example,in MongoDB, BSON is used instead the standard format. This rchitecture of MongoDB is easier to modify than structured database as Postgres where you’d need to extract the whole document for changing. ndeed, BSON is the binary encoding of JSON-like documents. It’s indexed and allows to be parsed much ore quickly than standard JSON. However, this doesn’t mean you can’t think of MongoDB as a JSON atabase.
- JSON is also an used language in GraphQL on which rely a data fully typed. GraphQL is a query language for an API. Instead of working with rigid server-defined endpoints, you can send queries to get exactly the data you are looking for in one request.
Example showing respectively a JSON format and a JSON Lines format
{
"fruits": [{
"kiwis": 3,
"mangues": 4,
"pommes": null
},
{
"panier": true
}],
"legumes": {
"patates": "amandine",
"poireaux": false
},
"viandes": [
"poisson","poulet","boeuf"
]
}{"id":1,"father":"Mark","mother":"Charlotte","children":["Tom"]}
{"id":2,"father":"John","mother":"Ann","children":["Jessika","Antony","Jack"]}
{"id":3,"father":"Bob","mother":"Monika","children":["Jerry","Karol"]}XML
XML is a markup language created by W3C to define a syntax for encoding documents which are both humans and machines readable. XML allows to define more and less complexes languages. It also enables to establish a standards file format for exchange between applications.
Like JSON, XML is also used to serialize and encapsulate data. Its syntax is verbose, especially for human readers, relative to other alternatives ‘text-based’ formats.
- Advantage
- Supports batch/streaming processing.
- Stores meta data along the data and supports the schema evolution.
- Being a verbose format, It provides a good ratio of compression compare to JSON file or other text file format.
- Drawback
- Not splittable since XML has an opening tag at the beginning and a closing tag at the end. You cannot start processing at any point in the middle of those tags.
- The redundant nature of the syntax causes higher storage and transportation cost when the volume of data is large.
- XML namespaces are problematic to use. The support of namespace can be difficult to correctly implement in an XML parser.
- Difficulties to parse requiring the selection and the usage of an appropriate DOM or SAX parser.
- Ecosystems
- Large historical presence in companies which tends to decrease over time.
Example of XML
<?xml version="1.0" encoding="UTF-8"?>
<scientists>
<!-- Some important physicists -->
<scientist id="phys0">
<name firtname="Galileo" lastname="Galilei" />
<dates birth="1564-02-15" death="1642-01-08" />
<contributions>Relativity of movement & heliocentric system</contributions>
</scientist>
</scientists>AVRO
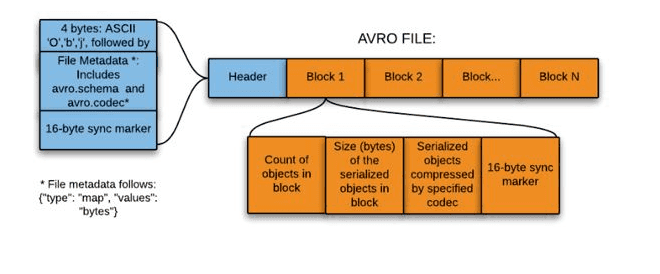
Avro is framework developed within Apache’s Hadoop project. It is a row-based storage format which is widely used as a serialization process. AVRO stores its schema in JSON format making it easy to read and interpret by any program. The data itself is stored in binary format by doing it compact and efficient. A key feature of AVRO is related to the fact that it can easily handle schema evolution. It attach metadata into their data in each record.
- Advantage
- Avro is a data serialization system.
- It is splittable (AVRO has a sync marker to separate the block) and compressible.
- Avro is good file format for data exchange. It has a data storage which is very compact, fast and eficient for analytics.
- It highly supports schema evolution (at different time and independently).
- It supports batch and is very relevant for streaming.
- Avro schemas defined in JSON, easy to read and parse.
- The data is always accompanied by schema, which allow full processing on the data.
- Drawback
- Its data is not readable by human.
- Not integrated to every languages.
- Ecosystems
- Widely used in many application (Kafka, Spark, … ).
- Avro is a remote procedure call (RPC).
Protocol Buffers
Protocol buffers has been developed by Google and open sourced in 2008. It is language-neutral, an extensible way of serializing structured data. It’s used in communications protocols, data storage, and more. It is easy to read and understandably by human. Unlike Avro, the schema is required to interpret the data
- Advantage
- Data is fully typed.
- Protobuf supports schema evolution and batch/streaming processing.
- Mainly used to serialize data, like AVRO.
- Having a predefined and larger set of data types, messages serialized on Protobuf can be automatically validated by the code that is responsible to exchange them.
- Drawback
- Not splittable and not compressible.
- No Map Reduce support.
- Require a reference file with the schema.
- Not designed to handle large messages. Since it doesn’t support random access, you’ll have to read the whole file, even if you only want to access a specific item.
- Ecosystems
- Tools are available on most programming languages around, like JavaScript, Java, PHP, C#, Ruby, Objective C, Python, C++ and Go.
- Foundation of gRPC widely used accross the kubernetes ecosystem.
- ProfaneDB is a database for Protocol Buffers objects.
Here is an schema example:
syntax = "proto3";
message dog {
required string name = 1;
int32 weight = 2;
repeated string toys = 4;
}Parquet
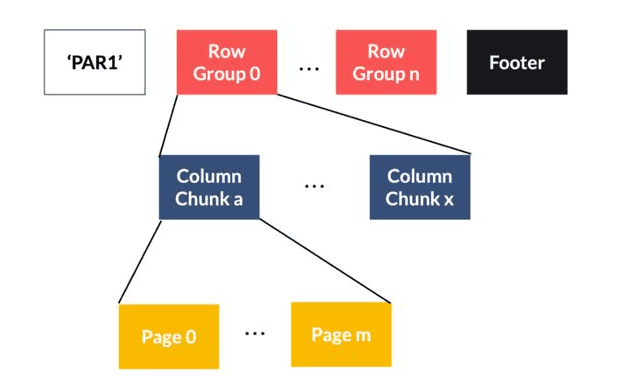
Parquet is an open source file format for Hadoop ecosystem. Its design is a combined effort between Twitter and Cloudera for an efficient data storage of analytics. Parquet stores data by column-oriented like ORC format. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. Parquet is a binary file containing metadata about their content. The column metadata is stored at the end of the file, which allows for fast, one-pass writing. Parquet is optimized for the paradigm of write once read many (WORM).
- Advantage
- Splittable files.
- Organizing by column, allowing a better compression, as data is more homogeneous.
- High efficiency for OLAP workload.
- Supports schema evolution.
- Restricted to batch processing.
- Drawback
- Not human readable.
- Difficulties to apply updates unless you delete and recreate it again.
- Ecosystems
- Eficient analysis for BI (Business Intelligence).
- Very fast to read for processing engines such as Spark.
- Commonly used along with Spark, Impala, Arrow and Drill.
Structure of Parquet format
ORC (Optimized Row Columnar)
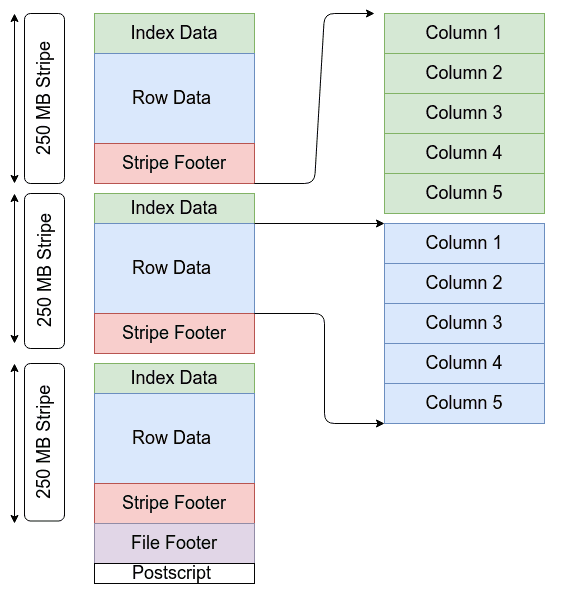
ORC format was created and open sourced by Hortonworks in collaboration with Facebook. It is a column-oriented data storage format similar to Parquet. ORC files contain groups of row data called stripes, along with auxiliary information in a file footer. At the end of the file, a postscript holds compression parameters and the size of the compressed footer. The default stripe size is 250 MB. Large stripe sizes enable large efficient reads from HDFS.
- Advantage
- Highly compressible, reducing the size of the original data up to 75%.
- More efficient for OLAP than OLTP queries.
- Restricted to batch processing.
- Drawback
- Unable to add data without having to recreate the file.
- Does not support schema evolution.
- Impala currently does nt support ORC format.
- Ecosystems
- Efficient analysis for Business Intelligence workload.
- ORC improves performance reading, writing, and processing in Hive.
Structure of ORC format
Conclusion
The selection of an appropriate file format is related to the kind of query (use cases) tied to the properties of each file format. Usually, row-oriented databases are well-suited for OLTP-like workloads whereas column-oriented systems is well suited of OLAP query. Since its column storage type contains a uniform type in each column, columnar format will be better in compression compared to a row based storage.
In term of comparison, if you wish to work with a text format, JSON line and eventually CSV when you control the data types (no text with special characters) are good choices. Unless the data source impose it, avoid selecting XML. It is practically not used in data processing because of its high complexity often requiring a custom parser. In stream processing and data exchange, if you wish a flexible and powerfull format, select Avro. It also provide great support for schema evolution. While Protocol Buffers is efficient in streaming workload, it is not splittable and not compressible which makes it less attractive for storing data at rest. Finally, the ORC and parquet formats are optimized for Business Intelligence analytics.
In summary, the main consideration to bear in mind is that selecting a file format depends on the use cases.
Overview
| Types | CSV | JSON | XML | AVRO | Protocol Buffers | Parquet | ORC |
|---|---|---|---|---|---|---|---|
| text versus binary | text | text | text | metadata in JSON, data in binary | text | binary | binary |
| Data type | no | yes | no | yes | yes | yes | yes |
| Schema enforcement | no (minimal with header) | external for validation | external for validation | yes | yes | yes | yes |
| Schema evolution | no | yes | yes | yes | no | yes | no |
| Storage type | row | row | row | row | row | column | column |
| OLAP/OLTP | OLTP | OLTP | OLTP | OLTP | OLTP | OLAP | OLAP |
| Splittable | yes in its simpliest form | yes with JSON lines | no | yes | no | yes | yes |
| Compression | yes | yes | yes | yes | yes | yes | yes |
| Batch | yes | yes | yes | yes | yes | yes | yes |
| Stream | yes | yes | no | yes | yes | no | no |
| Typed data | no | no | no | no | yes | no | no |
| Ecosystems | popular everywhere for its simplicity | API and web | enterprise | Big Data and Streaming | RPC and Kubernetes | Big Data and BI | Big Data and BI |
